sklearn中的回归有多种方法,广义线性回归集中在linear_model库下,例如普通线性回归、Lasso、岭回归等;另外还有其他非线性回归方法,例如核svm、集成方法、贝叶斯回归、K近邻回归、决策树回归等,这些不同回归算法分布在不同的库中。
本示例主要使用sklearn的多个回归算法做回归分析、用matplotlib做图形展示。
本示例模拟的是针对一批训练集做多个回归模型的训练和评估,从中选择效果较好的模型并对新数据集做回归预测。本示例主要使用sklearn的多个回归算法做回归分析、用matplotlib做图形展示。
完整代码如下:
# 导入库
import numpy as np # numpy库
from sklearn.linear_model import BayesianRidge, LinearRegression, ElasticNet # 批量导
from sklearn.svm import SVR # SVM中的回归算法
from sklearn.ensemble.gradient_boosting import GradientBoostingRegressor # 集成算法
from sklearn.model_selection import cross_val_score # 交叉检验
from sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squa
import pandas as pd # 导入pandas
import matplotlib.pyplot as plt # 导入图形展示库
# 数据准备
raw_data = np.loadtxt('regression.txt') # 读取数据文件
X = raw_data[:, :-1] # 分割自变量
y = raw_data[:, -1] # 分割因变量
# 训练回归模型
n_folds = 6 # 设置交叉检验的次数
model_br = BayesianRidge() # 建立贝叶斯岭回归模型对象
model_lr = LinearRegression() # 建立普通线性回归模型对象
model_etc = ElasticNet() # 建立弹性网络回归模型对象
model_svr = SVR() # 建立支持向量机回归模型对象
model_gbr = GradientBoostingRegressor() # 建立梯度增强回归模型对象
model_names = ['BayesianRidge', 'LinearRegression', 'ElasticNet', 'SVR', 'GBR'] # 不
model_dic = [model_br, model_lr, model_etc, model_svr, model_gbr] # 不同回归模型对象
cv_score_list = [] # 交叉检验结果列表
pre_y_list = [] # 各个回归模型预测的y值列表
for model in model_dic: # 读出每个回归模型对象
scores = cross_val_score(model, X, y, cv=n_folds) # 将每个回归模型导入交叉检验模型中
cv_score_list.append(scores) # 将交叉检验结果存入结果列表
pre_y_list.append(model.fit(X, y).predict(X)) # 将回归训练中得到的预测y存入列表
# 模型效果指标评估
n_samples, n_features = X.shape # 总样本量,总特征数
model_metrics_name = [explained_variance_score, mean_absolute_error, mean_squared_e
model_metrics_list = [] # 回归评估指标列表
for i in range(5): # 循环每个模型索引
tmp_list = [] # 每个内循环的临时结果列表
for m in model_metrics_name: # 循环每个指标对象
tmp_score = m(y, pre_y_list[i]) # 计算每个回归指标结果
tmp_list.append(tmp_score) # 将结果存入每个内循环的临时结果列表
model_metrics_list.append(tmp_list) # 将结果存入回归评估指标列表
df1 = pd.DataFrame(cv_score_list, index=model_names) # 建立交叉检验的数据框
df2 = pd.DataFrame(model_metrics_list, index=model_names, columns=['ev', 'mae', 'ms
print ('samples: %d \t features: %d' % (n_samples, n_features)) # 打印输出样本量和特
print (70 * '-') # 打印分隔线
print ('cross validation result:') # 打印输出标题
print (df1) # 打印输出交叉检验的数据框
print (70 * '-') # 打印分隔线
print ('regression metrics:') # 打印输出标题
print (df2) # 打印输出回归指标的数据框
print (70 * '-') # 打印分隔线
print ('short name \t full name') # 打印输出缩写和全名标题
print ('ev \t explained_variance')
print ('mae \t mean_absolute_error')
print ('mse \t mean_squared_error')
print ('r2 \t r2')
print (70 * '-') # 打印分隔线
# 模型效果可视化
plt.figure() # 创建画布
plt.plot(np.arange(X.shape[0]), y, color='k', label='true y') # 画出原始值的曲线
color_list = ['r', 'b', 'g', 'y', 'c'] # 颜色列表
linestyle_list = ['-', '.', 'o', 'v', '*'] # 样式列表
for i, pre_y in enumerate(pre_y_list): # 读出通过回归模型预测得到的索引及结果
plt.plot(np.arange(X.shape[0]), pre_y_list[i], color_list[i], label=model_names[i])
plt.title('regression result comparison') # 标题
plt.legend(loc='upper right') # 图例位置
plt.ylabel('real and predicted value') # y轴标题
plt.show() # 展示图像
# 模型应用
print ('regression prediction')
new_point_set = [[1.05393, 0., 8.14, 0., 0.538, 5.935, 29.3, 4.4986, 4., 307., 21.,
[0.7842, 0., 8.14, 0., 0.538, 5.99, 81.7, 4.2579, 4., 307., 21., 386.75, 14.67],
[0.80271, 0., 8.14, 0., 0.538, 5.456, 36.6, 3.7965, 4., 307., 21., 288.99, 11.69],
[0.7258, 0., 8.14, 0., 0.538, 5.727, 69.5, 3.7965, 4., 307., 21., 390.95, 11.28]] #
for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点
new_pre_y = model_gbr.predict(new_point) # 使用GBR进行预测
print ('predict for new point %d is: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据
上述代码以空行分为6个部分。
第一部分导入库。
本示例中用到的库比较多:numpy用于文件读写和基本数据处理;sklearn.linear_model中的三个广义线性回归下的回归算法BayesianRidge、LinearRegression、ElasticNet,sklearn.svm中的svr回归算法,sklearn.ensemble.gradient_boosting中的GradientBoostingRegressor回归算法;cross_val_score用来做交叉检验;sklearn.metrics下的多个回归模型指标评估方法用来做模型评估;pandas用来做格式化的数据框,便于数据结果输出;Matplotlib用来做预测结果的展示和对比。这里导入多种回归算法,目的是检验在没有先验经验的条件下,通过多个模型的训练,从中找到最佳拟合算法做后续应用。
第二部分数据准备。
使用numpy的loadtxt方法读取数据文件,并使用索引切片功能从数据集中分割出自变量X和因变量y。自变量X拥有506个样本,13个特征变量。
第三部分训练回归模型。
- 本过程使用交叉检验的方法评估不同模型的训练效果。 先设置交叉检验的次数为6(6折交叉检验),后续会在交叉检验模型训练中用到;
- 接着分别建立贝叶斯岭回归(BayesianRidge)、普通线性回归(LinearRegression)、弹性网络回归(ElasticNet)、支持向量机回归(SVR)、梯度增强回归(GradientBoostingRegressor)模型对象,前3个算法属于广义线性回归,后两个属于支持向量机和梯度增强算法的变体;
- 然后分别建立不同模型的名称列表、回归模型对象的集合、交叉检验结果空列表、回归模型预测的y值空列表,分别用于后续名称读取、模型代入交叉检验算法、交叉检验结果数据存储和回归预测的结果存储。
- 最后通过for循环读出每个回归模型对象,对每个回归模型导入交叉检验模型cross_val_score中做训练检验并设置检验6次,并将交叉检验结果通过append方法存入结果列表,将回归训练中得到的预测y通过append方法存入列表。
相关知识点:cross_val_score
cross_val_score是sklearn.model_selection中的交叉检验工具,可以对特定算法模型进行交叉检验。常用参数:
sklearn.model_selection.cross_val_score(estimator, X, y=None, groups=None, scoring=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch='2*n_jobs')
estimator:要应用交叉检验的模型对象,该模型在交叉检验中会通过使用fit方法来训练模型
- X, y:交叉检验的数据集X和目标y,其中X至少是2维数据
- cv:要进行交叉检验的模式。如果cv值为空,那么默认使用3折交叉检验;如果cv值是整数,那么使用按照指定的数量做交叉检验。这两种情况下都会调用model_selection.StratifiedKFold方法实现。如果cv值是用来交叉检验的生成器对象或可迭代的测试和训练集,那么将使用sklearn.model_selection.KFold方法。
- cross_val_score交叉检验后返回的得分默认调用算法模型的score方法做得分估计,因此不同的算法模型其得分计算方法可能有差异,具体取决于模型本身score方法(scorer(estimator, X, y))的计算逻辑。当然,也可以通过设置scoring参数字符串来手动指定得分计算方法,例如cross_val_score(estimator, X, y, scoring='r2', cv=6)。
第四部分模型效果指标评估。
先通过自变量数据集的shape获得总样本量和总特征数;
接着创建一个列表用于存储接下来用到的回归模型评估指标对象,explained_variance_score,mean_absolute_error,mean_squared_error,r2_score,这些对象在第一步导入库时已经导入,因此无需做其他处理便可直接使用;创建用于存储不同回归评估指标的列表。
- explained_variance_score:解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因变量的方差变化,值越小则说明效果越差。
- mean_absolute_error:平均绝对误差(Mean Absolute Error,MAE),用于评估预测结果和真实数据集的接近程度的程度,其其值越小说明拟合效果越好。
- mean_squared_error:均方差(Mean squared error,MSE),该指标计算的是拟合数据和原始数据对应样本点的误差的平方和的均值,其值越小说明拟合效果越好。
- r2_score:判定系数,其含义是也是解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因变量的方差变化,值越小则说明效果越差。
然后通过两层for循环来分别对每个模型和每种回归模型评估方法进行计算。需要注意的是里面有一个用于存储每个内循环的临时结果列表,需要在内循环结束之后,每次将其结果存储到外部循环中的回归评估指标列表。
下面是通过pandas的Dataframe方法分别建立交叉检验和回归指标数据框,然后打印输出样本量和特征数量、交叉检验和回归指标数据框,并通过打印横线来做逻辑输出切分;
为了更好的理解指标的含义,打印输出缩写和全名标题对照表。在打印过程中使用的方法跟聚类中的类似,但是对于格式化的输出,这里使用了pandas的数据框,这样如果数据量比较多的情况下,更容易控制。输出结果如下:
samples: 506 features: 13
\--------------------------------------------------------------------------
cross validation result:
0 1 2 3 4 5
BayesianRidge 0.662422 0.677079 0.549702 0.776896 -0.139738 -0.024448
LinearRegression 0.642240 0.611521 0.514471 0.785033 -0.143673 -0.015390
ElasticNet 0.582476 0.603773 0.365912 0.625645 0.437122 0.200454
SVR -0.000799 -0.004447 -1.224386 -0.663773 -0.122252 -1.374062
GBR 0.747920 0.809555 0.767936 0.862972 0.375267 0.559758
\--------------------------------------------------------------------------
regression metrics:
ev mae mse r2
BayesianRidge 0.731143 3.319204 22.696772 0.731143
LinearRegression 0.740608 3.272945 21.897779 0.740608
ElasticNet 0.686094 3.592915 26.499828 0.686094
SVR 0.173548 5.447960 71.637552 0.151410
GBR 0.975126 1.151773 2.099835 0.975126
\--------------------------------------------------------------------------
short name full name
ev explained_variance
mae mean_absolute_error
mse mean_squared_error
r2 r2
通过结果可以看出,增强梯度(GBR)回归是所有模型中拟合效果最好的,表现在能解释97%的方差变化,并且各个误差项的值都是最低的。另外,还有一个重要因素是,梯度增强算法在测试的6次中,其结果相对稳定性较高,这也说明了该算法在应对不同数据集的稳定效果。指标中r2跟ev的值是相同的,原因是r2作为判定系数,本身就是解释方差的比例,含义相同。
第五部分模型效果可视化。
该部分使用Matplotlib将原始数据y和其他5个回归模型预测到的y值通过趋势图进行对比。
先通过figure方法创建画布,然后画出原始数据y的分布,其中画图所需的x值域,使用自变量集X的形状得到一个自增数字列表。
接着画出其他5个回归预测结果展示所需要的颜色列表、样式列表,并通过for集合plot方法循环画出每个预测结果趋势线。
最后设置图形标题、图例位置(右上角)、y轴标题并展示图像
注意 不要忘记设置图像位置,否则即使在plot方法中设置了label值(图例标签值),也会由于缺少图例位置而无法显示图例。
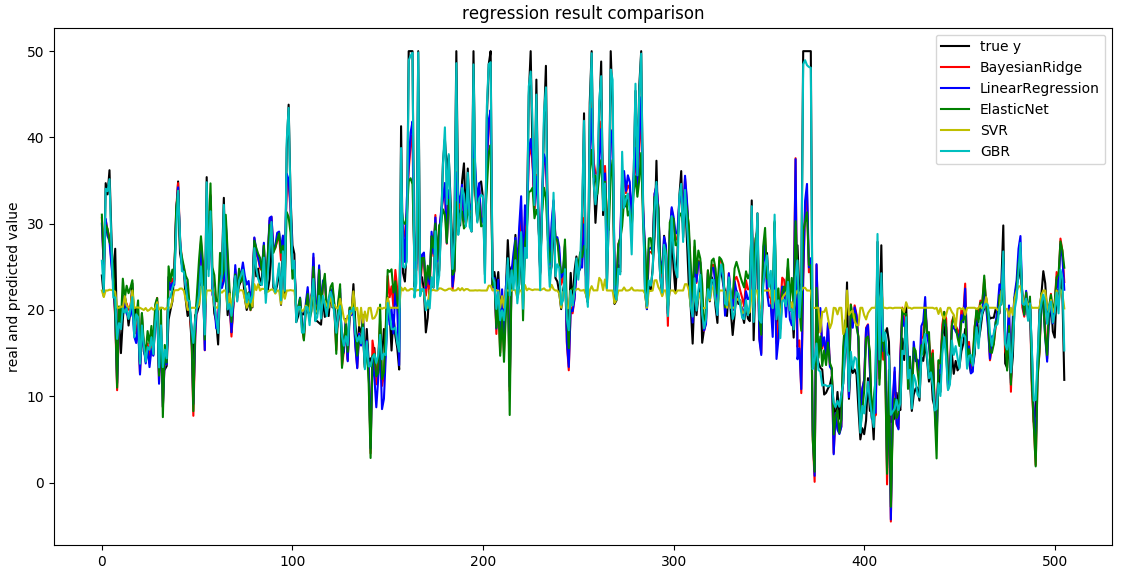
从图中看出,梯度增强算法(青色)的拟合程度跟原始数据(黑色)最接近,这也印证了在上面指标中输出的结果。
第六部分模型应用。
基于新给出的包含多个数据点的数据集,我们要预测未来值,直接使用for循环读出每个数据,然后使用最优回归模型梯度增强的predict方法做预测,得到如下结果:
predict for new point 1 is: 21.49
predict for new point 2 is: 16.84
predict for new point 3 is: 19.50
predict for new point 4 is: 19.16
上述过程中,主要需要考虑的关键点是:如何在样本维度较多的情况下,选择最佳的回归模型,这里我们使用了多个模型,并结合交叉检验的方法找到最优的回归方法。
麻烦你把错误截图和执行信息,截图或发到下面留言,谢谢。
您好,仔细阅读了您这篇文章之后我收获很大,但仍有一些问题潘您解答。 我注意到整个回归过程没有划分测试集,这是因为进行交叉验证之后已经得到良好的参数,不需要再在测试集上进行验证了吗? 不划分测试集的话,r2,mse这些指标是用数据集中所有X对应的y_predict和true_y计算的吗? 如果是的话,模型在训练的过程中就已经认识过了整个数据集,会不会造成信息泄露,导致验证过程不准确呢?
你好。感谢提出详细的疑问。 在案例里面的核心其实就是“cross_val_score”。我想你的疑问是,没有手动拆分训练集和测试集,直接使用cross_val_score方法,是否会产生问题。 在cross_val_score方法中,核心是通过cv参数控制交叉检验的方法,案例中使用n_folds=6设置了6折交叉检验。 所以,在训练过程中,会自动将所有数据集拆分为6次,每次里面都包含训练集和测试集。然后用里面的训练集训练模型,用测试集验证模型。 所以,由于【不使用全部数据集】做验证,也就不存在泄露的问题。 其实cross_val_score里面也可以手动传入你拆分后的训练集和测试集,原理是一样的。具体可以看下API:https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html#sklearn.model_selection.cross_val_score
写的真的很好,体现了python的简洁美,但却十分详细,涵盖的知识点也很多,适合我这样的初学者深入。再次感谢。
谢谢支持
老师您好,“附件-chapter4”好像失效了,可以重新发一下吗?非常想学习您的方法,谢谢!
下载地址
第一版的书籍附件,在这里面可以下哈。
老师为什么我运行自己的数据显示list index out of range
这个具体要看你的数据是什么,另外你是怎么写的语法。贴下代码,截图下报错。
请问怎么增加代码,能够输出回归系数,进而写出线性回归方程
你提到的“线性方程”,仅仅适用于当svr的内核是线性内核(linear)时才能用。通过实例对象的coef_ 和intercept_ 分别获得参数和截距信息就好的。
您好!我认为最后一部分的代码应该修改一下,因为我按照源代码实现的话会报错: ValueError: Expected 2D array, got 1D array instead: array=[ 1.05393 0. 8.14 0. 0.538 5.935 29.3 4.4986 4. 307. 21. 386.85 6.58 ]. Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample. =============================================================
模型应用
print ('regression prediction') new_point_set = np.array([[1.05393, 0., 8.14, 0., 0.538, 5.935, 29.3, 4.4986, 4., 307., 21., 386.85, 6.58], [0.7842, 0., 8.14, 0., 0.538, 5.99, 81.7, 4.2579, 4., 307., 21., 386.75, 14.67], [0.80271, 0., 8.14, 0., 0.538, 5.456, 36.6, 3.7965, 4., 307., 21., 288.99, 11.69], [0.7258, 0., 8.14, 0., 0.538, 5.727, 69.5, 3.7965, 4., 307., 21., 390.95, 11.28]]) # 要预测的新数据集 for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点 new_point=new_point.reshape(1,-1) new_pre_y = model_gbr.predict(new_point) # 使用GBR进行预测 print ('predict for new point %d is: %.2f' % (i + 1, new_pre_y)) # 打印输出每个数据点的预测信息
你好。感谢提出。是的,在最新版本中,该问题已经修复。
非常感谢!!!
倒数第二行前面应该增加 new_point=np.array(new_point).reshape(1,13)
是的,Python3中必须这样做了。
老师好,刚学习机器学习的菜鸟,看完这篇收获很大,写的很详细。我想请教一下有没有训练多元回归的算法,我现在的数据集是两个特征变量对应一个因变量,然后我想训练得出一个模型,输入两个自变量计算出来因变量(就是代表两个自变量之间的关系),老师上述讲的算法可以实现吗?如果可以的话是再加一个X吗?如果不可以的话,目前有哪些比较好的算法呢?谢谢老师!
可以的。自变量输入几个其实都可以,只是如果自变量数量多了,你就不能靠观察获得目标模型了。得靠交叉检验来做评估和测试。 回归算法很多,比如SVR、LR、广义线性回归的各种库、各种树和基于库的集成库(例如CART、GBDT、XGB等)。 更多详细的,你可以看下我的书里面,有专门关于回归算法和应用的介绍。
预测新的点
print ('regression prediction') new_point_set = np.array([[1.05393, 0., 8.14, 0., 0.538, 5.935, 29.3, 4.4986, 4., 307., 21., 386.85, 6.58], [0.7842, 0., 8.14, 0., 0.538, 5.99, 81.7, 4.2579, 4., 307., 21., 386.75, 14.67], [0.80271, 0., 8.14, 0., 0.538, 5.456, 36.6, 3.7965, 4., 307., 21., 288.99, 11.69], [0.7258, 0., 8.14, 0., 0.538, 5.727, 69.5, 3.7965, 4., 307., 21., 390.95, 11.28]]) # 要预测的新数据集 for i, new_point in enumerate(new_point_set): # 循环读出每个要预测的数据点 new_point=np.array(new_point).reshape(1,13) new_pre_y = model_gbr.predict(new_point) # 使用GBR进行预测 print ('predict for new point %d is: %.2f' % (i+1, new_pre_y)) # 打印输出每个数据点的预测信息 regression prediction predict for new point 4 is: 19.16 >>> 您好,我用您的代码预测新的点时,只输出最后一个点,这是为什么呢
Hi 王平, 最后预测输出是用for循环实现的,由于是每个值单独遍历出来的,所以每次循环都会输出值。 你提到的只有一个值输出的情况,我没有遇到。你可以加我微信,我具体看下子问题。
请问源数据是已经标准化了吗
没有做标准化处理。 所以,在用到回归模型时,模型的结果在很多情况下会受到量纲的影响。尤其是广义线性回归下的所有回归库,而集成方法库则不会受影响。
您好,我刚开始接触Python,要使用SVR,想请教您一些问题。您的程序应该是直接调用SVR,核函数是直接用的rbf吗?那最后得到的SVR模型的参数怎么查看呢,比如C,epsilon,gamma。那这些参数是最优的吗?打扰了。
所有的python对象,你可以直接通过 print('实例名') 来得到具体信息,包括你提到的模型的参数。 参数不是最优的,最优参数需要通过交叉检验来得到,这里是没有的。 关于最优参数如何获取的问题,我在书里面有提到,例如交叉检验、集成方法、手动指定等你有兴趣可以去看下子。
为什么我做出来的回归预测图 四种回归线不在一个图上而是分成了四个图呢???
是我把循环结构弄错了 已经解决了
^_^ 没关系