大多数数据挖掘或数据工作中,异常值都会在数据的预处理过程中被认为是“噪音”而剔除,以避免其对总体数据评估和分析挖掘的影响。但某些情况下,如果数据工作的目标就是围绕异常值,那么这些异常值会成为数据工作的焦点。
数据集中的异常数据通常被成为异常点、离群点或孤立点等,典型特征是这些数据的特征或规则与大多数数据不一致,呈现出“异常”的特点,而检测这些数据的方法被称为异常检测。
“噪音”的出现有多种原因,例如业务操作的影响(典型案例如网站广告费用增加10倍,导致流量激增)、数据采集问题(典型案例如数据缺失、不全、溢出、格式匹配等问题)、数据同步问题(异构数据库同步过程中的丢失、连接错误等导致的数据异常),而对离群点进行挖掘分析之前,需要从中区分出真正的“离群数据”,而非“垃圾数据”。
常用的异常检测方法可分为以下几类:
基于统计的异常检测方法。该方法的基本步骤是对数据点进行建模,再以假定的模型(如泊松分布、正太分布等)根据点的分布来确定是否异常。这种方法首先需要对数据的分布有所了解,进而通过数据变异指标来发现异常数据。常用变异指标有极差、四分位数间距、均差、标准差、变异系数等。但是,基于统计的方法检测出来的异常点产生机制可能不唯一,而且它在很大程度上依赖于待挖掘的数据集是否满足某种概率分布模型,另外模型的参数、离群点的数目等都非常重要,确定这些因素通常都比较困难。因此,实际情况中算法的应用性和可移植性较差。
基于距离的异常检测方法。该方法定义包含并拓展了基于统计的思想,即使数据集不满足任何特定分布模型,它仍能有效地发现离群点,特别是当空间维数比较高时,算法的效率比基于密度的方法要高得多。算法具体实现时,首先给出记录数据点间的距离(如 曼哈顿距离 、欧氏距离等),然后对数据进行一定的预处理以后就可以根据距离的定义来检测异常值。如基于K-Means的聚类可以将离每个类中心点最远或者不属于任何一个类的数据点提取出来而发现异常值。基于距离的离群检测方法不需要用户拥有任何领域知识且具有比较直观的意义,算法比较容易理解,因此在实际中应用得比较多。
基于密度的离群检测方法。这种方法一般都建立在距离的基础上,其主要思想是将数据点之间的距离和某一范围内数据数这两个参数结合起来,从而得到“密度”的概念,然后根据密度判定记录是否为离群点。例如LOF(局部异常因子)就是用于识别基于密度的局部异常值的算法。离群点被定义为相对于全局的局部离群点,这与传统异常点的定义不同,异常点不再是一个二值属性(要么是异常点,要么是正常点,实际上的定义类似于98%的可能性是一个异常点),它摈弃了以前所有的异常定义中非此即彼的绝对异常观念,更加符合现实生活中的应用;但其缺点就是它只对数值数据有效。
基于偏移的异常点检测方法。基于偏移的离群检测算法 (Deviation-based Outlier Detection)
通过对测试数据集主要特征的检验来发现离群点。目前,基于偏移的检测算法大多都停留在理论研究上,实际应用比较少。
基于时间序列的异常点监测方法。所谓时间序列就是将某一指标在不同时间上的数值,按照时间先后顺序排序而成的数列。这种数列虽然由于受到各种偶然因素的影响而表现出某种随机性,不可能完全准确地用历史值来预测将来,但是前后时刻的数值或数据点的相关性往往呈现某种趋势性或周期性变化,这是时间序列挖掘的可行性之所在。时间序列中没有具体描述被研究现象与其影响因素之间的关系,而是把各影响因素分别看作一种作用力,被研究对象的时间序列则看成合力;然后按作用特点和影响效果将影响因素规为4 类,即趋势变动( T )、季节变动( S )、循环变动( C )和随机变动( I)。这四种类项的变动叠加在一起,形成了实际观测到的时间序列,因而可以通过对这四种变动形式的考察来研究时间系列的变动。目前国际和国内对时间序列相似度的研究提出了许多种解决方法,这些方法主要包括基于直接距离、傅立叶变换、ARMA 模型参数法、规范变换、时间弯曲模型、界标模型、神经网络、小波变换、规则推导等。
异常检测根据原始数据集的不同可分为两类:
- 新奇检测(Novelty Detection):新奇检测的前提是已知训练数据集是“纯净”的,未被真正的“噪音”数据或真实的“离群点”污染,然后针对这些数据训练完成之后再对新的数据进行训练以寻找异常数据。
- 离群点检测(Outlier Detection):离群点检测的训练数据集则包含“离群点”数据,对这些数据训练完成之后再在新的数据集中寻找异常数据。
本文所讲的是新奇检测,通过Python的sklearn实现,应用算法one-class SVM(一类SVM,总觉得这个翻译很怪),one-class SVM用于新奇检测
它的基本原理是在给定的一组样本中,检测数据集的边界以便于区分新的数据点是否属于该类。它是基于密度检测方法的一种,属于无监督学习算法,拟合过程由于不存在数据类标签,因此只需要输入一个矩阵X即可。
#coding:utf-8
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.font_manager
from sklearn import svm
xx, yy = np.meshgrid(np.linspace(-5, 5, 500), np.linspace(-5, 5, 500))
# 生成训练数据
X = 0.3 * np.random.randn(100, 2)
X_train = np.r_[X+2, X-2]
# 生成新用于测试的数据
X = 0.3 * np.random.randn(10, 2)
X_test = np.r_[X + 2, X - 2]
# 模型拟合
clf = svm.OneClassSVM(nu=0.1, kernel="rbf", gamma=0.1)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
print ("novelty detection result:",y_pred_test)
n_error_train = y_pred_train[y_pred_train == -1].size
n_error_test = y_pred_test[y_pred_test == -1].size
# 在平面中绘制点、线和距离平面最近的向量
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.title("Novelty Detection")
plt.contourf(xx, yy, Z, levels=np.linspace(Z.min(), 0, 7), cmap=plt.cm.Blues_r)
a = plt.contour(xx, yy, Z, levels=[0], linewidths=2, colors="red")
plt.contourf(xx, yy, Z, levels=[0, Z.max()], colors="orange")
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c="white")
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c="green")
plt.axis("tight")
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.legend([a.collections[0], b1, b2],
["learned frontier", "training observations",
"new observations", ],
loc="upper left",
prop=matplotlib.font_manager.FontProperties(size=11))
plt.xlabel(
"error train: %d/200 ; errors novel regular: %d/40 ; "
% (n_error_train, n_error_test,))
plt.show()
运算结果如下: `
("novelty detection result:", array([ 1., 1., 1., -1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]))
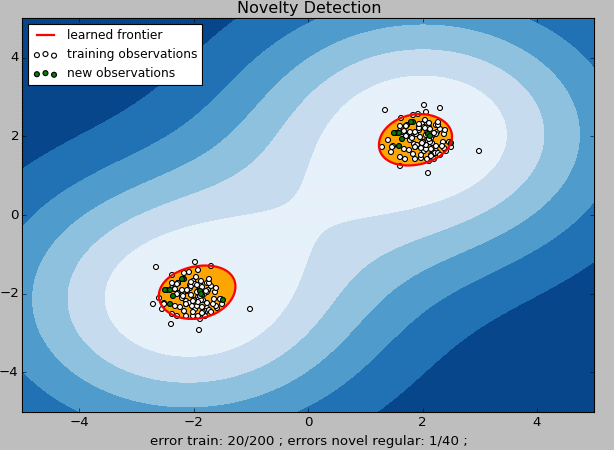
上图中,白色点表示训练数据,绿色点表示测试数据,黄色区域表示“正常数据”区域,红色线表示“正常数据”和“异常数据”的边界。
从模型的输出代码结果可以看到,其中值为-1的数据以及从图中直观的看到绿色标记点(新的观测点)中在红色线条之外的即为“新奇数据”。这些数据就可以被单独拿出来做更进一步的分析或触发相应的业务动作及流程。
在这个案例中,我们使用的one-class SVM的拟合效果不是特别好。我们可以看到,对原始训练数据进行训练并采用相同的数据进行新奇检测后,错误的样本量达到10%(图中error train:20/200——这里我们已经假设原有的数据都是干净的,因此不应该存在异常数据的预测结果)。模型中,有很多参数需要不断调整和组合才能达到较高的数据预测准确性,模型的组合调优是算法的核心,可以结合模型中的支持向量值、决策函数中的支持向量系数、常量等进行调整。如果选择线性内核(kernel='linear'),还可以查看每个特征的权重值。
其中可调整的参数如下:`
class sklearn.svm.OneClassSVM(kernel='rbf', degree=3, gamma=0.0, coef0=0.0, tol=0.001, nu=0.5, shrinking=True, cache_size=200, verbose=False, max_iter=-1, random_state=None)
新奇检测的应用场景包括:
- 客户异常识别
- 信用卡欺诈
- 贷款审批识别
- 药物变异识别
- 恶劣气象预测
- 网络入侵检测
- 流量作弊
尾巴
one-class SVM属于SVM的一种,可用于高维数据的异常检测,其基于libsvm。one-class SVM提供了linear、poly、rbf、sigmoid和precomputed可供使用,甚至你可以自定义一个内核算法来调用。one-class SVM本质上还是一种分类,但这种分类与传统的“分类”意义不同,one-class SVM的分类是将数据分为“正常数据”和“异常数据”(用+1和-1表示),而传统的分类是将正常数据按照不同的特征分为几个不同的类别。