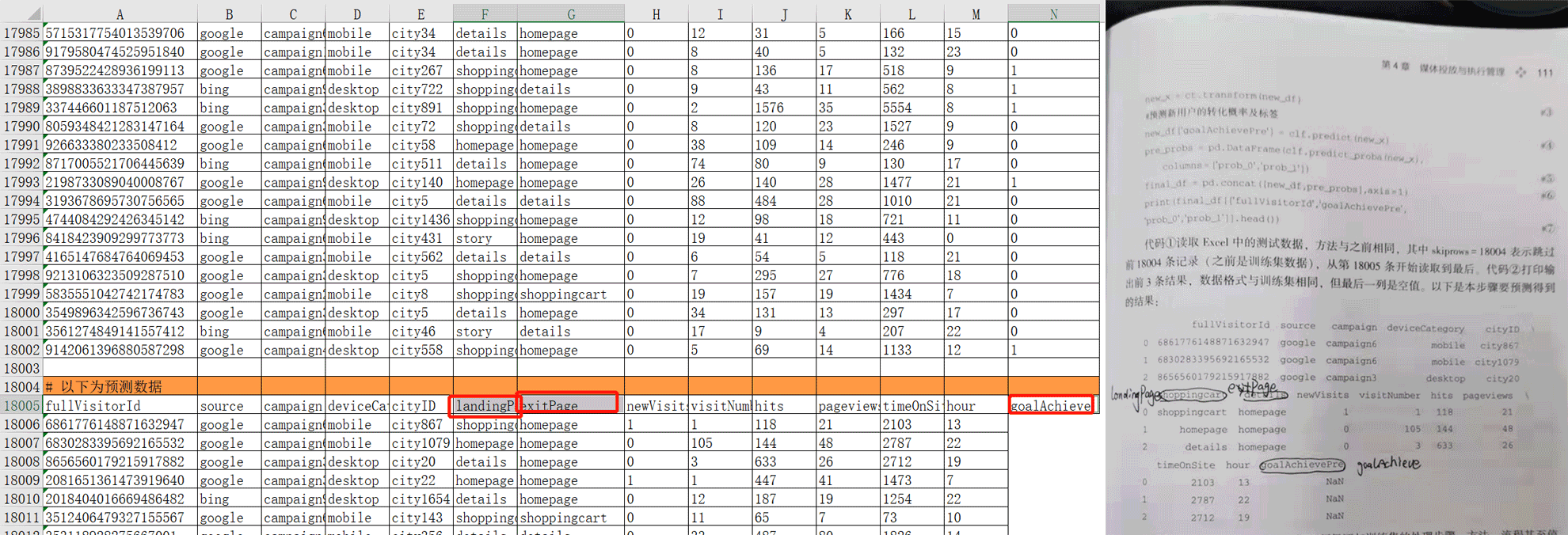
6.3.1 渠道效果边际变化规律概述
营销渠道效果的一个基本规律是,当营销投入变化时,其产生的营销效果也是变化的,且变化可能不是线性的,而是呈现特定的边际效应。例如:当广告费用持续增加时,转化率在缓慢下降;当流量规模增加时,单位流量的成本却在上升。找到不同渠道的边际效应规律,有利于增加对渠道的认知并能更好的控制营销资源的投入并使企业回报最大化。
6.3.2 分析渠道回报效率的边际递减效应
随着营销渠道广告费用的增加,其回报效率可能出现边际递减效应,回报效率可以是转化率、ROI等转化效率类的指标。例如,当广告费用在10万量级时,每1000块钱能带来10个订单;当广告费用增加到100万量级时,每1