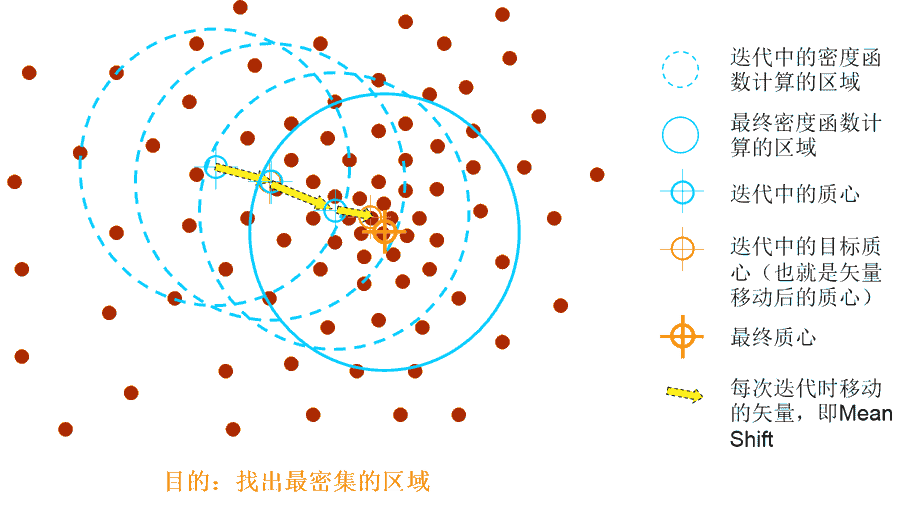
[K-Means算法]是常用的聚类算法,但其算法本身存在一定的问题,例如在大数据量下的计算时间过长就是一个重要问题。为此,Mini BatchK-Means,这个基于K-Means的变种聚类算法应运而生。 大数据量是什么量级?通过当样本量大于1万做聚类时,就需要考虑选用Mini Batch K-Means算法。但是,在选择算法时,除了算法效率(运行时间)外,算法运行的准确度也是选择算法的重要因素。Mini Batch
K-Means算法的准确度如何?
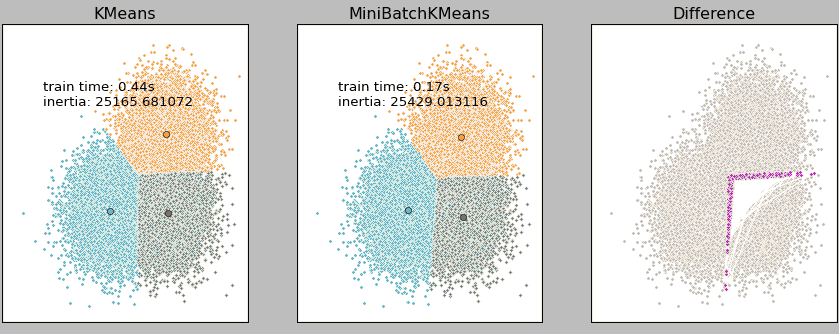
上图是我们队3万的样本点分别使用K-Means和Mini Batch KMeans进行聚类的结果,由结果可知,在3万样本点的基础上,二者