sklearn中没有一个专门的分类算法库,分类算法分散在不同的方法库中,例如ensemble、svm、tree等,在使用时需要分别导入不同的库来使用其中的分类算法。
示例模拟的是针对一批带有标签的数据集做分类模型训练,然后使用该模型对新数据集做分类预测;主要使用sklearn做分类、用matplotlib做图形展示
另外,本节会用到两个新的图形和表格展示库:prettytable和pydotplus,以及配合pydotplus的GraphViz程序。
prettytable是用来做表格格式化输出展示的,它的好处是可以非常容易的对行、列进行控制,并且输出带有分割线的可视化table。
第一次使用该库需要先通过系统终端命令行窗口(或PyCharm中底部的Terminal窗口)使用pip install prettytable在线安装,安装成功后在Python命令行窗口输入import prettytable无报错信息则该库已经正确安装。
pydotplus是在决策树规则输出时用到的库,其输出的dot数据可以供GraphViz绘图使用。要能完整使用该库需要先安装GraphViz程序,然后再安装pydotplus。
第一步
安装GraphViz程序。这是一个额外的应用程序,而不是一个Python附属包或程序。读者可登陆http://www.graphviz.org/Download.php下载,第一次登陆该网站时需要阅读一堆内容须知,阅读完之后可直接点击底部的Agree,然后到达下载程序窗口,在该窗口中按照不同的操作环境选择下载或安装方式。笔者的电脑是Windows,选择的是“graphviz-2.38.msi”。下载完成之后的安装过程没有任何难点。
第二步
安装pydotplus。这是一个从dot数据读取数据格式并保存为可视化图形的库,在系统中打开系统终端命令行窗口(或PyCharm中底部的Terminal窗口)输入pip install pydotplus,几秒钟之内就能完成自动下载安装过程。
完整代码如下:
# 导入库
import numpy as np # 导入numpy库
from sklearn.model_selection import train_test_split # 数据分区库
from sklearn import tree # 导入决策树库
from sklearn.metrics import accuracy_score, auc, confusion_matrix, f1_score, precision_score, recall_score, \
roc_curve # 导入指标库
import prettytable # 导入表格库
import pydotplus # 导入dot插件库
import matplotlib.pyplot as plt # 导入图形展示库
# 数据准备
raw_data = np.loadtxt('classification.csv', delimiter=',', skiprows=1, ) # 读取数据文件
X = raw_data[:, :-1] # 分割X
y = raw_data[:, -1] # 分割y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3, random_state=0) # 将数据分为训练集和测试集
17. # 训练分类模型
model_tree = tree.DecisionTreeClassifier(random_state=0) # 建立决策树模型对象
model_tree.fit(X_train, y_train) # 训练决策树模型
pre_y = model_tree.predict(X_test) # 使用测试集做模型效果检验
# 输出模型概况
n_samples, n_features = X.shape # 总样本量,总特征数
print ('samples: %d \t features: %d' % (n_samples, n_features)) # 打印输出样本量和特征数量
print (70 * '-') # 打印分隔线
# 混淆矩阵
confusion_m = confusion_matrix(y_test, pre_y) # 获得混淆矩阵
confusion_matrix_table = prettytable.PrettyTable() # 创建表格实例
confusion_matrix_table.add_row(confusion_m[0, :]) # 增加第一行数据
confusion_matrix_table.add_row(confusion_m[1, :]) # 增加第二行数据
print ('confusion matrix')
print (confusion_matrix_table) # 打印输出混淆矩阵
# 核心评估指标
y_score = model_tree.predict_proba(X_test) # 获得决策树的预测概率
fpr, tpr, thresholds = roc_curve(y_test, y_score[:, 1]) # ROC
auc_s = auc(fpr, tpr) # AUC
accuracy_s = accuracy_score(y_test, pre_y) # 准确率
precision_s = precision_score(y_test, pre_y) # 精确度
recall_s = recall_score(y_test, pre_y) # 召回率
f1_s = f1_score(y_test, pre_y) # F1得分
core_metrics = prettytable.PrettyTable() # 创建表格实例
core_metrics.field_names = ['auc', 'accuracy', 'precision', 'recall', 'f1'] # 定义表格列名
core_metrics.add_row([auc_s, accuracy_s, precision_s, recall_s, f1_s]) # 增加数据
print ('core metrics')
print (core_metrics) # 打印输出核心评估指标
# 模型效果可视化
names_list = ['age', 'gender', 'income', 'rfm_score'] # 分类模型维度列表
color_list = ['r', 'c', 'b', 'g'] # 颜色列表
plt.figure() # 创建画布
# 子网格1:ROC曲线
plt.subplot(1, 2, 1) # 第一个子网格
plt.plot(fpr, tpr, label='ROC') # 画出ROC曲线
plt.plot([0, 1], [0, 1], linestyle='--', color='k', label='random chance') # 画出随机状态下的准确率线
plt.title('ROC') # 子网格标题
plt.xlabel('false positive rate') # X轴标题
plt.ylabel('true positive rate') # y轴标题
plt.legend(loc=0)
# 子网格2:指标重要性
feature_importance = model_tree.feature_importances_ # 获得指标重要性
plt.subplot(1, 2, 2) # 第二个子网格
plt.bar(np.arange(feature_importance.shape[0]), feature_importance, tick_label=names_list, color=color_list) # 画出条形图
plt.title('feature importance') # 子网格标题
plt.xlabel('features') # x轴标题
plt.ylabel('importance') # y轴标题
plt.suptitle('classification result') # 图形总标题
plt.show() # 展示图形
# 保存决策树规则图为PDF文件
dot_data = tree.export_graphviz(model_tree, out_file=None, max_depth=5, feature_names=names_list, filled=True,
rounded=True) # 将决策树规则生成dot对象
graph = pydotplus.graph_from_dot_data(dot_data) # 通过pydotplus将决策树规则解析为图形
graph.write_pdf("tree.pdf") # 将决策树规则保存为PDF文件
# 模型应用
X_new = [[40, 0, 55616, 0], [17, 0, 55568, 0], [55, 1, 55932, 1]]
print ('classification prediction')
for i, data in enumerate(X_new):
y_pre_new = model_tree.predict(data)
print ('classification for %d record is: %d' % (i + 1, y_pre_new))
上述代码以空行分为9个部分。
第一部分导入库。
本示例中使用了sklearn的tree库做分类预测、metrics库做分类指标评估、model_selection库做数据分区,使用numpy辅助于数据读取和处理,使用prettytable库做展示表格的格式化输出,使用pydotplus来生成决策树规则树形图,使用matplotlib的pyplot库做图形展示。
第二部分数据准备。
使用numpy的loadtxt方法读取数据文件,指定分隔符以及跳过第一行标题名;然后使用矩阵索引将数据分割为X和y,最后使用sklearn.model_selection 的train_test_split方法将数据分割为训练集和测试集,训练集数量占总样本量的70%。
相关知识点:将数据集划分为训练集、测试集和验证集
第二部分中将数据集划分为训练集和测试集两部分,在很多场景中需要将数据集分为训练集、测试集和验证集三部分。sklearn没有提供直接将数据集分为3种(含3种)以上的方法,我们可以使用numpy的split方法划分数据集。split参数如下:
split(ary, indices_or_sections, axis=0)
- ary:要划分的原始数据集
- indices_or_sections:要划分的数据集数量或自定义索引分区。如果直接使用整数型数值设置分区数量,则按照设置的值做等比例划分;如果设置一个一维的数组,那么将按照设置的数组的索引值做区分划分边界。
- axis:要划分数据集的坐标轴,默认是0
数据集分割示例:将创建的新数据集通过平均等分和指定分割索引值的方式分为3份
import numpy as np # 导入库
x = np.arange(72).reshape((24,3)) # 创建一个24行3列的新数组
train_set1, test_sets1, val_sets1 = np.split(x, 3) # 将数组平均分为3份
train_set2, test_sets2, val_sets2 = np.split(x, [int(0.6*x.shape[0]), int(0.9*x.shape[0])]) # 60%
print ('record of each set - equal arrays: ')
print ('train_set1: %d, test_sets1: %d, val_sets1: %d'%(train_set1.shape[0], test_sets1.shape[0],
print (40*'-')
print ('record of each set - % arrays: ')
print ('train_set2: %d, test_sets2: %d, val_sets2: %d'%(train_set2.shape[0], test_sets2.shape[0],
上述代码执行后,返回如下结果:
record of each set - equal arrays:
train_set1: 8, test_sets1: 8, val_sets1: 8
\----------------------------------------
record of each set - % arrays:
train_set2: 14, test_sets2: 7, val_sets2: 3
第三部分训练分类模型。使用sklearn.tree中的DecisionTreeClassifier方法建立分类模型并训练,然后基于测试集做数据验证。DecisionTreeClassifier为CART(分类回归树),除了可用于分类,还可以用于回归分析。
相关知识点:tree 算法对象中的决策树规则
在决策树算法对象的tree_属性中,存储了所有有关决策树规则的信息(示例中的决策树规则存储在model_tree.tree_中)。最主要的几个属性:
- children_left:子级左侧分类节点
- children_right:子级右侧分类节点
- feature:子节点上用来做分裂的特征
- threshold:子节点上对应特征的分裂阀值
- values:子节点中包含正例和负例的样本数量
上述属性配合节点ID、节点层级便迭代能得到如下的规则信息:
[label="rfm_score <= 7.8375\ngini = 0.1135\nsamples = 14581\nvalue = [13700, 881]", fillcolor="#e58139ef"] ;
其中规则开始的1代表节点ID,rfm_score是变量名称,rfm_score <= 7.8375是分裂阀值,gini = 0.1135是在当前规则下的基尼指数,nsamples是当前节点下的总样本量,nvalue为正例和负例的样本数量。
第四部分输出模型概况。
由于分类算法评估内容较多,因此从这里开始将分模块输出内容以便于区分。本部分内容中,通过X的形状获得数据的样本量和特征数量,打印输出结果如下:
samples: 21927 features: 4
第五部分输出混淆矩阵。
使用sklearn.metrics中的confusion_matrix方法,通过将测试集的训练结果与真实结果的比较得到混淆矩阵。接下来通过prettytable展示混淆矩阵并输出表格,该库会自动对表格进行样式排版,并通过多种方法指定列表、样式等输出样式:先建立PrettyTable方法表格对象,然后使用add_row方法追加两行数据,打印输出结果如下:
confusion matrix
+---------+---------+
| Field 1 | Field 2 |
+---------+---------+
| 5615 | 284 |
| 321 | 359 |
+---------+---------+
第六部分输出分类模型核心评估指标。
先通过决策树模型对象的predict_proba方法获得决策树对每个样本点的预测概率,该数据在下面的ROC中用到;输出的概率信息可作为基于阀值调整分类结果输出的关键,例如可自定义阀值来做进一步精细化分类类别控制。
接着通过sklearn.metrics的roc_curve、auc、accuracy_score、precision_score、recall_score、f1_score分别得到AUC、准确率、精确度、召回率、F1得分值。
- auc_s:AUC(Area Under Curve),ROC曲线下的面积。ROC曲线一般位于y=x上方,因此AUC的取值范围一般在5和1之间。AUC越大,分类效果越好。
- accuracy_s:准确率(Accuracy),分类模型的预测结果中将正例预测为正例、将负例预测为负例的比例,公式为:A = (TP + TN)/(TP + FN + FP + TN),取值范围[0,1],值越大说明分类结果越准确。
- precision_s:精确度(Precision),分类模型的预测结果中将正例预测为正例的比例,公式为:P = TP/(TP+FP),取值范围[0,1],值越大说明分类结果越准确。
- recall_s:召回率(Recall),分类模型的预测结果被正确预测为正例占总的正例的比例,公式为:R = TP/(TP+FN),取值范围[0,1],值越大说明分类结果越准确。
- f1_s:F1得分(F-score),准确度和召回率的调和均值,公式为:F1 = 2 * (P * R) / (P + R),取值范围[0,1],值越大说明分类结果越准确。
上述指标计算完成后仍然通过prettytable的PrettyTable方法创建表格对象,然后使用field_names定义表格的列名,通过add_row方法追加数据,打印输出结果如下:
core metrics
+----------------+----------------+---------------+----------------+------
| auc | accuracy | precision | recall | f1 |
+----------------+----------------+---------------+----------------+------
| 0.749870117567 | 0.908040735674 | 0.55832037325 | 0.527941176471 | 0.542705971277 |
+----------------+----------------+---------------+----------------+------
从上述指标可以看出整个模型效果一般,一方面,在建立模型时,我们没有对决策树剪枝,这会导致决策树的过拟合问题;另一方面,原始数据中,存在明显的样本类别不均衡问题,也没有做任何预处理工作。由于这里仅做算法流程演示,关于调优的部分不展开讲解。
第七部分模型效果可视化
目标是输出变量的重要性以及ROC曲线。
建立分类模型维度列表和颜色列表,用于图形展示;然后通过figure方法创建画布。
- 子网格1:ROC曲线。使用subplot方法定义第一个子网格,其中“1,2,1”表示1行2列的第一个子网格,使用plot方法分别画出模型训练得到的ROC曲线和随机状态下的准确率线,使用title、xlabel、ylabel分别设置子网格标题、X轴和Y轴标题。在使用legend方法设置图例时,使用loc=0来让图表选择最佳位置放置图例。
- 子网格2:指标重要性。该子网格的位置是1行2列的第二个区域,其设置与子网格1基本相同,差异点在于这里使用了bar方法创建条形图。
上述代码返回如下图形结果:
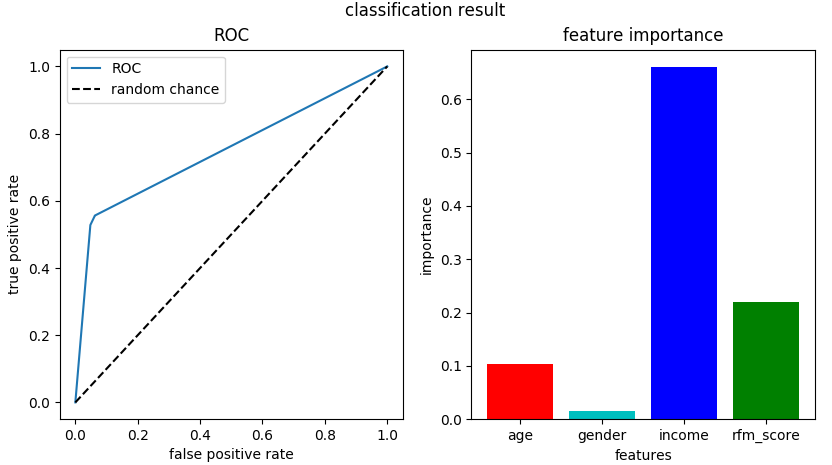
从上述结果可以看出,ROC曲线的面积大于0.5,模型的算法结果比随机抽取的准确率要高,但综合前面我们得到的准确率指标,结果也不是特别理想。在特征重要性中,income变量具有非常高的特征权重,是这几个变量中最重要的变量,其次是rfm_score和age。
第八部分保存决策树规则图为PDF文件。
先通过tree库下的export_graphviz方法,将决策树规则生成dot对象,各参数作用如下:
- out_file=None用来控制不生成dot文件,否则对象dot_data会为空;
- max_depth 控制导出分类规则的最大深度,防止规则过多导致信息碎片化;
- feature_names来指定决策树规则的每个变量的名称,方便在决策树规则中识别特征名称;
- filled方法控制填充,让图形效果更佳美化;
- rounded来控制字体样式。
上述代码执行后,会在python工作目录产生一个新的名为“tree.pdf”的文件,打开PDF文件,部分内容如下:
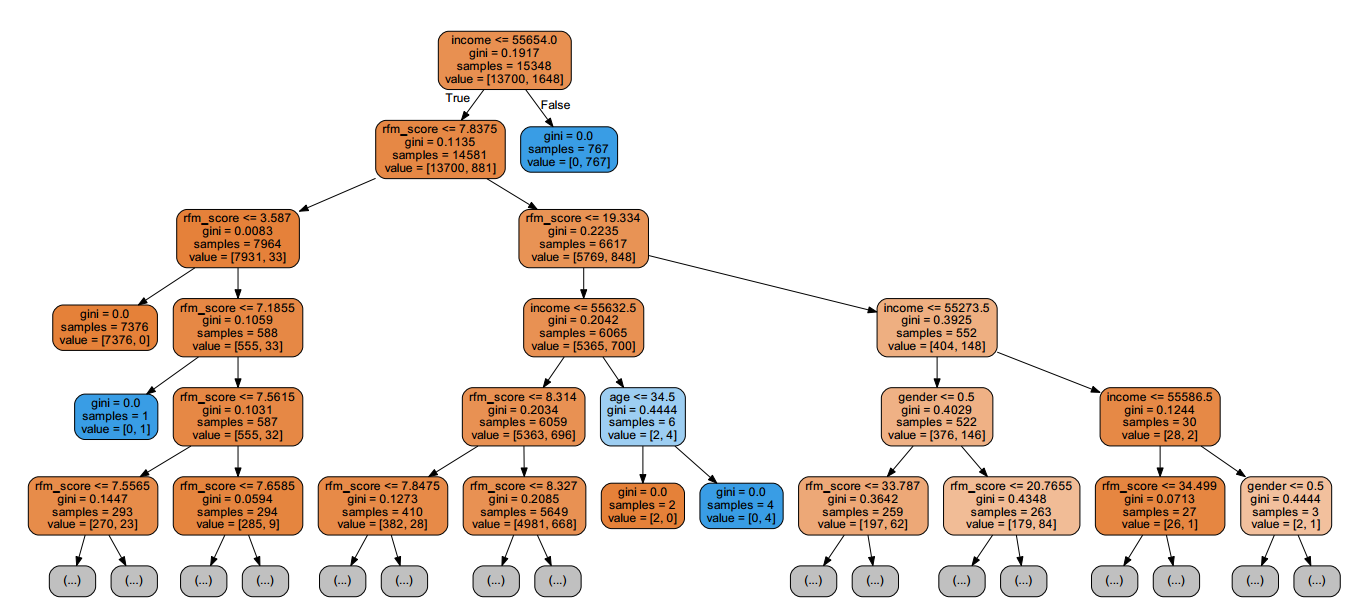
提示 在sklearn的tree库中,有一个特殊的方法tree.export_graphviz可用来讲树形规则结构转化为DOT格式的数据对象,该方法只有tree库中有。在dot_data变量的代码中,可去掉out_file=None参数,默认会生成一个名tree.dot的数据文件,该文件就是上述树形图输出的源数据。
上述决策树规则显示了当income<=55654时,总样本量为15348,其中负例样本和正例样本分别为13700、1648。当income<=55654且rfm_score<=7.8375时,总样本量有13581,其中负例样本和正例样本分别为13700、881。以此类推可以读出其他的规则。
第九部分模型应用。
通过将新的数据集放入模型做分类预测,得到每个数据集的预测类别指标,结果如下:
classification prediction
classification for 1 record is: 0
classification for 2 record is: 0
classification for 3 record is: 1
你好,我想问一下为什么y_score为什么基本上都是0或1,是过拟合了,啊
你说的 是这句吧:
y_score = model_tree.predict_proba(X_test) # 获得决策树的预测概率y_score 输出的是概率值,是[0,1]之间的,你使用excel看的吧,默认是整数。 另外,过拟合也不是01的问题,而是在训练时过多使用特征,到测试的时候效果很差。意思是,模型的鲁棒性效果差,而不是01的问题。