在渠道效果分析中,找到影响效果转化的主要因素是重中之重。它能直接帮助营销人员更好的了解渠道转化的影响因素,以及如何进行渠道效果优化和提升;同时,还可以基于分析得到的业务规则,直接应用到营销投放和操作过程,因此落地性和价值度都非常高。
该节内容可应用于任何带有转化目标的渠道中,且转化的定义可以包含任何目标场景,例如:
- 动作场景:提交订单、按钮点击、线索填写、注册、登陆、抽奖等事件。
- 非动作场景:停留超过30秒、看过超过10个页面、浏览过特定页面等过程性行为。
7.2.1 渠道效果影响因素概述
在“4.1.4 基于Lookalike的人群规则实现投放人群管理”中介绍了如何通过模型提取营销目标人群的列表;同时也通过“特征重要性”展示了哪些特征对于用户转化最为重要。“特征重要性”的具体含义,对于一般业务人员来讲比较难以理解,这里介绍一种新的解释影响重要程度的度量值——Shapley Values。
Shapley Values来源于博弈论,它将整个模型训练作为一局博弈,每个特征当作一个博弈者,而预测结果则是最终的结果。Shapley Values用来判断每个特征对预测结果做出了多大的贡献。这里引用一则的寓言故事来简单说明Shapley Values的计算逻辑。
约克和汤姆一起去旅游并准备吃午餐。约克带了3块饼,汤姆带了5块饼。这时,他们邀请一个路人一起吃饭。约克、汤姆和路人将8块饼全部吃完。路人送了8个金币来感谢他们的午餐。
约克和汤姆为这8个金币的分配发生了争执。汤姆认为自己带了5块饼,理应得5个金币,剩下3个金币给约克。约克则认为既然大家一起吃这8块饼,理应平分8个金币,即每人4个。
夏普里(Shapley)告诉约克,从公正的角度看,约克应当得到1个金币,而汤姆应当得到7个金币。原因是约克带了3块饼,汤姆带了5块,3个人一起吃了8块饼。约克吃了其中的1/3,即8/3块;路人吃了约克带的饼中的3-8/3=1/3;汤姆也吃了8/3,路人吃了他带的饼中的5-8/3=7/3。这样,路人所吃的8/3块饼中,有约克的1/3,汤姆的7/3。路人所吃的饼中,属于汤姆的是属于约克的7倍。因此,对于这8个金币,公平的分法是:约克得1个金币,汤姆得7个金币。
我们从这个故事中看出,夏普里(Shapley)所提出的对金币的“公平的”分法,遵循的原则是:所得与自己的贡献相等。这就是Shapley Values的含义。
7.2.2 分析特征对转化目标的正负向影响
本案例使用附件“第4章”-“4-1”数据,该数据与“4.1 基于Lookalike的投放人群管理”案例相同。
第一步 导入库
import pandas as pd #①
from sklearn.tree import DecisionTreeClassifier #②
import shap #③
shap.initjs() #④
代码①导入的pandas库用来读取和处理数据。代码②导入的DecisionTreeClassifier是的决策树模型,用来做分类训练使用。代码③导入shap用来解释模型信息,读者可使用pip install shap安装该库。代码④在Jupyter notebook环境下,加载用于shap可视化的JS代码。
第二步 准备数据
df = pd.read_excel('第4章.xlsx',sheet_name='4-1',comment='#',nrows=1000)#①
x = df[['newVisits', 'hits','pageviews','timeOnSite','hour']] #②
y = df['goalAchieve'] #③
代码①使用pandas的read_excel从附件第4章中读取名为4-1的工作簿,读取前1000行数据。代码②和③分别将要分析的字段获取出来,这里为了分析方便只选取少量的字段。
第三步 训练模型
clf =DecisionTreeClassifier(random_state=0) #①
clf.fit(x,y) #②
代码①调用DecisionTreeClassifier创建一个决策树对象,random_state=0表示固定初始化随机种子的值。代码②调用该对象的fit方法,将x和y传入模型中训练。
第四步 创建解释模型
explainer = shap.TreeExplainer(clf) #①
shap_values = explainer.shap_values(x) #②
代码①基于shap的TreeExplainer方法,创建一个用于树模型的解析对象explainer。代码②传入特征矩阵,计算SHAP值。
为了更好的了解shap值,通过如下代码构建数据框并做描述性统计分析。
shap_df = pd.DataFrame(shap_values[1],columns=x.columns) #①
print(shap_df.head(3)) #②
print(shap_df.describe()) #③
代码①构建了一个由shap值组成的数据框,列名与训练数据相同;由于shap_values返回的是一个包含了正负关系的列表,这里只保留正向预测结果shap数据,即列表中的第二组结果;代码②打印数据的前3条记录如下,其中正数表示有正向贡献,负数表示负向贡献:
newVisits hits pageviews timeOnSite hour
0 0.0 -0.078217 0.009828 -0.093882 -0.024729
1 0.0 -0.250762 0.054761 0.258116 -0.249115
2 0.0 0.051621 -0.042187 -0.176401 -0.020033
代码③调用数据框的describe方法做描述性统计,并打印输出,结果如下:
newVisits hits pageviews timeOnSite hour
count 1000.0 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.0 -0.008398 -0.009334 0.019369 -0.001636
std 0.0 0.147385 0.114187 0.219804 0.087543
min 0.0 -0.401172 -0.466117 -0.370827 -0.309737
25% 0.0 -0.081857 -0.038209 -0.136498 -0.026109
50% 0.0 -0.022047 -0.012394 -0.056446 -0.005865
75% 0.0 0.056337 0.022589 0.111852 0.021564
max 0.0 0.521093 0.427002 0.772954 0.406068
第五步 分析特征对转化目标的正负向影响
shap.summary_plot(shap_values, x, plot_type="bar") #①
print(shap_df.abs().mean(axis=0).to_frame().T) #②
print(pd.DataFrame([clf.feature_importances_],columns=x.columns))#③
代码①使用summary_plot来展示原始数据特征计算后的shap值,计算逻辑为每个特征原始shap值先取绝对值,然后求均值;plot_type="bar"设置特征按shap计算结果展示条形图。
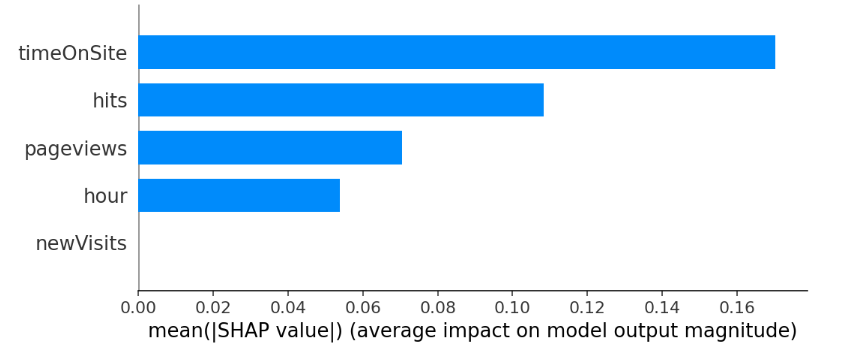
图7-2 shape特征重要程度柱形图
图7-2横坐标轴是特征的shap值的绝对值的均值,值越大代表越重要;纵坐标轴是特征,图形图越长表示越重要。图中timeOnSite最重要,其次是hits,最不重要的特征是newVisits。
代码②对图7-2中的特征重要性进行还原:先对shap_df调用abs方法求出绝对值,然后调用mean方法并通过axis=0指定按列计算均值,使用to_frame方法转换为数据框,使用T方法做转换,从多行一列转换为一行多列,便于展示结果。结果可以与图7-2的shap重要性结合起来一起分析。
newVisits hits pageviews timeOnSite hour
0.0 0.108243 0.070411 0.170209 0.053877
代码③输出原始决策树模型的特征重要性,便于与shap计算结果比较。通过pd.DataFrame 创建一个数据框,值为通过clf.feature_importances_属性取出的特征重要性结果,列名与训练集特征相同,结果如下:
newVisits hits pageviews timeOnSite hour
0.0 0.285795 0.171114 0.391201 0.15189
通过代码②和代码③的输出结果对比,虽然二者的值不同(原因是计算方法不同),但得到的结论趋势是一致的,特征间的大小排序为:timeOnSite> hits> pageviews > hour> newVisits。
为了更详细的展示每个特征对最终结果的影响,可以通过如下代码输出图形:
shap.summary_plot(shap_values[1], x)
如图7-3,上述代码的功能与之前的shap特征重要性的条形图相同,但展示的结果是一个类似散点图+条形图的结果。图中横坐标轴是shap原始值,值从左到右增大;右侧纵轴是特征值分布,特征值越大时颜色越深;图中间的三点为样本点,样本越聚集,则形成的区块面积越大。
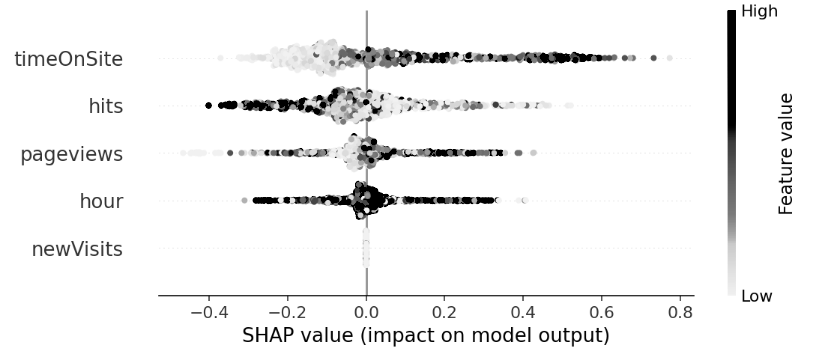
图7-3 特征shape值排序
从图7-3可以看出,对所有渠道数据样本而言,各个特征对转化目标预测的影响如下:
- Shap值会随着timeOnSite值的增加而增大,即二者具有较强的正向线性关系,因此更大的timeOnSite更利于对目标转化产生积极贡献;
- Shap值会随着hits值的增加而下降,二者具有较强的负向线性关系,因此更小的hits值更利于对目标转化产生积极贡献;
- Shap值总体上会随着pageviews的增加而增加,但在shap=0的位置附近存在大量的样本点,说明这些点对于shap值的增加没有贡献。
- Shap值总体上增加或下降与hour的变化关系较弱,当hour值很大时会对shap值有正向和负向不同的作用。
- Shap值与newVisits分布无明显关系,所有的数据都集中在shap=0的位置附近,即newVisits无论怎么变化都不影响预测结果。
7.2.3 分析特征如何影响单个样本的预测结果
在某些场景下,我们可能需要单独分析特征对于单个样本的预测结果的影响,例如特征如何影响某次广告的转化、如何影响单个客户的转化等。本案例来实现对单个样本的特征影响的解释。
本案例的数据延续“7.2.2 分析特征对转化目标的正负向影响”的结果,假设这些数据是不同的广告波次下的效果数据,这里分析单次广告下的特征影响因素。
第六步 分析特征如何影响单个样本的预测结果
print(explainer.expected_value) #①
print([1-clf.predict(x).mean(0),clf.predict(x).mean(0)]) #②
shap.force_plot(explainer.expected_value[1], shap_values[1][0,:], x.iloc[0,:]) #③
shap.force_plot(explainer.expected_value[1], shap_values[1][17,:], x.iloc[17,:]) #④
代码①打印输出shap对象的预测值,结果为[0.813 0.187]。
代码②通过树模型的预测计算来还原shap对象的预测值,通过clf.predict(x).mean(0)来实现对x的预测,得到的值为预测结果的均值,本案例中的预测结果值是0和1组成,因此值的含义为转化占比;通过1-clf.predict(x).mean(0)得到另一半的概率占比(非转化占比),得到与代码①相同的结果[0.813, 0.187]。
代码③和④通过shap的force_plot来显示特征对单个样本记录的影响。其中explainer.expected_value为通过shap对象预测得到的预期值,其中1代表第二个数据对象,表示预测为1的转化占比;shap_values[1]表示预测结果为1对应的shap值,[0,:]表示shap对象中的第1个数据行记录; x.iloc[0,:]为原始训练样本的第1个样本值;同理,代码④表示第18个样本预测值与模型基准的对照结果。得到结果7-4。
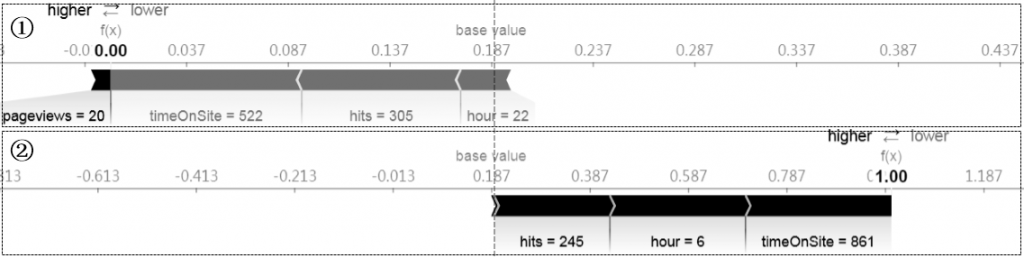
图7-4 特征对单个样本的影响
图7-4中,水平坐标轴是shap值分布。base value是全体样本Shap的平均值,它与树模型预测后的均值相等,输出结果都是0.187,表示所有样本的预测结果(值域为0和1)的平均值。f(x)是当前样本的Shap值,通过与base value的比较可以知道该条结果预测效果相对“标杆”的差距。在f(x)左侧的higer区域,为特征对shap值的正向影响区间,表示左侧的特征能增加预测的效果,①中的其中pageviews=20对于该样本预测起到积极贡献作用,但长度条很小表示贡献非常有限;在f(x)右侧的lower区域,表示特征对shap值的负向影响,①中的timeOnSite=522对shap值的负向影响最大,另外hits=305和hour=22与会显著降低模型预测效果。
图中所有样本的base value一致(全部样本的预测均值0.187);通过对比两个样本的结果,①预测结果f(x)=0,低于总体转化均值;而②预测结果为1,则高于总体转化均值。二者预测结果的差异,主要是各自higer和lower区域的特征导致的;②中的f(x)显著正向贡献特征是hits=245、hour=6 和timeOnSite=861,这些特征显著的拉升了模型效果。
这种针对单个样本的预测解释,主要用在特定渠道、用户等焦点对象的预测结果的解读和分析,用于找到到底是什么因素导致预测结果更准(或不准)、产生转化(或不转化)。
7.2.4 知识拓展:渠道效果影响因素的落地应用
在所有数据挖掘和机器学习算法中,综合业务可理解、可解释性以及算法的简易实施性,树模型(包括Classification and Regression Trees(CART)等单一树以及Gradient Boosting Decision Tree(GBDT)、eXtreme Gradient Boosting(XGB)等集成树)、广义线性回归(包括简单线性回归、逻辑回归等)比较适合应用到影响因素分析场景中,前者可以提供类似于人类思考逻辑的决策树规则,后者可以提供在学校时期已经学过的数学公式。
通过本节以及“4.1 基于Lookalike的投放人群管理”知识,我们可以通过多种模式找到了影响渠道效果的重要特征,以及不同特征对结果的影响规则;在后续业务落地中,主要应用场景包括:
- 投放人群圈选。具体用法参考“4.1 基于Lookalike的投放人群管理”。
- 贡献价值分析。营销转化会涉及到站外广告投放、落地页设计、网站内部功能和体验优化、站内运营活动策划和执行等主要部门,各部门如何“分配”对转化的贡献,可考虑通过本节方法进行评估。
- 效果优化提升。根据本节提供的方法,如果想要优化特定样本或总体预测结果(提高预测准确性或降低误差),则可以基于对预测结果shap值贡献最大的样本及其值的变化规律来优化结果;在营销执行过程中,通过素材和文案设计、渠道组合和投放触点、日期和时间等季节性控制、落地页选择、投放内容管理等方面来思考各个因素对转化的贡献价值。