Affinity Propagation聚类算法简称AP,是一个在07年发表在Science上面比较新的算法。
AP算法的基本思想是将全部样本看作网络的节点,然后通过网络中各条边的消息传递计算出各样本的聚类中心。聚类过程中,共有两种消息在各节点间传递,分别是吸引度(responsibility)和归属度(availability)。AP算法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生m个高质量的Exemplar(类似于质心),同时将其余的数据点分配到相应的聚类中。
在AP算法中有一些特殊名词:
- Exemplar:指的是聚类中心,K-Means中的质心。
- Similarity:数据点i和点j的相似度记为s(i, j),是指点j作为点i的聚类中心的相似度。一般使用欧氏距离来计算,一般点与点的相似度值全部取为负值;因此,相似度值越大说明点与点的距离越近,便于后面的比较计算。
- Preference:数据点i的参考度称为p(i)或s(i,i),是指点i作为聚类中心的参考度。一般取s相似度值的中值。
- Responsibility:r(i,k)用来描述点k适合作为数据点i的聚类中心的程度。
- Availability:a(i,k)用来描述点i选择点k作为其聚类中心的适合程度。
- Damping factor(阻尼系数):主要是起收敛作用的。
在实际计算应用中,最重要的两个参数(也是需要手动指定)是Preference和Damping factor。前者定了聚类数量的多少,值越大聚类数量越多;后者控制算法收敛效果。
AP聚类算法与经典的[K-Means]聚类算法相比,具有很多独特之处:
- 无需指定聚类“数量”参数。AP聚类不需要指定K(经典的K-Means)或者是其他描述聚类个数(SOM中的网络结构和规模)的参数,这使得先验经验成为应用的非必需条件,人群应用范围增加。
- 明确的质心(聚类中心点)。样本中的所有数据点都可能成为AP算法中的质心,叫做Examplar,而不是由多个数据点求平均而得到的聚类中心(如K-Means)。
- 对距离矩阵的对称性没要求。AP通过输入相似度矩阵来启动算法,因此允许数据呈非对称,数据适用范围非常大。
- 初始值不敏感。多次执行AP聚类算法,得到的结果是完全一样的,即不需要进行随机选取初值步骤(还是对比K-Means的随机初始值)。
- 算法复杂度较高,为O(NNlogN),而K-Means只是O(N*K)的复杂度。因此当N比较大时(N>3000),AP聚类算法往往需要算很久。
- 若以误差平方和来衡量算法间的优劣,AP聚类比其他方法的误差平方和都要低。(无论k-center clustering重复多少次,都达不到AP那么低的误差平方和)
AP算法相对K-Means鲁棒性强且准确度较高,但没有任何一个算法是完美的,AP聚类算法也不例外:
- AP聚类应用中需要手动指定Preference和Damping factor,这其实是原有的聚类“数量”控制的变体。
- 算法较慢。由于AP算法复杂度较高,运行时间相对K-Means长,这会使得尤其在海量数据下运行时耗费的时间很多。
以下使用Python的机器学习库SKlearn应用AP(AffinityPropagation)算法进行案例演示。 案例中,我们会先对AP算法和K-Means聚类算法的运行时间做下对比,分别选取100,500,1000样本量下进行两种算法的聚类时间对比;然后,使用AP算法做聚类分析。
AP和K-Means运行时间对比
import numpy as np
import matplotlib.pyplot as plt
import time
from sklearn.cluster import KMeans,AffinityPropagation
from sklearn.datasets.samples_generator import make_blobs
# 生成测试数据
np.random.seed(0)
centers = [[1, 1], [-1, -1], [1, -1]]
kmeans_time = []
ap_time = []
for n in [100,500,1000]:
X, labels_true = make_blobs(n_samples=n, centers=centers, cluster_std=0.7)
# 计算K-Means算法时间
k_means = KMeans(init='k-means++', n_clusters=3, n_init=10)
t0 = time.time()
k_means.fit(X)
kmeans_time.append([n,(time.time() - t0)])
# 计算AP算法时间
ap = AffinityPropagation()
t0 = time.time()
ap.fit(X)
ap_time.append([n,(time.time() - t0)])
print ('K-Means time',kmeans_time[:10])
print ('AP time',ap_time[:10])
# 图形展示
km_mat = np.array(kmeans_time)
ap_mat = np.array(ap_time)
plt.figure()
plt.bar(np.arange(3), km_mat[:,1], width = 0.3, color = 'b', label = 'K-Means', log = 'True')
plt.bar(np.arange(3)+0.3, ap_mat[:,1], width = 0.3, color = 'g', label = 'AffinityPropagation', log = 'True')
plt.xlabel('Sample Number')
plt.ylabel('Computing time')
plt.title('K-Means and AffinityPropagation computing time ')
plt.legend(loc='upper center')
plt.show()
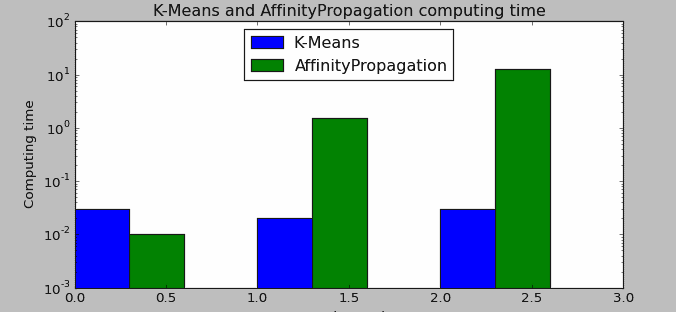
运算结果如下:
 `
`
('K-Means time', [[100, 0.029999971389770508], [500, 0.029999971389770508], [1000, 0.0410001277923584]])
('AP time', [[100, 0.03000020980834961], [500, 1.8999998569488525], [1000, 16.31499981880188]])
图中为了更好的展示数据对比,已经对时间进行log处理,但可以从输出结果直接读取真实数据运算时间。由结果可以看到:当样本量为100时,AP的速度要大于K_Means;当数据增加到500甚至1000时,AP算法的运算时间要大大超过K-Means算法;甚至当我试图运算更大的数据量(100000)时,直接内存错误而被迫中止。
AP聚类示例
from sklearn.cluster import AffinityPropagation
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
import numpy as np
# 生成测试数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=300, centers=centers, cluster_std=0.5, random_state=0)
# AP模型拟合
af = AffinityPropagation(preference=-50).fit(X)
cluster_centers_indices = af.cluster_centers_indices_
labels = af.labels_
new_X = np.column_stack((X, labels))
n_clusters_ = len(cluster_centers_indices)
print('Estimated number of clusters: %d' % n_clusters_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f" % metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f" % metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f" % metrics.silhouette_score(X, labels, metric='sqeuclidean'))
print('Top 10 sapmles:',new_X[:10])
# 图形展示
import matplotlib.pyplot as plt
from itertools import cycle
plt.close('all')
plt.figure(1)
plt.clf()
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters_), colors):
class_members = labels == k
cluster_center = X[cluster_centers_indices[k]]
plt.plot(X[class_members, 0], X[class_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col, markeredgecolor='k', markersize=14)
for x in X[class_members]:
plt.plot([cluster_center[0], x[0]], [cluster_center[1], x[1]], col)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()
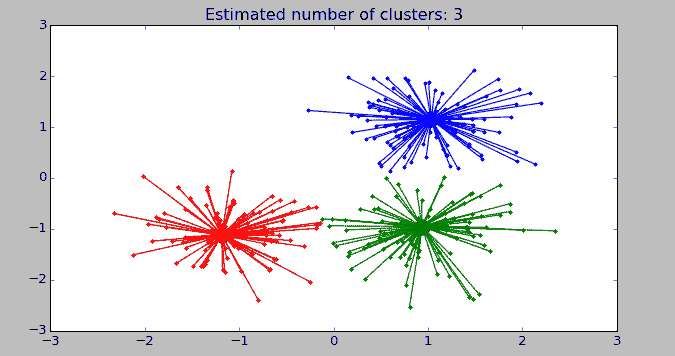
运行结果:
 `
`
Estimated number of clusters: 3
Homogeneity: 0.872
Completeness: 0.872
V-measure: 0.872
Adjusted Rand Index: 0.912
Adjusted Mutual Information: 0.871
Silhouette Coefficient: 0.753
('Top 10 sapmles:', array([[ 1.47504421, 0.9243214 , 0. ],
[-0.02204385, -0.80495334, 1. ],
[-1.17671587, -1.80823709, 2. ],
[ 0.77223375, 1.00873958, 0. ],
[ 1.23283122, 0.23187816, 0. ],
[-0.92174673, -0.88390948, 2. ],
[ 1.65956844, -1.44120941, 1. ],
[ 0.33389417, -1.98431234, 1. ],
[-1.27143074, -0.79197498, 2. ],
[ 1.33614738, 1.20373092, 0. ]]))
AffinityPropagation可配置的参数包括:(重点是damping和preference)
class sklearn.cluster.AffinityPropagation(damping=0.5, max_iter=200, convergence_iter=15, copy=True, preference=None, affinity='euclidean', verbose=False)
AP算法的应用场景: 图像、文本、生物信息学、人脸识别、基因发现、搜索最优航线、 码书设计以及实物图像识别等领域。
尾巴
综合来看,由于AP算法不适用均值做质心计算规则,因此对于离群点和异常值不敏感;同时其初始值不敏感的特性也能保持模型的较好鲁棒性。这两个突出特征使得它可以作为K-Means算法的一个有效补充,但在大数据量下的耗时过长,这导致它的适用范围只能是少量数据;虽然通过调整damping(收敛规则)可以在一定程度上提升运行速度(damping值调小),但由于算法本身的局限性决定了这也只是杯水车薪。
THX!