- 1.问题:对于一维数据而言,reshape之后仍然是一维,为什么还要做reshape操作?
- 2.问题:我看书里面好像很多图的原图应该是彩色的,但是印刷确实黑白的,有些图看不清楚啊
- 3.问题:这本书基本都能会的话,在数据分析中属于什么段位水准呢?
- 4.问题:为什么我下载的附件压缩包不可用或提示错误?
- 5.问题:书里面有没有类似R里面的auto.arima的实现逻辑?自动寻找最优的P、D、Q的方法?
- 6.问题:问题:在P66的PIL章节中,为什么没有使用from PIL import Image,而是直接使用的import Image?
- 7.问题:为什么“2.2.3 从关系型数据库MySQL读取运营数据”章节中使用MySQL导入Excel数据只有357条记录
- 8.问题:在P170“相关知识点:scatter和plot方法”中关于线条样式的有2个点虚线,二者有什么区别?
- 9.问题:我已经安装了Image库,为什么我在电脑上直接Image却无法导入?
- 10.问题:为什么我的电脑上无法通过pip命令安装PIL?
- 11.问题:为什么我在对数据框使用sort方法排序时,会出现错误?
- 12.问题:为什么我使用Matplotlib无法展示图形,但将其保存到本地却可以看到图形?
- 13.问题:在P149 中,书的最下边‘for i in xrange(4)’应该改成‘for in in range(4)’?
- 14.问题:在第一章的代码中,在预测应用时,提示报错,需要使用reshape方法转换形状?
在这边文章中,我会把读者反馈给我的常见问题总结出来,供更多读者参考。里面会涉及到各种疑问或混淆知识点,希望能给大家解惑。如果大家有什么疑问,可以直接在这里留言,我会将一些跟本书相关的知识性问题总结出来并在此回答。
最近更新时间:2021-07-05
1.问题:对于一维数据而言,reshape之后仍然是一维,为什么还要做reshape操作?
在第一章的代码示例中,有一段如下代码:
x=numpy.array(x).reshape([100,1])
为什么需要对x对reshape?即使是reshape,x仍然是1维数据啊(只有一列)?
回答:对于sklearn中的fit方法而言,对输入的x的要求一般都是一个二维空间矩阵,即shape是一个m×n的矩阵。对于案例中的x而言,在使用numpy.array(x)方法后,其shape是[100,],这是一个一维空间数据
x = numpy.array(x)# 这是一个一维空间数据
print(x.shape) #查看shape
print(x[:5]) # 查看前5条数据
上述代码输出如下:
(100L,)
[ 28192. 39275. 34512. 24430. 23811.]
而reshape之后的shape是[100,1],这是一个二维空间下的矩阵。
x = x.reshape((100,1)) #这是一个二维空间数据
print(x.shape) #查看shape
print(x[:5]) # 查看前5条数据
上述代码返回如下:
(100L, 1L)
[[ 28192.]
[ 39275.]
[ 34512.]
[ 24430.]
[ 23811.]]
注意:x的前5条数据跟上面的不同,因此里面多了一个维度。
再推广下,如果shape后是[100,1,1],那么这是1个三维空间矩阵。
x = x.reshape((100,1,1)) # 这是一个三维空间数据
print(x.shape) #查看shape
print(x[:5]) # 查看前5条数据
上述代码返回结果如下:
(100L, 1L, 1L)
[[[ 28192.]]
[[ 39275.]]
[[ 34512.]]
[[ 24430.]]
[[ 23811.]]]
这里面其实有一个关于维度的概念容易混淆。在sklearn中的维度指的是维度空间,而不是列。为了更好的区分这两个概念,前者通常称为dimension,后者称为feature,这样就容易区分了。对于二维(dimension)空间下的数据而言,无论有多少个feature,都是一个二维空间数据。例如[3,4],[100,10000],这些都是二维空间下的矩阵,只是feature的数量不同而已。
日常情况下,由于大家会将feature理解为dimension,所以会产生混淆。
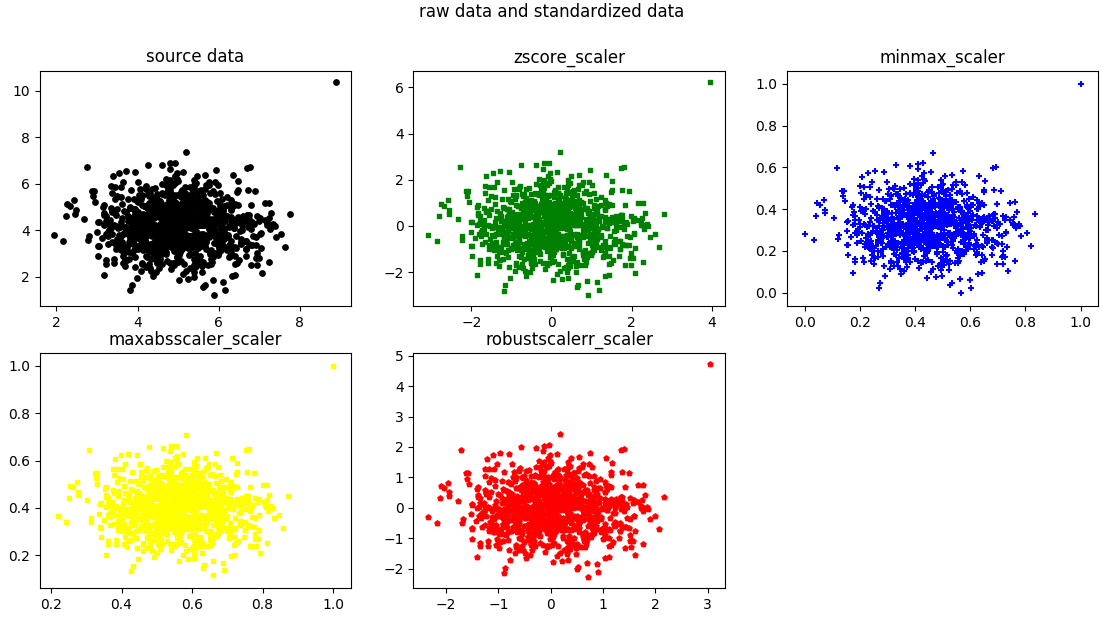
2.问题:我看书里面好像很多图的原图应该是彩色的,但是印刷确实黑白的,有些图看不清楚啊
回答:的确,受限于成本原因,出版社在对每本书做定位的时候都会有一个相对合理的成本标准。本书也不例外。我查看了下本书的图像,把其中可能涉及到的会混淆原图意义的图放在这里,供读者参考。
P126 图3-4
其中第二排,第一个图由于是黄色,纸质书上看不清楚。
P162 图4-2

P170 图4-3
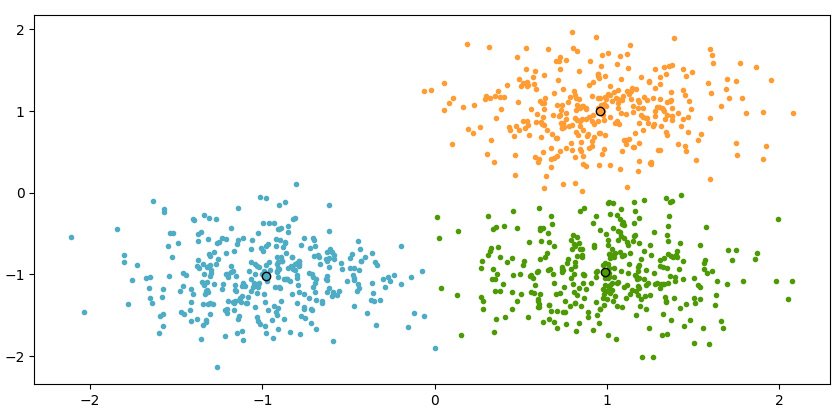
P180 图4-4
书中黑白色的印刷,难以区分不同模型的线条,如下是原图
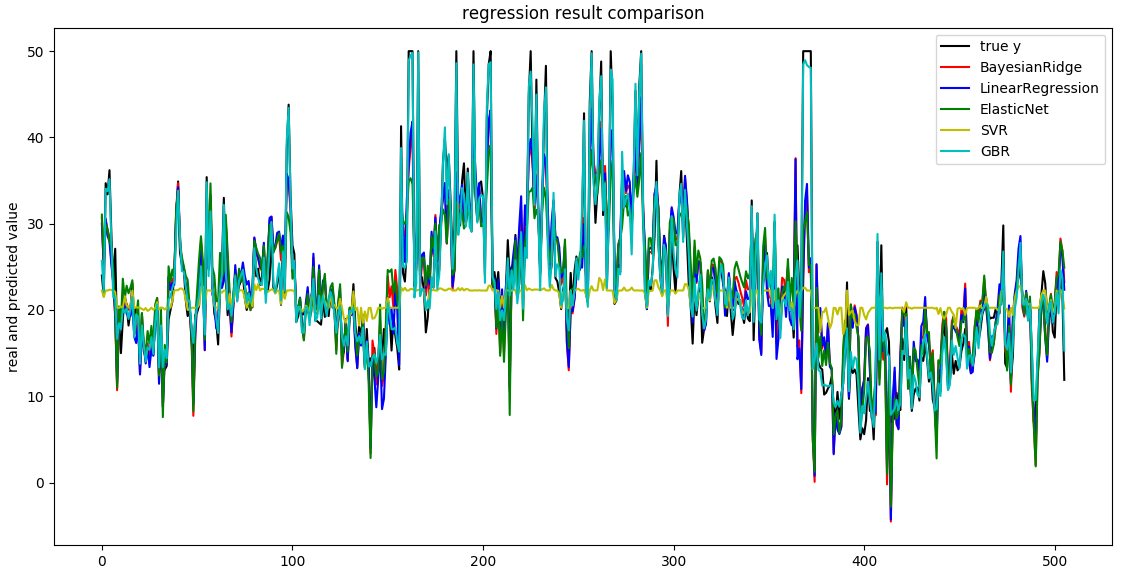
P194 图4-8
决策树规则输出树形图中由于没有颜色,很难区分不同的分裂项的属性,如下是原图。
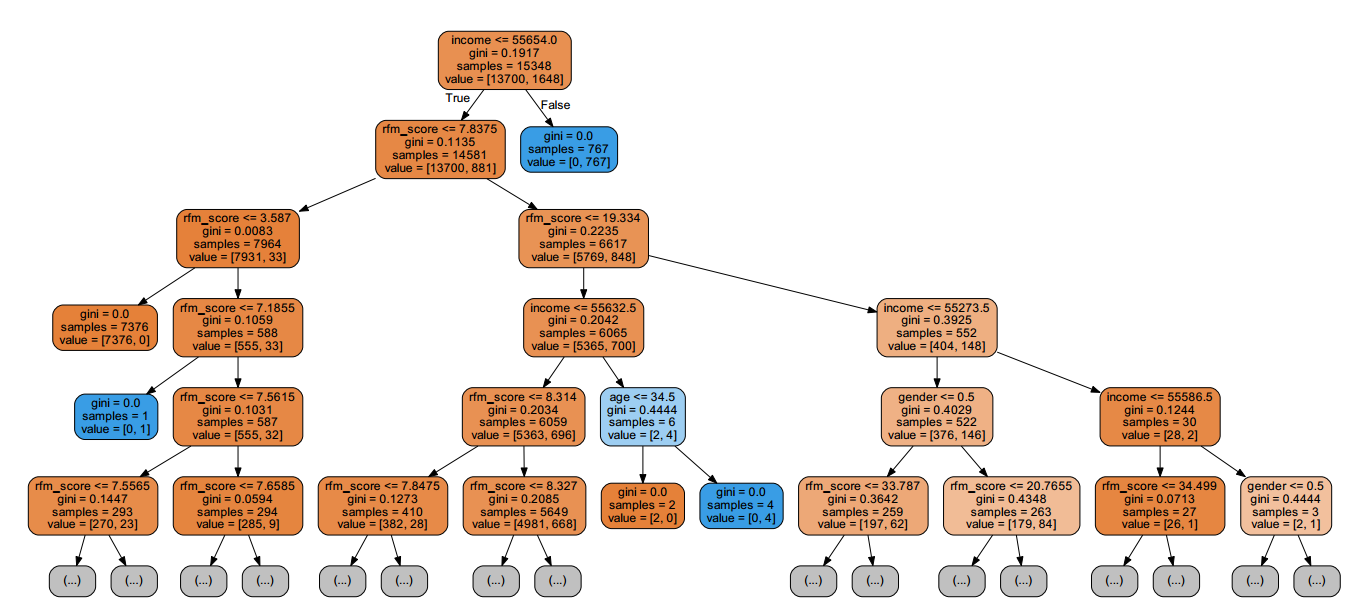
P239 图4-16
用户点击热力图,黑白色是无法展示热力图的效果的。

P249 图4-18
输出的字符云,不同区域的颜色是跟原始图像对应的。如原图。

P339 图6-2
书中对于不同月份的颜色无法区分,原图如下:
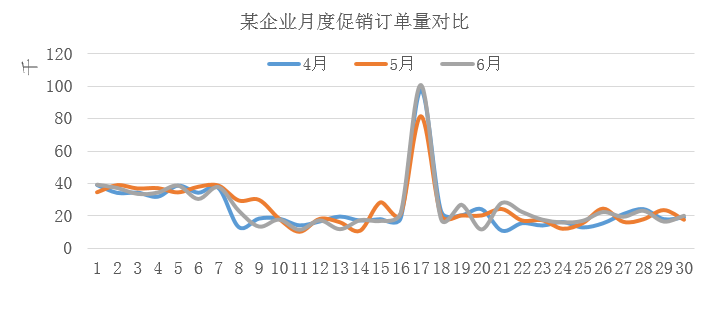
P350 图6-6
书中预测数据和实际数据的线条无法区分,原图如下:
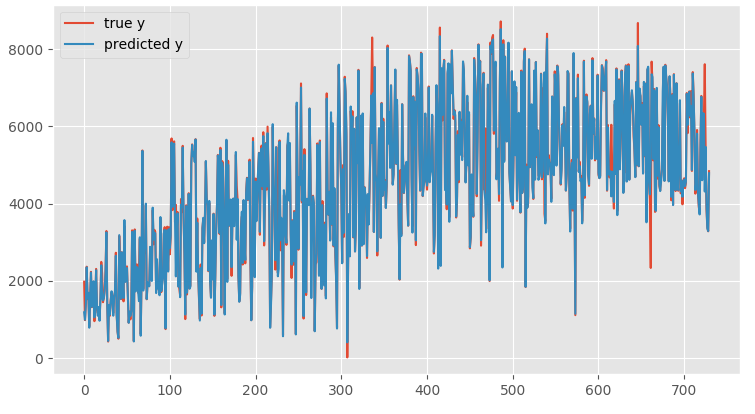
P415 图7-17
书中对于左右两侧的分裂颜色区分不明显,原图如下:
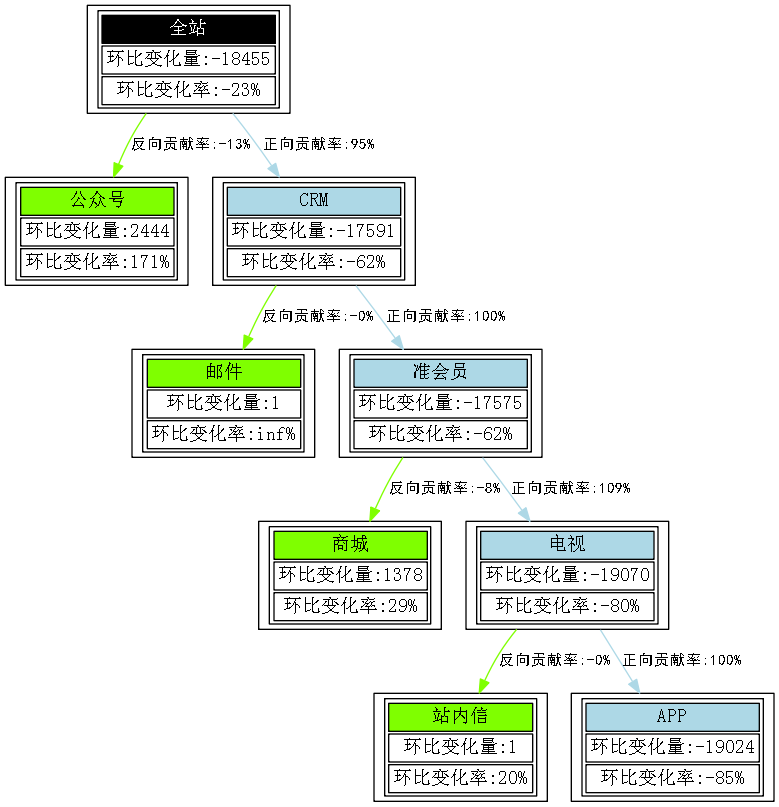
P446 图7-22
书中4个类别的线条颜色无法区分,原图如下:
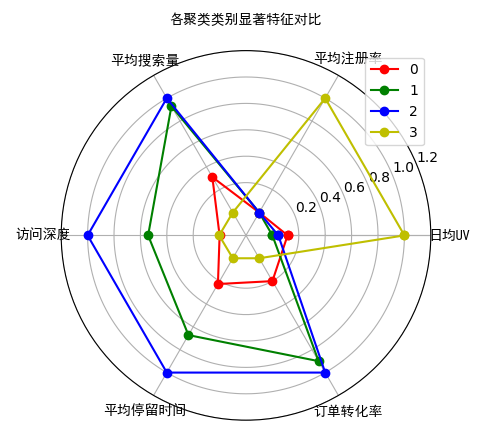
P449 图7-23
书中对于不同类别的区分也不明显,原图如下:
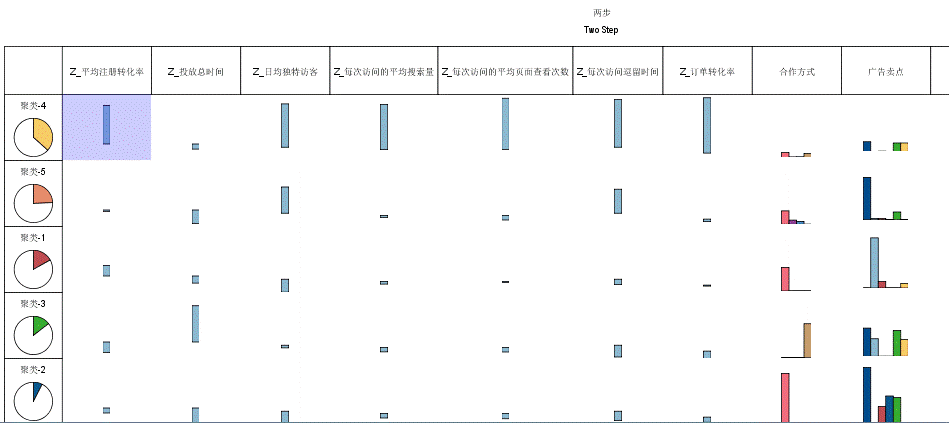
3.问题:这本书基本都能会的话,在数据分析中属于什么段位水准呢?
回答:对分析师而言,这个角色的要求一般包括数据类技能和业务类技能两方面。本书中尽量将我过往的经历总结出来,希望能给读者参考。
就这两方面的技能而言,数据类技能上,由于里面考虑到兼顾更多读者的现有知识水平和状态,因此涉及到了多种“参差不齐”的知识点和技能点,但读者会发现,越往后的综合数据技能应用的难度越高。整体上,如果都能掌握的话,数据类技能属于高级分析师的水平。
但就业务类技能而言,这种经验的培养其实很难在一朝一夕内掌握的,更不是在看了一本书之后就能完全体会的。这类业务技能决定了在面对一个命题(例如数据分析、专项分析甚至报表数据)时的思维状态、发散点和思维方式,这些都需要时间来沉淀。本书总结的这些,需要读者跟实际运营业务相结合去体会才能有真正的感觉,否则里面的经验点很难体现出价值。因此,整体上,如果读者已经是一个中级分析师的水平,那么配合本书的内容,达到高级分析师的水平;如果读者是初级分析师的水平,那么在理解本书内容的基础上,可以到达中级分析师的水平。
4.问题:为什么我下载的附件压缩包不可用或提示错误?
回答:本书的源代码文件以及数据,由于本书第一版基于Python2实现的,笔者提供Python2版本的原书代码以及对应的Python3代码(注意PILLOW和PYMYSQL库在python2和python3有差异),可通过如方式下载:
Python2版本的原书代码:
链接: 《Python数据分析与数据化运营》附件-Python2版本
Python3版本的代码:
链接: 《Python数据分析与数据化运营》附件-Python3版本
附件的两份压缩包我已经在windows电脑上测试过是可以用的,但由于某些未知的原因,可能导致读者下载后不可用,例如网络问题、压缩包本身的问题、系统兼容等。
一般情况下,读者尝试上面的两种方式是可以下载到能用的压缩包的。如果确实还是不可用的,可直接扫描加我微信,我微信直接压缩包发过去。

由于python2和python3的库,无法完全通用,因此,部分python3中没有的库,将被代替。
5.问题:书里面有没有类似R里面的auto.arima的实现逻辑?自动寻找最优的P、D、Q的方法?
回答:在本书的“4.6.4 代码实操:Python时间序列分析”一节中的实现方式,就是类似于R的auto.arima的实现方法。里面使用的是BIC最小的原则得到的最优P和Q,而D是在做差分时候已经确定的。
6.问题:问题:在P66的PIL章节中,为什么没有使用from PIL import Image,而是直接使用的import Image?
在普通的用法里,我们在安装一个库之后,都如果要使用库中的某个类,必须要使用from 库 import 类的写法,例如from os import path这种。但是在P66中使用PIL中的Image类时却没有这样做?
回答:在一般情况下,要引用某个库下面的类,都需要使用from * import *的写法,但是PIL的原作者Fredrik Lundh(以及其他贡献者)并没有具体解释为什么要支持这种用法(或者觉得没有必要解释),该库的最新版是2009年更新的且之后一直没有更新;但基于PIL的衍生分支pillow的帮助文档中,从侧面说明了这种用法之前确实是可接受(或者说可行的),原文是:
Pillow >= 1.0 no longer supports “import Image”. Please use “from PIL import Image” instead.
由于PIL已经停止更新,如果大家想继续使用的话可以用pillow,pillow目前应支持py2和py3且功能还在不断更新,具体请查阅https://pillow.readthedocs.io/en/lawww/index.html
7.问题:为什么“2.2.3 从关系型数据库MySQL读取运营数据”章节中使用MySQL导入Excel数据只有357条记录
有朋友反馈,在本地电脑上将Excel中的数据导入mysql中时,发现导入的数据不全,只有357条,更重要的是没有任何报错信息。
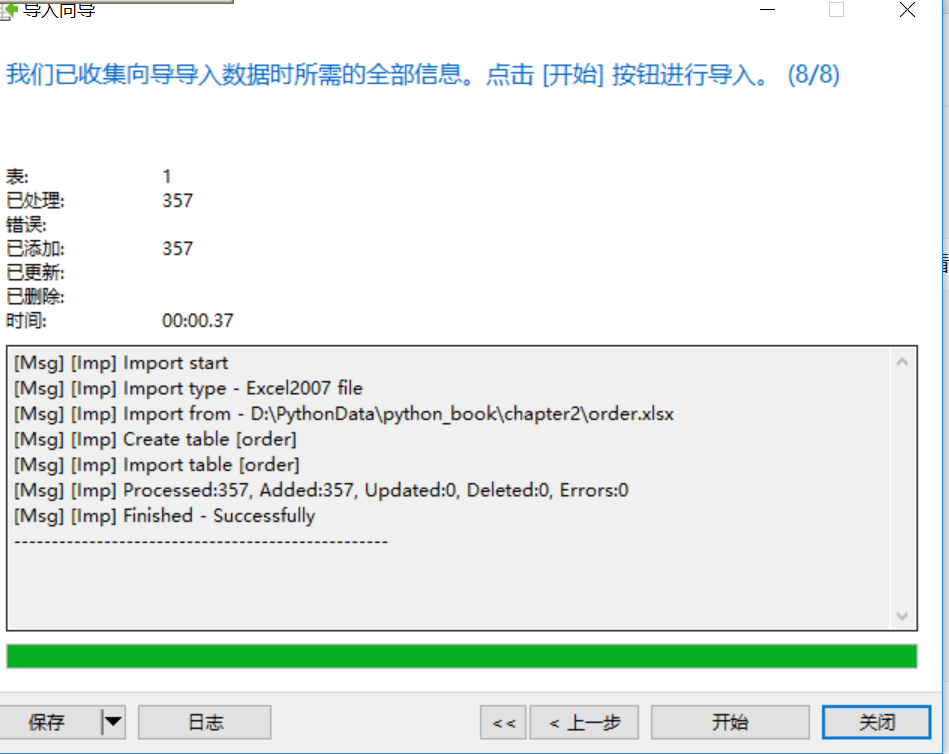
回答:本书中的Excel版本是2013版,经测试在装有office2013版本的电脑上可以导入,而office2016版本导入则不完整。
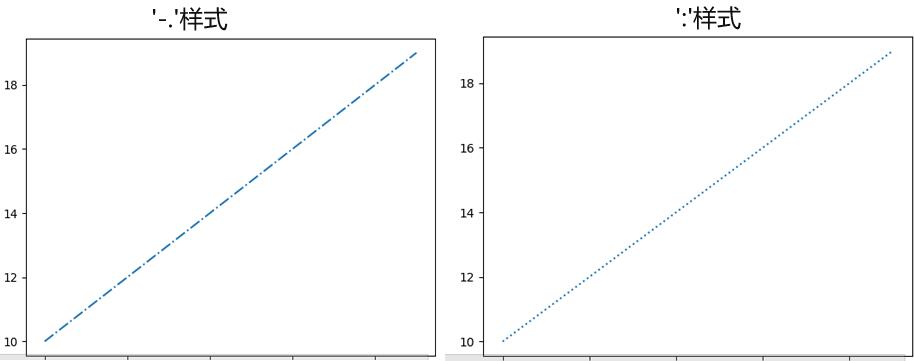
8.问题:在P170“相关知识点:scatter和plot方法”中关于线条样式的有2个点虚线,二者有什么区别?
在P170页有一段如下的文字“在plot方法的marker值中,还可设定为线条的样式'-'为实线、'--'为虚线、'-.'为点虚线、':'为点虚线。”其中这两个点虚线的样式有什么区别?
回答:'-.'的样式和':'的样式分别如下图:
9.问题:我已经安装了Image库,为什么我在电脑上直接Image却无法导入?
在本书的2.3.3中“1. 使用PIL读取图像”中的代码部分,第一段代码是直接导入Image(import Image),我电脑上已经装了Image,但是却提示错误。
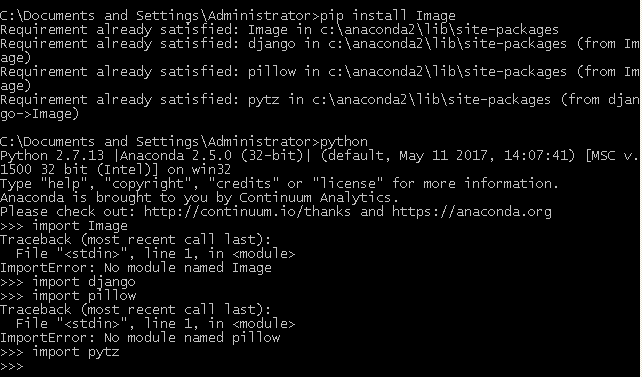
回答:该部分中import Image导入的并不是单独的Image库,而是PIL中的Image库,该方式规范的用法应该是from PIL import Image。因此单独安装的Image库并不是import的那个Image库(虽然二者名字一样)。因此,首先要安装PIL。关于PIL的安装方法,可以直接去官网下载代码源文件使用setup安装或下载Window的exe安装包http://www.pythonware.com/products/pil/
另外一个不用直接安装PIL的方法是,安装pillow(这是fork PIL的一个分支),使用pip方法即可。安装好pillow之后,直接使用from PIL import Image也是支持的(注意不是from pillow import Image,在pillow 1.0版本之后也不能用直接用import Image)
10.问题:为什么我的电脑上无法通过pip命令安装PIL?
本书的P19提到了PIL的安装方式是使用pip install PIL安装,但我的电脑却无法安装,提示:

回答:使用pip的安装方式下会从pypi中寻找适合当前系统环境的安装包,但PIL在Pypi的安装包只有32位的,因此如果读者的点是64系统,那么将无法找到适合的版本。解决方式:
可以直接去官网下载代码源文件使用setup安装或下载Window的exe安装包http://www.pythonware.com/products/pil/
另外一个不用直接安装PIL的方法是,安装pillow(这是fork PIL的一个分支),使用pip方法即可。安装好pillow之后,直接使用from PIL import Image也是支持的(注意不是from pillow import Image,在pillow 1.0版本之后也不能用直接用import Image)
11.问题:为什么我在对数据框使用sort方法排序时,会出现错误?
在对数据框排序中,本书中用到了sort方法,在“4.4.6 代码实操:Python关联分析”的“# 关联结果报表评估”模块中有一段:
print (df_lift.sort('instance', ascending=False)) # 打印排序后的数据框
其中就用到了sort方法。有些读者可能会出现报错,如下:
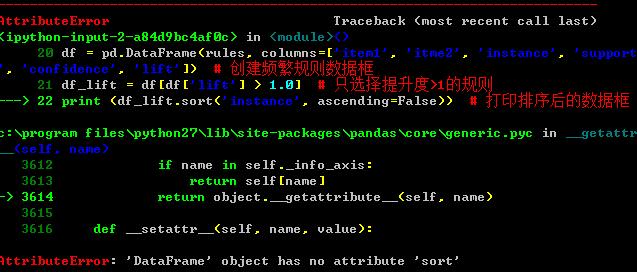
提示数据框没有sort方法,这是为什么?
回答:在Pandas后期的版本中,逐渐开始丢弃这个函数,即使在原来支持的情况下,也会出现warning。我们查看pandas的官方说明,官方也不建议再使用sort方法了,建议使用的是sort_values方法。
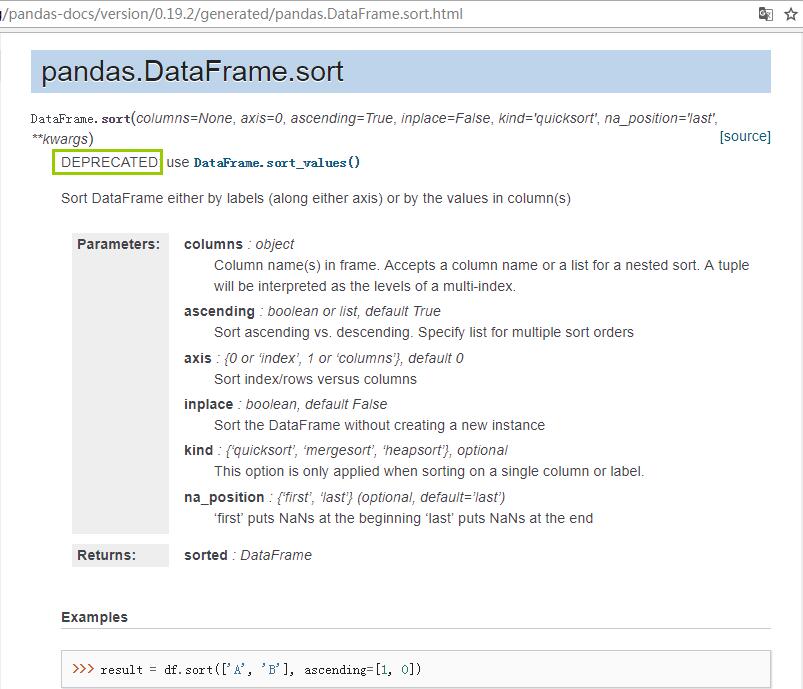
通过这个问题可以反馈说,在主流的Python库的应用过程中,不要忽视任何一个警告,虽然警告不会引发错误,但在未来的版本或应用中可能会导致问题,因此需要根据warning的提示做代码更改。
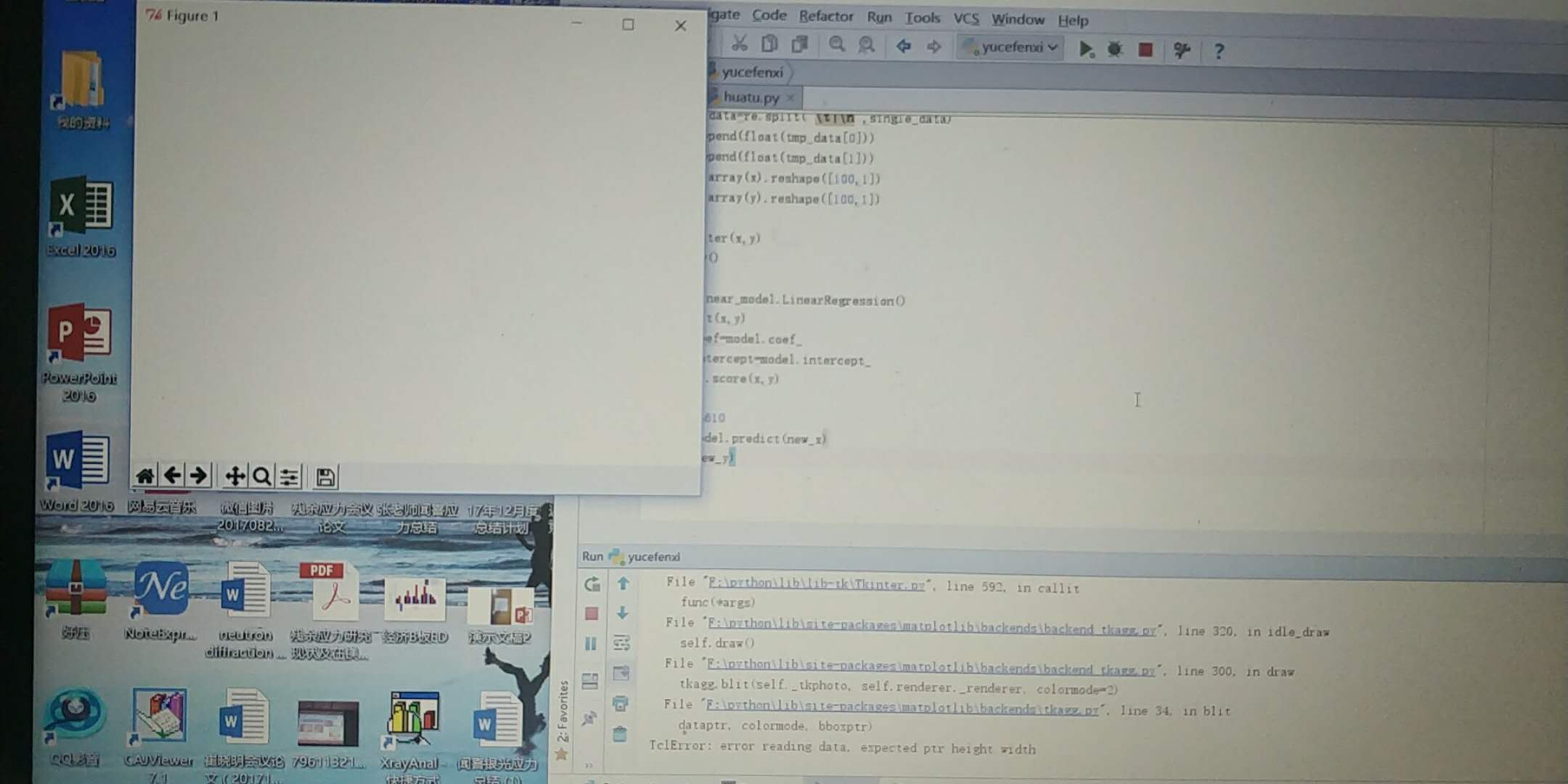
12.问题:为什么我使用Matplotlib无法展示图形,但将其保存到本地却可以看到图形?
当我运行Python程序时,发现Matplotlib无法展示图形(图形区域为空白)。但是,当我使用图像中的保存功能,将图片保存到本地却可以看到图形。
第一个图是运行python程序,图形区域无显示。
第二个图是将其保存到本地后,可以看到图像。
回答:Matplotlib没有正确显示图形,同时在交互窗口有如下类似的错误信息:
Exception in Tkinter callback
Traceback (most recent call last):
File "F:\python\lib\lib-tk\Tkinter.py", line 1541, in __call__
return self.func(*args)
File "F:\python\lib\site-packages\matplotlib\backends\backend_tkagg.py", line 228, in resize
self.draw()
File "F:\python\lib\site-packages\matplotlib\backends\backend_tkagg.py", line 300, in draw
tkagg.blit(self._tkphoto, self.renderer._renderer, colormode=2)
File "F:\python\lib\site-packages\matplotlib\backends\tkagg.py", line 34, in blit
dataptr, colormode, bboxptr)
TclError: error reading data, expected ptr height width
Exception in Tkinter callback
Traceback (most recent call last):
File "F:\python\lib\lib-tk\Tkinter.py", line 1541, in __call__
return self.func(*args)
File "F:\python\lib\lib-tk\Tkinter.py", line 592, in callit
func(*args)
File "F:\python\lib\site-packages\matplotlib\backends\backend_tkagg.py", line 320, in idle_draw
self.draw()
File "F:\python\lib\site-packages\matplotlib\backends\backend_tkagg.py", line 300, in draw
tkagg.blit(self._tkphoto, self.renderer._renderer, colormode=2)
File "F:\python\lib\site-packages\matplotlib\backends\tkagg.py", line 34, in blit
dataptr, colormode, bboxptr)
TclError: error reading data, expected ptr height width
经过排除发现,该Matplotlib的版本为2.2.0rc1为非稳定版本,而官方网站(https://matplotlib.org/) 提供的最新(2018-03-01)稳定版本为2.1.2。因此将该版本的Matplotlib卸载,然后重新使用pip命令安装即可(默认安装稳定版本)。
提示 所有的程序和版本并不是越新越好,这里面涉及到不同程序和库之间的兼容等问题。建议直接使用pip命令在线安装,程序会自动匹配最佳版本的包来下载安装。
13.问题:在P149 中,书的最下边‘for i in xrange(4)’应该改成‘for in in range(4)’?
问题:在P149 中,书的最下边for i in xrange(4)是否应该改成for in in range(4)
回答:对于书中提到的xrange(4)应该改为range(4)的问题,在书中版本上(py2),在功能和实现结果上,二者是无差异的,因此替换不是必须的。
-
在py2里面,xrange() 函数用法与 range 完全相同,所不同的是生成的不是一个数组,而是一个生成器。
-
在py3里面,去除了xrange()的命名,取而代之的是在功能上使用range来实现类似xrange的方法,实际上去除的是原py2中的range的功能。对于这个改变,可以分别在py2和py3里面使用type()测试下,会得到如下结果:
py2里面:
type(range(4)) → list
type(xrange(4)) → xrange
py3里面:
没有type(xrange(4))
type(range(4)) → range
14.问题:在第一章的代码中,在预测应用时,提示报错,需要使用reshape方法转换形状?
如果读者用的是python3或者python2较近的版本,在执行预测时,即:
pre_y = model.predict(new_x)
会提示报错,报错信息是“ValueError: Expected 2D array, got scalar array instead:
array=84610.
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
此时,只需将new_x转换为numpy数组并做reshape或者变为嵌套列表处理即可。例如:
new_x = 84610
pre_y = model.predict(numpy.array(new_x).reshape(-1,1))
print (pre_y)
或
new_x = 84610
pre_y = model.predict([[new_x]])
print (pre_y)
请问博主,我只有一点点的python基础,大概了解基本的数据定义、if条件、for循环等,能看得懂这本书吗?
当然。 为了能够兼顾更多的朋友阅读,我在上面序言里面也写到了,里面的内容都是由浅入深的介绍的,比如第一章的python只是用了一个很简单的例子说明了如何通过python来做数据分析。而且里面的稍微复杂一点的知识点,我都有单独做介绍。对于每个功能的实现我也基本在不同章节里面用不同的方法,这样可以让大家根据自身习惯选择最适合自己的方法。 所以,只要能看得懂python代码,并且能动手改/写,就可以开始了。
您好 书已买 但是下载的代码 无论是华章的链接还是您博客给的地址 下载完了后都报不包含文件或是文件已损坏,如果方便请发我邮箱一份 多谢438343096@qq.com
你好,我这里(Windows电脑)下载下来的压缩包是可用的。如果不可用,可以从百度网盘下载。如果还是有问题,可以加我微信我直接发压缩包给你。
您好龙哥,我已买了书,想问您一下4.3.6 案例:用户流失预测分析和应用的classification.csv数据集文件在哪里?我在源代码的包里面找到一个文件名一模一样的,但是跟案例好像不太一样。有点急,谢谢您。
书已下单,宋老师啥时候来我们公司亲自面授一下啊?(^▽^)
可以当面交流啊,可以先加我微信,具体时间我们约。
您好 书中的第一个案例 因为sklearn升级 报错 ValueError: Expected 2D array, got scalar array instead: array=84610. Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
在数据分析学习的路上,前前后后看了很多书和视频,但是每本书都很难完全看完,当初从图书馆借到您的这本书时,根本没想到自己能慢慢去看,但当看了一章的后,真的发现这本书跟其他书不一样,里面融入了作者大量的体会与经验,并且对于源码的解释十分详细,就连只学过两小时python基础的前端室友也能看懂一二。
真心感谢作者的无私分享~
您好,已购买书籍,在学习4.4关联规则的过程中,执行print(df_lift.sort('instance',ascending=False))时,提示“AttributeError: 'DataFrame' object has no attribute 'sort'”#上网查询后将sort转换为sort_values后,便可正常运行,请问是书中这块有误还是本人的操作原因,如果是本人操作有误,请问错误原因是,谢谢!
您好,已购买书籍,在学习4.4关联规则的过程中,执行apriori.createData总是提示“AttributeError: module 'apriori' has no attribute 'createDate'”回到您自己定义的apriori中进行查看,发现只有createC1这个函数,而没有createDate
在阅读您的书籍时,发现一个错误:在P149 中,书的最下边‘for i in xrange(4)’应该改成‘for in in range(4)’,望采纳,谢谢!
该问题我已经在 常见问题 中的 13.问题:在P149 中,书的最下边‘for i in xrange(4)’应该改成‘for in in range(4)’? 具体解释了,麻烦点击过去具体看下子。
已经购买,刚看了下书的目录,并大概翻了下内容,还不错的样子。还没详细看内容,不知道作者里面有没有类似R里面的atuo.arima的实现逻辑?自动寻找最优的P、D、Q的方法。
你好。感谢支持! 书籍的“4.6.4 代码实操:Python时间序列分析”就是类似于R的auto.arima的实现方法。里面使用的是BIC最小的原则得到的最优P和Q,而D是在做差分时候已经确定的。
首先给博主点个赞,书籍内容非常好,是最近几个月内买的最值的书了。 但我发现一个问题,想请博主解惑。我买了很多书,但由于各种原因都无法看完,或者有的根本没看,如何才能把书籍的知识最大化转化为工作应用?
宋老师您好,已经拜读了您的大作《Python数据分析与数据化运营》,想请教一下书中提到的方法论在金融领域(资产管理方向)有什么实践吗?感谢!
现在的市面上的人工智能、机器学习、深度学习、神经网络、模式识别、自然语言处理、图像识别等人工智能方面的书籍应该已有很多好书。但大多数停留在理论层面。我是自学人工自能的,理论学了不少,但是心里完全没底。一本有实际商用案例的书籍对我这类人重要性不言而喻。已经让公司已经采购了这本书。我真切希望作者以后能出版深度学习,自然语言处理,图像识别这些用商用案例的书。需要这类书的人群很多。