说明:本文是《Python数据分析与数据化运营》中的“3.12.1 网页数据解析”。 -----------------------------下面是正文内容--------------------------
本节通过一个稍微复杂一点的示例,来演示如何抓取并解析网页数据。之所以说复杂,是因为本节中会出现几个本书中未曾提及的知识和方法,从代码数量来看也会比之前的示例稍微长一点。
本示例中,将使用requests、bs4、re、time库进行网页数据读取、解析和相关处理。
示例的目标是抓取亚马逊中国网站苹果手机和配件的价格,用于做竞争对手的标杆商品价格监控。注意:本示例仅做学习之用。
在抓取和解析网页数据之前,首先要做的是做网页内容分析,包括:
- 要抓取的内容格式:文本、图像还是其他文件。
- 是否存在重定向:重定向往往根据User-Agent来判断,例如手机端、电脑端卡看到的页面信息不同。
- 是否需要验证:很多网页的爬虫都需要用户登录、验证码等。
- 目标数据是否具有统一标签规则:要爬取的数据是否具有统一的HTML标签,便于后期处理。
- URL规则:大多数情况下网页爬取都不是只有一个页面,而是多个页面,因此需要了解不同页面的URL规则,尤其是带有条件查询的,需要了解具体参数。
- 业务常识性分析:根据实际要爬取的数据,分析可能会产生哪些字段,会有哪些冲突和包含关系以及关联性影响等。
点击亚马逊中国网站左侧进入二级导航“手机通讯”中的Apple Phone:Apple - 手机 / 手机通讯 - 电子 -亚马逊
要抓取的内容格式分析
笔者的浏览器是Chrome,在当前页面中点击快捷键F12,打开开发者工具(或者点击右上角扩展按钮 ,在弹出的菜单中选择 更多工具 – 开发者工具),点击
Elements 切换到查看页面元素视图。
,在弹出的菜单中选择 更多工具 – 开发者工具),点击
Elements 切换到查看页面元素视图。
鼠标点击开发者工具栏左侧的,然后点击页面中的商品价格、标题等,多测试几个商品,发现价格是文本格式(不是调用的外部图像)。
同样的方法点击商品描述,分析下商品标题的特点。商品标题用来存储某个价格对应的商品,该标题中的关键字可用于识别出具体商品型号并与企业自身商品做比较。
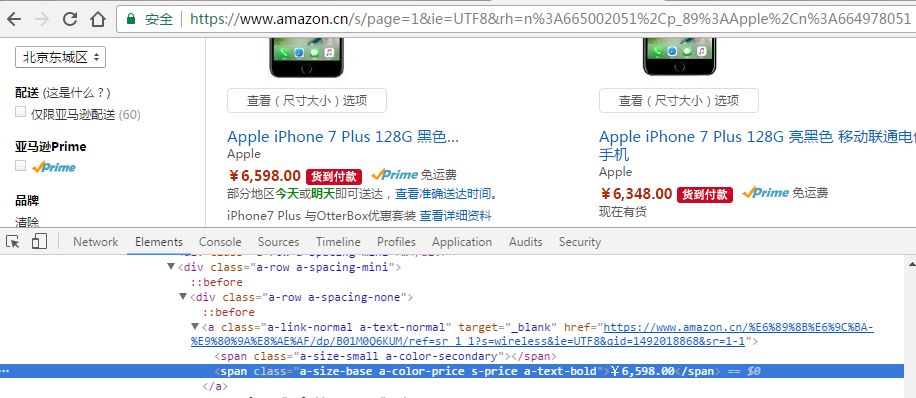 图3-5要抓取的内容格式分析
图3-5要抓取的内容格式分析
是否存在重定向分析
点击开发者工具左侧的第二个图表,通过浏览器模拟当前是一个移动设备环境,然后按F5刷新该页面。原来适配到电脑上的页面现在改为适配移动端,然后按照刚才的方法查看要抓取的数据是否格式仍然相同;除了显示的样式不同可能导致的页面展示和规则不同外,不同平台的商品价格可能存在不同(例如移动端比PC端便宜10元),如果需要区分平台,那么可以分开抓取。本节仅以电脑上的可视网页做示例进行抓取。
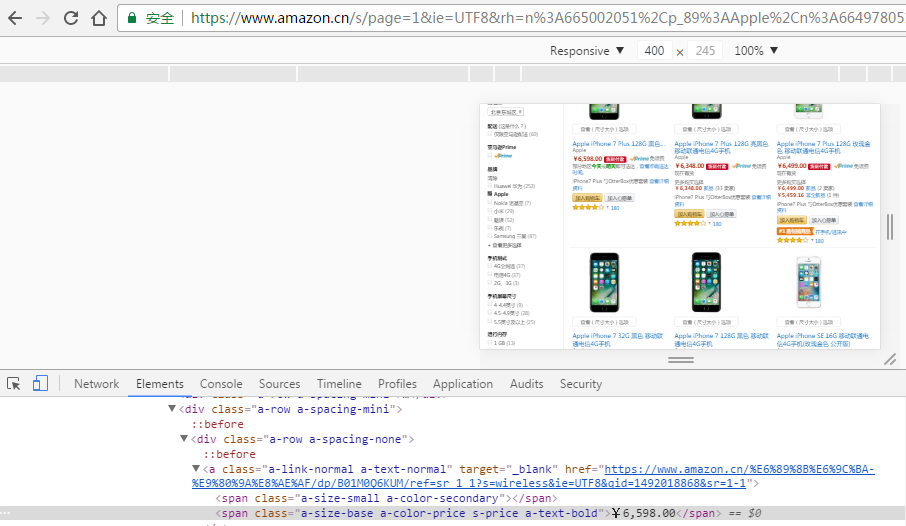 图3-6重定向分析
图3-6重定向分析
是否需要验证分析
由于页面中浏览商品时没有任何需要登录、注册等验证信息,因此无需验证可直接访问。
目标数据是否具有统一标签规则
通过查看源代码发现,不同的商品通过li标签进行列表展示,每个li下对应一个商品。在li子层级的标签中,类为"a-size-base a-color-price s-price a-text-bold"的span标签包含了价格信息,h2标签总则包含了商品标题。因此我们只需要找到这两个特征的标签即可解析出目标数据。
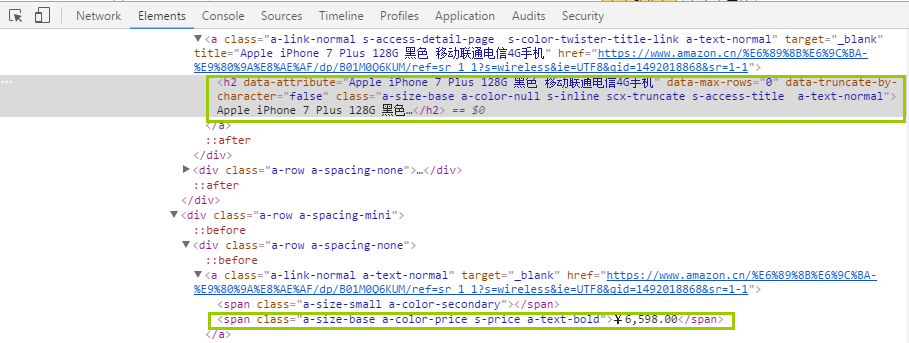 图3-7主要商品信息所在的标签
图3-7主要商品信息所在的标签
相关知识点:HTML标签
超文本标记语言(HTML)的标签是HTML语言的基本单位,也是设计网页的基本元素。我们查看源代码(在任意页面右键,弹出的菜单中点击查看页面源代码,或使用快捷键Ctrl+U),都能发现HTML标签构成了所有代码的“骨架”。不同的HTML标签的作用不同,我们在爬虫网页内容时“看到”(指的是前台展示的信息)的内容通常都是在body标签里面的。上述示例中几个HTML标签的基本含义:
- li:HTML中的列表,用来展示多个并列的项目信息。
- h2:HTML中的二级标题,一般表示强调,一般呈现的是字体加粗增大的效果。
- span:定义一个文字段落。
上面这些不同的标签以及效果(HTML里面被称为样式),可以通过多种方法在多个地方定义和引用,不同的定义之间会有覆盖效果。因此,标签本身的默认效果可能被更高优先级的样式覆盖而无法显示出来。
URL规则分析
在URL规则部分,URL中https://www.amazon.cn/s/page=1&ie=UTF8&rh=n%3A665002051%2Cp_89%3AApple%2Cn%3A664978051 不同的页码变化的是page=,其中是指示不同的页码,因此我们只需要获得总页面数量,然后依次循环读取数据即可。通过观察页面分析,页面中并没有直接显示页面总数量的信息,不过我们可以通过页面左上角的总返回结果数计算得出。
默认我们打开的是第一页,因此有关返回结果的三个数据分布表示第一页商品的起止数以及总商品数,我们用 (总商品数/第一页商品数) +1便可以得出总页面数。例如 (81/24)+1 = 4。关于页面这三个数字可以通过“要抓取的内容格式分析”的方法找到页面数量的信息,位于id值为s-
result-count的h2标签内。 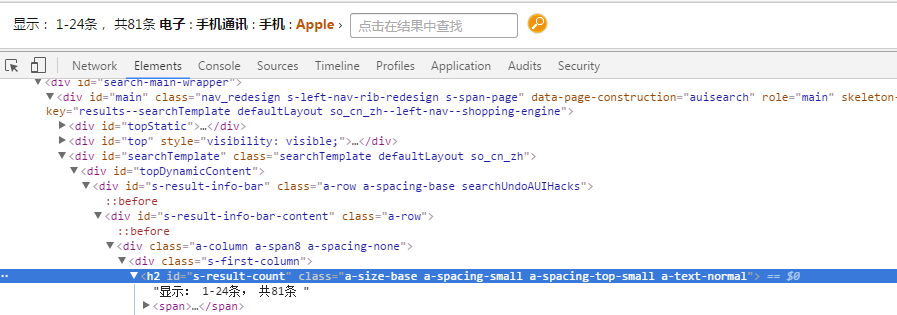 图3-8商品数量标签
图3-8商品数量标签
业务常识性分析
本节示例中的商品没有苹果手机的统一型号编码,只有标题的描述信息可用,因此后期还需要跟实际苹果手机进行匹配,该工作建立一个匹配表,后期定期维护和增量更新即可。
到此为止我们基本确定了抓取思路:先从打开页面计算得到总页面数量,然后循环读出不同的页面信息;接着在每个页面找到每个商品的标题和价格,并把数据保存到本地文件。
清楚了上述基本情况后,我们开始编写代码,完整代码如下:
# 导入库
import requests # 用于请求
from bs4 import BeautifulSoup # 用于HTML格式化处理
import re # 用于HTML配合查找条件
import time # 用于文件名保存
# 获取总页面数量
def get_total_page_number():
user_agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
headers = {'User-Agent': user_agent} # 定义头信息
url = 'https://www.amazon.cn/s/ref=sa_menu_digita_l3_siphone?ie=UTF8&page=1&rh=n%3A665002051%2Cp_89%3AApple%2Cn%3A664978051' # 寻找页码的URL
res = requests.get(url, headers=headers) # 发送请求
html = res.text # 获得请求中的返回文本信息
html_soup = BeautifulSoup(html) # 建立soup对象,用于处理HTML
page_number_span = html_soup.find('h2', id="s-result-count") # 查找id="s-result-count"的h2标签
page_number_code = page_number_span.text # 读出该标签的文本信息
number_list = re.findall(r'(\w*[0-9]+)\w*', page_number_code) # 使用正则表达式解析出文本中的3个数字
total_page_number = (int(number_list[-1]) / int(number_list[-2])) + 1 # 计算得出总页码
return int(total_page_number) # 返回页面数字
# 解析单页面
def parse_single_page(i):
url_part1 = 'https://www.amazon.cn/s/ref=sa_menu_digita_l3_siphone?ie=UTF8&page=%d' % i # 定义URL动态前半部分
url_part2 = '&rh=n%3A665002051%2Cp_89%3AApple%2Cn%3A664978051' # 定义URL静态后半部分
url = url_part1 + url_part2 # 拼接成完整URL
print ('parse url: %s' % url) # 输出URL信息
user_agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'
headers = {'User-Agent': user_agent} # 定义头信息,用于发送请求
res = requests.get(url, headers=headers) # 发送请求
html = res.text # 获得请求中的返回文本信息
html_soup = BeautifulSoup(html) # 建立soup对象,用于处理HTML
tag_list = html_soup.find_all('li', id=re.compile('^result.*')) # 查找id以result开始的li标签,返回列表
for tag_info in tag_list: # 读取列表每个标签(一个标签对应一个商品)
# 解析价格
# print (tag_info)
price_code = tag_info.find('span', class_="a-size-base a-color-price s-price a-text-bold") # 查找价格标签
if price_code != None: # 如果非空则继续
price = price_code.text # 取出价格标签文字
# 解析商品标题
title_code = tag_info.find('h2') # 查找标题标签
title = title_code.text # 取出标题标签文字
write_data(title, price) # 每次解析完成写入文件
# 将数据写入文件
def write_data(title, price):
file_date = time.strftime('%Y-%m-%d', time.localtime(time.time())) # 当前日期,用于文件命名
fn = open('%s.txt' % file_date, 'a+') # 新建文件对象,以追加模式打开
content = title + '\t' + price + '\n' # 写内容,标题和价格以tab分割,末尾增加换行符
fn.write(content) # 写入文件
fn.close() # 关闭文件对象
# 解析多页面并写文件
def main():
total_page_number = get_total_page_number() # 获得总页面数
for i in range(1, int(total_page_number) + 1): # 循环读出每个页面
parse_single_page(i)
main()
上述代码以空行分为6个部分。
- 第一个部分导入库,具体用途在注释中已经注明。
- 第二个部分开始我们每个功能都定义为一个函数模块,用于在不同场景下引用。get_total_page_number模块用来计算页面数量。
- 第三个部分定义了一个用于解析单个URL的函数模块,在定义URL的部分,由于原始URL中有%,这会导致我们新增占位符时做外部数字引用报错,因此将其分开定义再组合。在解析不同的标签(包括后面的模块)时,我们用到了正则表达式模块,可以非常容易的解析出目标字符。
- 第四个部分是将每次解析的标题和价格写入文件。文件以追加模式打开,这样每次的数据都会追加到文件尾,而不会覆盖之前的数据,类似于数据库的追加模式操作。在写文件内容时,末尾需要有换行符,否则所有数据都会合并到一行。
- 第五个部分是通过一个循环来调用执行多个页面进行解析。 第六个部分函数用来执行所有的操作。
上述代码执行后返回结果如下: 调试窗口输出信息:
parse url: https://www.amazon.cn/s/ref=sa_menu_digita_l3_siphone?ie=UTF8&page=1&rh=n%3A665002051%2Cp_89%3AApple%2Cn%3A664978051
parse url: https://www.amazon.cn/s/ref=sa_menu_digita_l3_siphone?ie=UTF8&page=2&rh=n%3A665002051%2Cp_89%3AApple%2Cn%3A664978051
parse url: https://www.amazon.cn/s/ref=sa_menu_digita_l3_siphone?ie=UTF8&page=3&rh=n%3A665002051%2Cp_89%3AApple%2Cn%3A664978051
parse url: https://www.amazon.cn/s/ref=sa_menu_digita_l3_siphone?ie=UTF8&page=4&rh=n%3A665002051%2Cp_89%3AApple%2Cn%3A664978051
程序执行目录下产生一个跟运行时间相同的数据文件,如下是文件部分数据:
 图3-9爬取数据结果 提示
图3-9爬取数据结果 提示
上述的抓取执行过程中,“遭遇”到了亚马逊的反爬虫应对措施。
经过测试,连续执行2次代码,第二次会返回HTML代码,但没有目标数据;连续第3次,HTTP请求直接无法返回数据。
大多数情况下,通过网络爬虫获取数据都是辅助方式,原因是现在基本上所有的网站都有防爬虫的意识和方式,这导致数据爬取会受到外部很多因素的影响而导致数据质量低下。基于爬虫的主要工作内容包括舆情监测、市场口碑、用户情绪、市场营销等方面,属于外部属性较强的“附加”工作。这些工作其实都不是公司的核心运营内容,这就会导致这些工作看似有趣并且有价值,但真正对企业来讲价值很难实际体现。
相关知识点:函数 函数是用来形成一段功能的代码段,函数可以用来给其他应用做调用。使用函数的好处很多:
- 利于维护:代码中有变更的功能时,只需要对特定代码段进行修改,而无需全部修订。
- 复用:当某个功能会被很多应用调用时,通过函数可实现一次撰写多次使用的目的。
- 清晰化功能设计:当设计功能时,不同的函数模块类似于功能主题,同时基于函数又可以派生库、类、包,通常函数是模块划分的基本单位。
- 递归:使用函数可以实现一种特殊的功能叫做“递归”,函数内部的功能调用函数自身,实现“自循环”,这种经常被用到有固定规律的场景下,例如求阶乘。
定义函数使用def
[函数名]即可,函数可用来执行单独的任务,也可以通过return返回执行结果,用来与其他功能做交互使用。同时,不同的函数间可以通过赋值进行参数传递和调度之用。
上述过程中,主要需要考虑的关键点是:如何根据不同网页的实际特点,尤其是对于反爬虫的应对来正确读取到网页源代码,读取后源代码之后的解析往往不是主要问题。
代码实操小结:本小节示例中,主要用了几个知识点:
- 通过requests库发送带有自定义head信息的网络请求
- 通过requests返回对象的text方法获取源代码文本信息
- 使用bs4的BeautifulSoup库配合find方法进行目标标签查找和解析,并通过其text方法获得标签文本信息
- 通过re的正则表达式功能,实现对于特定数字规律的查找
- 通过定义function函数来实现特定功能或返回特定结果
- 通过for循环读取数据列表
- 通过if条件判断实现对符合条件的记录做处理
- 对文本文件的读写操作
- 使用time的localtime、time、strftime方法做日期获取以及格式化操作