聚类是数据挖掘中的基本任务,聚类是将大量数据集中具有“相似”特征的数据点划分为统一类别,并最终生成多个类的方法。
聚类分析的基本思想是“物以类聚、人以群分”,因此大量的数据集中必然存在相似的数据点,基于这个假设就可以将数据区分出来,并发现每个数据集(分类)的特征。
与聚类的概念类似的另外一个概念是“分类”,实际上二者经常被混用。但二者根本上是不同的:
- 学习方式不同。聚类是一种非监督式学习算法,而分类是监督式学习算法。
- 对源数据集要求不同。聚类不要求源数据集有标签,但分类需要标签用来做学习。
- 应用场景不同。聚类一般应用于做数据探索性分析,而分类更多的用于预测性分析。
- 解读结果不同。聚类算法的结果是将不同的数据集按照各自的典型特征分成不同类别,不同人对聚类的结果解读可能不同;而分类的结果却是一个固定值,不存在不同解读的情况。
聚类是一类成熟且经典的数据挖掘和机器学习算法,按照不同的维度划分有很多经典的算法,如K均值(K-Means)、两步聚类、Kohonen等,甚至Python提供了9中聚类算法。以下介绍比较经典的K均值(K-Means)算法。
聚类首先面临的一个问题是,如何衡量不同数据之间的“相似度”。大多数“相似度”都是基于距离计算的,距离计算可以分为两类:
基于几何距离的“相似度”
为了方便计算,假设平面上两点a(x1,y1)与b(x2,y2)) 1. 欧式距离 : a和b平方和的开方(结果越大,相似度越高)
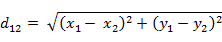
曼哈顿距离
每个维度的距离之和(结果越大,相似度越高)
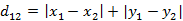
切比雪夫距离
每个维度上距离的最大值(结果越大,相似度越高) 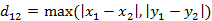
基于非几何距离的“相似度”
余弦距离
两个向量的夹角 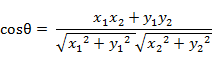 夹角余弦取值范围为[-1,1]。夹角余弦越大表示两个向量的夹角越小,夹角余弦越小表示两向量的夹角越大。当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1。
夹角余弦取值范围为[-1,1]。夹角余弦越大表示两个向量的夹角越小,夹角余弦越小表示两向量的夹角越大。当两个向量的方向重合时夹角余弦取最大值1,当两个向量的方向完全相反夹角余弦取最小值-1。
汉明距离
两个等长字符串s1与s2之间的汉明距离定义为将其中一个变为另外一个所需要作的最小替换次数。例如字符串“1111”与“1001”之间的汉明距离为2。
杰卡德相似系数(Jaccard similarity coefficient)
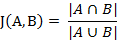
相关系数 (Correlationcoefficient)
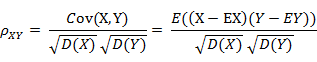
相关系数是衡量随机变量X与Y相关程度的一种方法,相关系数的取值范围是[-1,1]。相关系数的绝对值越大,则表明X与Y相关度越高。当X与Y线性相关时,相关系数取值为1(正线性相关)或-1(负线性相关)。
除了上述常用相似度计算方法外,还可能包括马氏距离、闵可夫斯基距离、标准欧氏距离等。
回到本文的主题K-Means算法来,通过上述算法来计算数据相似度(大多数选择欧氏距离),但我们会发现不同维度间由于度量单位的差异,计算的结果值会产生很大差异。例如假设A和B两个点分别具有两个维度:订单金额和转化率,那么订单金额的取值范围可能是0到无穷大,而转化率的取值为0到1,因此计算结果会由于订单金额的取值范围而“片面”夸大了这一维度的计算比重。所以大多数情况下,如果存在这种度量量级的差异会选择数据标准化,使不同维度落到相同的数据区间内然后进行计算。
上面说到大多数情况下需要标准化,就意味着不是所有的场景下都需要标准化,一种是原有的数据维度之间的量级差异不大,因此没有必要标准化;二是标准化后的结果在解读时会出现难以还原的问题,例如原本均值为180在标准化后可能就是0.31,而这个数据很难还原,只能进行相对其他维度的解读。
K-Means的计算步骤如下:
- 为每个聚类确定一个初始聚类中心,这样就有K个初始聚类中心。
- 将样本集中的样本按照最小距离原则分配到最邻近聚类。
- 使用每个聚类中的样本均值作为新的聚类中心。
- 重复步骤2.3直到聚类中心不再变化。
- 结束,得到K个聚类
K-Means的计算既然作为一种经典算法,一定有很多优势:
- 它是解决聚类问题的一种经典算法,简单、快速而且可以用于多种数据类型。
- 对处理大数据集,该算法是相对可伸缩和高效率的。
- 因为它的复杂度是0 (n k t ) , 其中, n 是所有对象的数目,k 是簇的数目,t 是迭代的次数。通常k < <n 且t < <n 。
- 算法尝试找出使平方误差函数值最小的k个划分。当结果簇是密集的,而簇与簇之间区别明显时, 它的效果较好。
但是,传统K-Means也有很多不足:
- 既然基于均值计算,那么要求簇的平均值可以被定义和使用,此时字符串等非数值型数据则不适用。
- K-Means的第一步是确定 k (要生成的簇的数目),对于不同的初始值K,可能会导致不同结果。
- 应用数据集存在局限性,适用于球状或集中分布数据,不适用于特殊情况数据。如下面这种非球状的数据分布就无法正确分类。
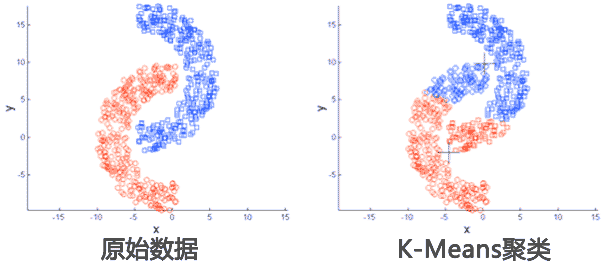
- 它对于“躁声”和孤立点数据是敏感的,少量的该类数据能够对平均值产生极大的影响。
下面使用Python的机器学习库SKlearn的KMeans算法进行演示。本案例中,从Python自带数据集iris中调取数据进行聚类,其中有两个类别是通过KMeans算法获取,为了便于比较效果,我们手动设置其中一个算法参数,使之表现“较差”,然后再与正常下的聚类模式以及原始真实数据集进行对比。 `
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
from sklearn import datasets
# 原始数据集
np.random.seed(5)
centers = [[1, 1], [-1, -1], [1, -1]]
iris = datasets.load_iris()
X = iris.data
y = iris.target
estimators = {'k_means_iris_3': KMeans(n_clusters=3),
'k_means_iris_bad_init': KMeans(n_clusters=3, n_init=1, init='random')}
# 输出两个模型的聚类结果
fignum = 1
for name, est in estimators.items():
fig = plt.figure(fignum, figsize=(4, 3))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
plt.title(name)
est.fit(X)
labels = est.labels_
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=labels.astype(np.float))
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
fignum = fignum + 1
# 展示原始真实分类结果
fig = plt.figure(fignum, figsize=(4, 3))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
plt.title('ground truth')
for name, label in [('Setosa', 0),('Versicolour', 1), ('Virginica', 2)]:
ax.text3D(X[y == label, 3].mean(), X[y == label, 0].mean() + 1.5, X[y == label, 2].mean(), name,horizontalalignment='center',bbox=dict(alpha=.5, edgecolor='w', facecolor='w'))
y = np.choose(y, [1, 2, 0]).astype(np.float)
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=y)
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('Petal width')
ax.set_ylabel('Sepal length')
ax.set_zlabel('Petal length')
plt.show()
上述代码运行结果如下: 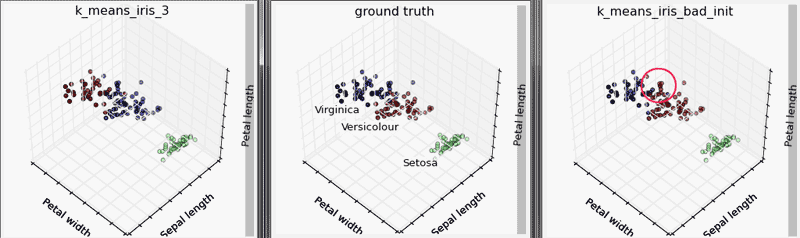
由运行结果可知,左侧正常聚类下的结果与中间的真实分类类似,只有在交叉边界存在几个分类错误点;而右侧的算法,我们故意设置了随机指定质心以及只通过一次运算确定分类,导致分类结果在交叉边界处错误较多。
应用场景:
- 图像压缩
- 大数据集的探索性分析,例如会员初步聚类
KMeans可配置的参数包括: `
- class sklearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1)
`
尾巴
K-Means使用之前的预处理必不可少,尤其是异常点和标准化的工作,而对于K的指定,可以使用通过循环次数不同K下的数据聚类结果,通常结果类别不能太多,否则就是去聚类的意义;每一个类别的数据流量大体均等,否则过少样本量的类别也很难就有实际价值;每个类别的可解释性,聚类后的每个类别都有会自己对应的特征值,不同类别之间的特征值应该差异较大才更容易解读和区别。