- 1.P108 第二段文字中,英语、数据、语文成绩……中的“数据”应为“数学”。
- 2.P149 最下面的amount2的值应该是4个,对应的数据也应该是4个值。
- 3.P93 页面顶部描述文字中,“通过df.null方法找到所有数据..”中的df.null应该改为df.isnull()
- 4.P396页,模型训练-交叉验证 章节的代码中的“cv_score = cross_val_score(model_gdbc”应该改为“cv_score = cross_val_score(model_vot”
- 5.P179 最底部最后一行的文字表述中“不能直接fit到klearn的K-Means模”中的“klearn”应为“sklearn”
- 6.P198 左侧靠中间位置的文本描述中,(1)部分, “此时的回归模型及其不稳定且方差较大” 中的“及其”应为“极其”
- 7.P347 步骤5 模型训练 - 建立pipeline中用到的模型对象 模块中缺少pipeline的代码段
- 8.P102 第2部分生成原始数据中,原始数据应为3行4列,同时后续的输出值需要增加score相关的信息
- 9.P180 第1部分导入库中 import matplotlib.pyplot as plt重复导入
- 10.P187 通过print(df.head())方法打印应输出多条记录,而非只有3条
- 11.P103 中部“在该过程中,先建立一个LabelEncoder对象...”该段文字描述有误
- 12.P126 上部分“from sklearn.svm import SVC # SVM中的分类算法SVC”,这段代码脱离代码段,样式不对。
- 13.P63 在SQL相关功能,中提到的正则表达式的部分,LIKE不属于通用意义上的正则表达式,只是在MYSQL中用于实现类似正则表达式功能的关键字。
- 14.P77 subplot段落中的“nrws”应为“nrows”
- 15.P78 2.3.4内容中“Python读取视频最简单的库也是Opencv”应为“Python读取视频最简单的库也是Opencv”,OpenCV注意大小写
- 16.P126 3.4.6内容中data2.txt的数据label记录分布,读取方式错误,对应到P127的展示结果也有问题。
- 17.P235 R语言的代码部分,目前的R版本中,需要在read.transactions中增加header=TRUE设置。
- 18.P235 P92-P94 Imputer缺失值函数无法导入以及使用,需要更新为新的导入和使用方法。
- 19.P137中岭回归的文字说明,alpha应该为1.0。
- 20.P212中“第3部分数据基本审查”中的print代码部分以及对应的结果需要修改。
- 21.P103顶部的数据打印结果有误。
- 22.P374关于U检验和Z检验需要合并。
- 23.P470聚类特征中获取数值型特征的索引错误
本书默认已经修正了第一版遇到的所有问题,因此以下勘误仅限于第二版。有关第一版的勘误,请见“《Python数据分析与数据化运营》第一版勘误”。
说明:由于第二版的出版时间为2019年,我已经将最新版本的代码更新到博客中,地址为:《Python数据分析与数据化运营》第二版新老版本代码对比。安装和使用最新版本的读者可参照该链接的代码。**
最近更新时间:2021-10-14
最近一次新书重印更新为2020-11(第2版第4次)重印,读者可查看“前言”的前1页找到相关信息,如下:

1.P108 第二段文字中,英语、数据、语文成绩……中的“数据”应为“数学”。


解释:如图圆圈处文字
2.P149 最下面的amount2的值应该是4个,对应的数据也应该是4个值。
使用聚类法实现离散化,k=4,那么应该代表4类数据,对应的唯一值应该是0,1,2,3

3.P93 页面顶部描述文字中,“通过df.null方法找到所有数据..”中的df.null应该改为df.isnull()
在描述缺失值的方法中,页面顶部描述文字中,“通过df.null方法找到所有数据..”中的df.null应该改为df.isnull(),如下图:
4.P396页,模型训练-交叉验证 章节的代码中的“cv_score = cross_val_score(model_gdbc”应该改为“cv_score = cross_val_score(model_vot”
P396页,模型训练-交叉验证 章节的代码:
cv_score = cross_val_score(model_gdbc, x_smote_resampled, y_smote_resampled, cv=cv)
应该改为:
cv_score = cross_val_score(model_vot, x_smote_resampled, y_smote_resampled, cv=cv)
这是对集成模型的交叉检验的测试,而非单个模型。

5.P179 最底部最后一行的文字表述中“不能直接fit到klearn的K-Means模”中的“klearn”应为“sklearn”
最底部最后一行的文字表述中“不能直接fit到klearn的K-Means模”中的“klearn”应为“sklearn”,缺少一个字符s,即sklearn。

6.P198 左侧靠中间位置的文本描述中,(1)部分, “此时的回归模型及其不稳定且方差较大” 中的“及其”应为“极其”
左侧靠中间位置的文本描述中,(1)部分, “此时的回归模型及其不稳定且方差较大” 中的“及其”应为“极其”,此为文字用词错误。

7.P347 步骤5 模型训练 - 建立pipeline中用到的模型对象 模块中缺少pipeline的代码段
在 P347 步骤5 模型训练 - 建立pipeline中用到的模型对象 模块中,只有已经构建好的每个model,而没有pipelines,如下图:

正确的应为:
model_etc = ExtraTreesClassifier() # ExtraTree,用于EFE的模型对象
model_rfe = RFE(model_etc) # 使用RFE方法提取重要特征
model_lda = LinearDiscriminantAnalysis() # LDA模型对象
model_rf = RandomForestClassifier() # 分类对象
# ============== 这里开始增加 ==============
# 构建带有嵌套的pipeline
pipelines = Pipeline([
('feature_union', FeatureUnion( # 组合特征pipeline
transformer_list=[
('model_rfe', model_rfe), # 通过RFE中提取特征
('model_lda', model_lda), # 通过LDA提取特征
],
transformer_weights={ # 建立不同特征模型的权重
'model_rfe': 1, # RFE模型权重
'model_lda': 0.8, # LDA模型权重
},
)),
('model_rf', model_rf), # rf模型对象
])
# ============== 到这里增加结束 ==============
8.P102 第2部分生成原始数据中,原始数据应为3行4列,同时后续的输出值需要增加score相关的信息
在P102页第2部分生成原始数据中,在中间部分print(df) # 打印输出原始数据框 之后的文字描述中,有如下描述:
“数据为3行3列的数据框,分别包含id、sex和level列,其中的id为模拟的用户ID,sex为用户性别(英文),level为用户等级(分别用high、middle和low代表三个等级)”
应改为:
“数据为3行4列的数据框,分别包含id、sex、level和score列,其中的id为模拟的用户ID,sex为用户性别(英文),level为用户等级(分别用high、middle和low代表三个等级),score列为用户得分等级(其中1/2/3分别是等级字符串,而非数字)”

同时,P102-P103对应的结果,由于新增了一列,后续的数据中应该包括score列特征。在print(raw_convert_data)后,会输出score信息。
在p104的中间部分的输出,也会包含score_1,score_2,score_3的信息,请读者知悉。
9.P180 第1部分导入库中 import matplotlib.pyplot as plt重复导入
代码可直接忽略重复部分,或删除其中任意一条。

10.P187 通过print(df.head())方法打印应输出多条记录,而非只有3条
在本书第二版的撰写中,由于新增了很多内容,因此本书在正常情况下,print(df.head())应该输出5条记录,但书中的示例中只有3条,原因是笔者手动删除了更多的2条,以减少页面代码量。请读者知悉。在代码正式执行下,不会出该问题。
11.P103 中部“在该过程中,先建立一个LabelEncoder对象...”该段文字描述有误
在该段落中,原文是“在该过程中,先建立一个LabelEncoder对象model_LabelEncoder,然后使用model_LabelENcoder做fit_transform转换,转换后的值直接替换上一步创建的副本transform_data_copy,然后使 用toarray方法输出为矩阵”。
正文的解释应该为:“在该过程中,先建立一个OneHotEncode对象model_enc,然后使用model_enc做fit_transform转换,然后使用toarray方法输出为矩阵”。

12.P126 上部分“from sklearn.svm import SVC # SVM中的分类算法SVC”,这段代码脱离代码段,样式不对。
这段代码本身属于代码格式,应与正文区分开。与上面的代码样式合并。

13.P63 在SQL相关功能,中提到的正则表达式的部分,LIKE不属于通用意义上的正则表达式,只是在MYSQL中用于实现类似正则表达式功能的关键字。
如题
具体修改如下:

14.P77 subplot段落中的“nrws”应为“nrows”
如题

15.P78 2.3.4内容中“Python读取视频最简单的库也是Opencv”应为“Python读取视频最简单的库也是Opencv”,OpenCV注意大小写
如题

16.P126 3.4.6内容中data2.txt的数据label记录分布,读取方式错误,对应到P127的展示结果也有问题。
在读取数据过程中,“第2部分 导入数据文件”pd.read_table中的sep参数的值应该是 \t 。即:
df = pd.read_table('data2.txt', sep='\t', names=['col1', 'col2', 'col3', 'col4', 'col5', 'label']) # 读取数据文件
同时,读取之后数据的展示中,label为0和1的数据结果应该如下:

col1 col2 col3 col4 col5
label
0 475 475 475 475 475
1 525 525 525 525 525
受到源数据的影响,后续的P127页的数据处理后结果的展示,也都有变化,具体为: P127顶部的数据展示:
col1 col2 col3 col4 col5
label
0 475 475 475 475 475
1 475 475 475 475 475
P127中部的数据展示:
col1 col2 col3 col4 col5`
label
0 525 525 525 525 525
1 525 525 525 525 525

17.P235 R语言的代码部分,目前的R版本中,需要在read.transactions中增加header=TRUE设置。
在读取数据过程中,需要通过 header=TRUE 来正确读取数据,因此完整的代码为:
r_script = '''
library(arules)
data < - read.transactions("order_table.csv", format="single",header=TRUE,cols=c("order_id", "product_name"), sep=",")
init_rules <- apriori(data, parameter = list(support = 0.01, confidence = 0.05, minlen = 2))
sort_rules <- sort(init_rules,by="lift")
rules_pd <- as(sort_rules, "data.frame")
'''

18.P235 P92-P94 Imputer缺失值函数无法导入以及使用,需要更新为新的导入和使用方法。
在以前的版本中, Imputer 是sklearn.preprocessing的一部分,可以直接导入。在之后以及最新的版本中,以及没有Imuputer方法了,而是拆分了多个细分方法,集成在[sklearn.impute](https://scikit-learn.org/stable/modules/classes.html#module-sklearn.impute)中。因此,现在的使用包含如下4个细分方法:
impute.SimpleImputer
impute.IterativeImputer
impute.MissingIndicator
impute.KNNImputer
现在要使用这些方法,具体规则如下:
from sklearn import impute # 导入impute库或者里面的子库
imp_mean = impute.SimpleImputer(missing_values=np.nan, strategy='mean') # 使用其中的 SimpleImputer 方法
imp_mean.fit_transform([[7, 2, 3], [4, np.nan, 6], [10, 5, 9]]) # 预处理
19.P137中岭回归的文字说明,alpha应该为1.0。
![]()
如果图中划线和画圈的两部分,跟代码注释中的内容相同,alpha的值为1.0。
20.P212中“第3部分数据基本审查”中的print代码部分以及对应的结果需要修改。
在P212中, 第3部分数据基本审查 中的原始print语法为:
n_samples, n_features = X.shape # 总样本量,总特征数
print('samples: {0}| features: {1} | na count: {2}'.format(n_samples, n_features,**raw_data.isnull().any().count()**))
其中的raw_data.isnull().any().count()应该改为raw_data.isnull().any().sum(),原因是count得到的是总的列的数量,而非na值的数量。在 raw_data.isnull().any() 之后,其值为True或False,通过sum才能得到真正为na值的(True)的结果。
对应到的下面的打印结果,应该是:
samples: 1000| features: 41 | na count: 4
![]()
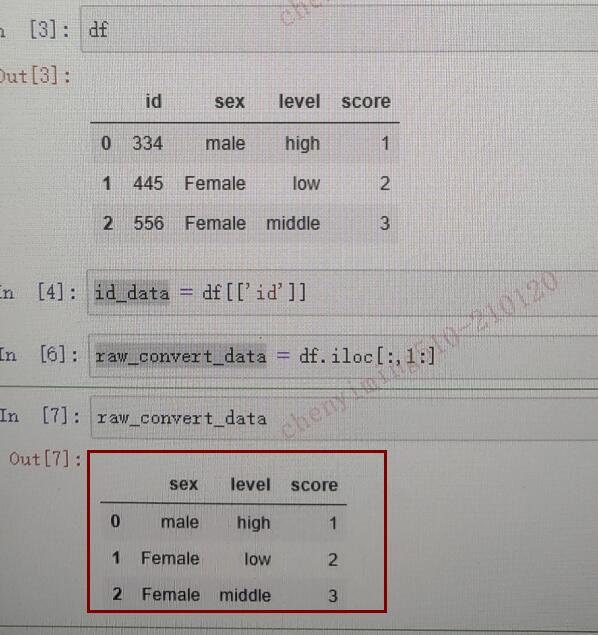
21.P103顶部的数据打印结果有误。
在P102中,通过raw_convert_data = df.iloc[:, 1:] 设置了变量 raw_convert_data 。打印结果错误,应该包括:sex level score三列。
下图是现在版本的错误之处:

下图(标红框内)是应该打印得到的结果:
22.P374关于U检验和Z检验需要合并。
在关于U检验和Z检验的描述中,本书将其拆分为两类。但在国内都普遍把U检验认为是与Z检验相同。因此,下图中框选处应该合并为:
- U检验(也称Z检验)是在大样本(n>30)的情况下,检验随机变量的数学期望是否等于某一已知值的一种假设检验方法。U检验适用于样本量n较大且符合正态分布的情况,也适用于比较两个平均数的差异是否显著的场景。

23.P470聚类特征中获取数值型特征的索引错误
在如下代码中:
# part3 计算各个聚类类别内部最显著特征值
cluster_features = [] # 空列表,用于存储最终合并后的所有特征信息
for line in range(best_k): # 读取每个类索引
label_data = merge_data[merge_data['clusters'] == line] # 获得特定类的数据
part1_data = label_data.iloc[:, 1:7] # 获得数值型数据特征
part1_desc = part1_data.describe().round(3) # 得到数值型特征的描述性统计信息
merge_data1 = part1_desc.iloc[2, :] # 得到数值型特征的均值
part2_data = label_data.iloc[:, 7:-1] # 获得字符串型数据特征
part2_desc = part2_data.describe(include='all') # 获得字符串型数据特征的描述性统计信息
merge_data2 = part2_desc.iloc[2, :] # 获得字符串型数据特征的最频繁值
merge_line = pd.concat((merge_data1, merge_data2), axis=0) # 将数值型和字符串型典型特征沿行合并
cluster_features.append(merge_line) # 将每个类别下的数据特征追加到列表</pre>
其中的:merge_data1 = part1_desc.iloc[2, :] ,需要将索引改为merge_data1 = part1_desc.iloc[1, :] ,否则获取到的是标准差数据。对应后面的图形也有差异,请读者知悉。
书籍第162页第6部分主要程序模块在运行时碰到问题,如下: FileNotFoundError: [Errno 2] No such file or directory: 'dataivy.cn-Feb-2018.gz'
这个问题主要是没有找到这个文件。可能排查2个方面: 1. 这个文件是否真的存在。如果是从书籍的微信群或者这个网站下载的附件。里面是有这个文件的,可以搜一下文件名确认一下就行了。 2. 工作目录是否正确。按照书中的步骤操作即可。
4.2.4 节, (1)部分, “此时的回归模型及其不稳定且方差较大” -- “及其”-->“极其”
感谢反馈,已经更新到勘误中。第二版勘误
是的,感谢提出问题。更多勘误问题,你可以在 第二版勘误找到哈
4.1.6 聚类分析这里发现一个勘误, “字符串型特征(IS_ACTIVE)代表一个分类型变量,不能直接fit到klearn的K-Means模型中” 之类klearn 应该为 sklearn
感谢反馈,应该更新到勘误中。第二版勘误
P396页,模型训练-交叉验证 章节的代码: > cv_score = cross_val_score(model_gdbc, x_smote_resampled, y_smote_resampled, cv=cv) 是否应该是 > cv_score = cross_val_score(model_vot, x_smote_resampled, y_smote_resampled, cv=cv)
感谢指正,已经更新到勘误第二版勘误中。
4.2 回归分析-案例:大型促销活动前的销售预测 pre_y_list = [model.fit(X_train, y_train).predict(X_test) for model in model_list] # 各个回归模型预测的y值列表
TypeError: must be real number, not str 应该是model_list的问题,希望发布纠错代码
你好。我测试了下代码,是可以正常运行的。
[ ]
]
你的报错我没有遇到,我的是python3.7版本。你方便的话加我微信,详细描述下到底如何出现这个问题的吧。或者你在地下把你的python版本、执行错误截图等发一下,我看下。谢谢。
宋老师,我使用的最新版的anaconda(201910),碰到如下问题 3.2.3 代码实操:Python标志转换 一节中, 1)拆分ID和数据列时,执行df.iloc[:,1:]后,打印的结果跟书上的不一样,比书上多一列:scroe 2)对数据列中的字符串做转换,3)合并数据后 结果跟书上是一致的; 使用Pandas的get_dummies做标志转换后,结果又多了scroe_1,scroe_2,score_3 三列;
麻烦核实一下~
是的,抱歉,是书中的错误。具体见勘误信息:第二版勘误
宋老师你好,在3.2.3代码python标志转化实操中,使用了sklearn进行标志转换。在我使用后发现它会出现 could not convert string to float: 'middle'的错误,我再去看了第一版的代码,也和第二版相同,不知道这个问题要怎么解决。
你看下你的sklearn的版本,在现在版本里面。OrdinalEncoder和OneHotEncoder都能直接转化字符串。看下官方的示例: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OrdinalEncoder.html#sklearn.preprocessing.OrdinalEncoder https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html#sklearn.preprocessing.OneHotEncoder
Hi,钰文。从报错来看,记录里面由于是字符串类型,无法直接转换为数值型,所以报错。你方便扫描加我微信吗?具体把问题发给我看下。
宋老师,你好。第二版P391中执行from sklearn.preprocessing import OrdinalEncoder输出ImportError: cannot import name 'OrdinalEncoder' from 'sklearn.preprocessing'。python版本为3.7.3,sklearn版本为0.21.3。期盼宋老师指导,谢谢。
你好,我看了下最新的版本以及你所在的版本,这个方法导入使用是没有语法错误的。你可以:
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OrdinalEncoder.html#sklearn.preprocessing.OrdinalEncoder
如果还是有问题,加我微信具体沟通下哈。