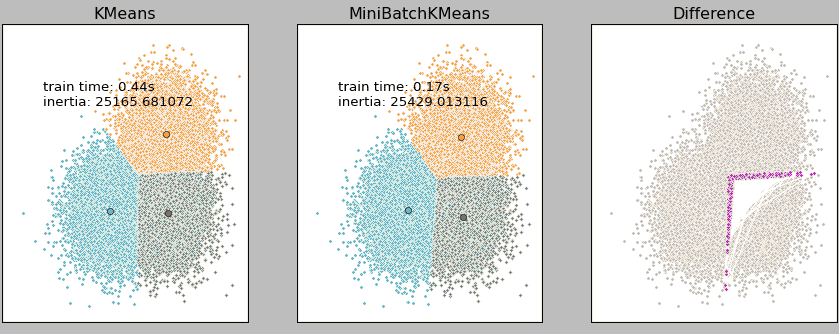
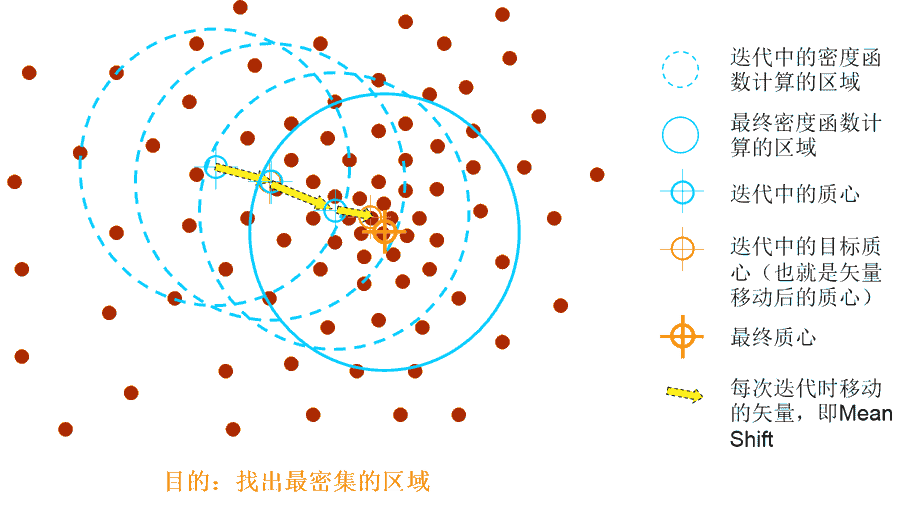
案例背景
某企业由于投放的广告渠道比较多,需要对其做广告效果分析以实现有针对性的广告效果测量和优化工作。跟以应用为目的的案例不同的是,由于本案例是一个分析型案例,该过程的输出其实是不固定的,因此需要跟业务运营方具体沟通需求。
以下是在开展研究之前的基本预设条件:
- 广告渠道的范畴是什么?具体包括哪些渠道?——所有站外标记的广告类渠道(以ad_开头)。
- 数据集时间选择哪个时间段?——最近90天的数据。
- 数据集选择哪些维度和指标?——渠道代号、日均UV、平均注册率、平均搜索量、访问深度、平均停留时间、订单转化率、投放总时间、素材类型、广告类型、合作方式、广告尺寸、广告卖点。
- 专题分析要解决什么问题