说明:本文是《Python数据分析与数据化运营》中的“2.3 内容延展:读取非结构化网页、文本、图像、视频、语音”。 在前面的章节中,我们介绍的内容是企业常见的数据来源和获取方式,本节将拓展数据来源方式和格式的获取,主要集中在非结构化的网页、文本、图像、视频和语音。
2.3.1 从网页中爬取运营数据
要从网页中爬虫数据,可使用Python内置标准库或第三方库,例如urllib、urllib2、httplib、httplib2、requests等。本节使用requests方法获取网页数据。
import requests # 导入库
url = 'http://www.dataivy.cn/blog/dbscan/'
# 定义要抓取的网页地址
res = requests.get(url) # 获得返回请求
html = res.text # 返回文本信息
print (html) # 打印输出网页源代码
在代码中,先导入用到的网络请求处理库requests,然后定义一个用来抓取的url,通过requests的get方法获取url的返回请求,并通过返回请求的text方法获取内容(源代码),最终打印输出,部分结果如下:
<!DOCTYPE html>
<html lang="zh-CN"
class="no-js">
<head>
<meta
charset="UTF-8">
<meta
name="viewport" content="width=device-width">
<link
rel="profile" href="http://gmpg.org/xfn/11">
......
</body>
</html>
从网页中读取的信息其实是网页的源代码,源代码经过浏览器的解析才是我们看到的不同的页面内容和效果。因此,在获取网页中包含了内容的源代码后,下面要做的是针对源代码的解析。有关该内容会在“3.12.1 网页数据解析”中具体说明。
2.3.2 读取非结构化文本数据
非结构化的文本数据指的是文本数据中没有结构化的格式,需要定制化解析才能获取数据,并且每条记录的字段也可能存在差异,这意味着传统的结构化读取方式将很难工作。非结构化的日志就是这其他一个典型示例,服务器的日志可由运维工程师自行定义,因此不同公司的日志格式有所不同;另外在网站日志中还可能包含通过页面“埋码”的方式而采集用户的行为数据,这些都会使日志面临非结构化的解析问题。 在“附件- chapter2”文件夹中有一个名为traffic_log_for_dataivy的日志文件,里面存放了网站一段时间的日志数据,本节示例代码的目的是将日志读取出来。
file = 'traffic_log_for_dataivy'
fn = open(file, 'r') # 打开要读取的日志文件对象
content = fn.readlines() # 以列表形式读取日志数据
print (content[:2])
fn.close() # 关闭文件对象
上述代码中先定义了一个要读取的非结构化文本文件,然后通过Python标准库open方法以只读模式打开文件,然后通过readlines方法将文件内容以行为单位读取为数据列表,打印输出前2条数据,然后关闭文件对象。执行后,返回如下结果:
['120.26.227.125 - - [28/Feb/2017:20:06:51 +0800] "GET /
HTTP/1.1" 200 10902 "-" "curl"\n', '139.129.132.110 -
- [28/Feb/2017:20:06:51 +0800] "GET / HTTP/1.1" 200 10903
"-" "curl"\n']
其实日志文件只是普通文本文件的一种类型而已,其他的非结构化数据文件都可以以类似的方法读取,即使文件没有任何扩展名。
总结:对于非结构化的文本处理,通常更多的侧重于特定场景,通用性较差,原因就在于非结构化的形式本身变化多样。自然语言理解、文本处理和挖掘、用户日志和机器日志解析等都是围绕该领域的主要工作主题。
2.3.3 读取图像数据
Python读取图像通常使用PIL和OpenCV两个库,相对而言,笔者使用后者的情况更多。本节以 “附件-chapter2”文件夹中cat.jpg为例进行说明。
1. 使用PIL读取图像
Python Imaging Library中包含很多库,常用的是其中的Image,通过使用其中的open方法来读取图像,用法如下:
import Image # 导入库
file = 'cat.jpg' # 定义图片地址
img = Image.open(file,
mode="r") # 读取文件内容
img.show() # 展示图像内容
其中关键的方法是open,其中的参数包括两个:
- file:文件对象名称,可以是文件名,也可以是图像文件字符串。
- mode:打开模式,默认只能是r模式,否则会报错;当file是图像字符串时,会调用系统的rb模式读取。
通过open读取之后会返回一个图像文件对象,后续所有的图像处理都基于该对象进行。上述代码执行后,通过img.show()会调用系统默认的图像浏览器查看打开图像进行查看。如图2-27。

图2-27调用img.show()展示图像 该对象包含了很多方法可以用来打印输出文件的属性,例如尺寸、格式、色彩模式等。
print ('img format: ', img.format) # 打印图像格式
print ('img size: ', img.size) # 打印图像尺寸
print ('img mode: ', img.mode) # 打印图像色彩模式
上述代码执行后返回的结果如下:
('img format: ', 'JPEG')
('img size: ', (435, 361))
('img mode: ', 'RGB')
其中:
- 图像的类型是图像本身的格式,例如jpg、gif、png等;
- 图像尺寸是指图像分辨率,示例中的尺寸是435×361(单位是像素);
- 图像的模式指的是颜色模式,示例图像是RGB模式。
相关知识点:图像颜色模式 在不同的领域中,图像的色彩模式有多种标准。比较常见的颜色模式包括:
- RGB:自然界中所有的颜色都几乎可以用红、绿、蓝这三种颜色波长的不同强度组合得到,这种颜色模式在数字显示领域非常流行。
- CMYK:这是一种工业四色印刷的亚兰瑟标准,四个字母分别指代青(Cyan)、洋红(Magenta)、黄(Yellow)、黑(Black)。
- HSB:这种模式使用色泽(Hue)、饱和度(Saturation)和亮度(Brightness)来表达颜色的要素,这种模式更多基于人类心理的认识和感觉。
- 其他模式:其他模式还包括灰度模式、索引模式、位图模式等,也在一定场景下较为常见。
不同的色彩模式下之间可以相互转换,例如从RGB模式转换为灰度模式:
img_gray = img.convert('L') # 转换为灰度模式
img_gray.show() # 展示图像
 图2-28灰度图像模式
图2-28灰度图像模式
除此以外,基于该文件对象也可以进行其他操作,例如图像格式转换、旋转、裁剪、合并、滤波处理、色彩处理、缩略图处理等。限于篇幅,在此不作过多介绍。
2. 使用OpenCV读取图像
OpenCV读取和展示图像主要有两类方法,第一种是使用cv库,第二种是使用cv2库。 第一种:使用cv读取图像
import cv2.cv as cv # 导入库
file = 'cat.jpg' # 定义图片地址
img = cv.LoadImage(file) # 加载图像
cv.NamedWindow('a_window',
cv.CV_WINDOW_AUTOSIZE) # 创建一个自适应窗口用于展示图像
cv.ShowImage('a_window', img) # 展示图像
cv.WaitKey(0) # 与显示参数配合使用
第二种:使用cv2读取图像
import cv2 # 导入库
file = 'cat.jpg' # 定义图片地址
img = cv2.imread(file) # 读取图像
cv2.imshow('image', img) # 展示图像
cv2.waitKey(0) # 与显示参数配合使用
上述两种方法执行后,都会产生如图2-28的显示结果。不同的是,图2-28中通过PIL调用的是系统默认的图像显示工具,而在OpenCV中是通过自身创建的图像功能显示图像。
另外,两种方法中都有一个waitKey()的方法,该方法的作用是键盘绑定函数,其中的参数表示等待毫秒数。
执行该方法后,程序将等待特定的毫秒数,看键盘是否有输入,然后返回值对应的ASCII值。如果其参数为0,则表示无限期的等待直到键盘有输入。
笔者通常使用第二种方法读取图像,因为方法更加简单。其中imread方法细节如下:
语法
cv2.imread(filename[, flags])
描述
读取图像内容,如果图像无法读取则返回空信息,支持图像格式几乎包括了日常所有场景下的格式,具体包括:
- Windows bitmaps文件:.bmp、.dib
- JPEG文件:.jpeg、.jpg、*.jpe
- JPEG 2000文件:*.jp2
- PNG文件:*.png
- WebP文件:*.webp
- 移动图像格式:.pbm、.pgm、.ppm .pxm、*.pnm
- Sun rasters文件:.sr、.ras
- TIFF 文件:.tiff、.tif
- OpenEXR文件:*.exr
- Radiance HDR文件:.hdr、.pic
参数
- filename必填,字符串,图像地址。
- flags可选,int型或对应字符串,颜色的读取模式。如果flag>0或者cv2.IMREAD_COLOR,读取具有R/G/B三通道的彩色图像;如果flag=0或cv2.IMREAD_GRAYSCALE,读取灰度图像;如果flag<0或cv2.IMREAD_UNCHANGED,读取包含Alpha通道的原始图像。
返回 图像内容,如果图像无法读取则返回NULL。
提示 除了使用OpenCV自带的图像展示方法外,OpenCV还经常和matplotlib配合展示图像,这种场景更加常用。组合使用时可借用Matplotlib的强大图像展示能力进行图像的对比和参照以及不同图像模式的输出。
2.3.4 读取视频数据
Python读取视频最常用的库也是Opencv。本节以 “附件-chapter2”文件夹中Megamind.avi的视频为例进行说明,如下是一段读取视频内容的代码示例:
import cv2 # 导入库
cap =cv2.VideoCapture("tree.avi") #
获得视频对象
status = cap.isOpened() # 判断文件知否正确打开
if status: # 如果正确打开,则获得视频的属性信息
frame_width = cap.get(3) # 获得帧宽度
frame_height = cap.get(4) # 获得帧高度
frame_count = cap.get(7) # 获得总帧数
frame_fps = cap.get(5) # 获得帧速率
print ('frame width: ', frame_width) # 打印输出
print ('frame height: ', frame_height) # 打印输出
print ('frame count: ', frame_count) # 打印输出
print ('frame fps: ', frame_fps) # 打印输出
success, frame = cap.read() # 读取视频第一帧
while success: # 如果读取状态为True
cv2.imshow('vidoe frame', frame) # 展示帧图像
success, frame = cap.read() # 获取下一帧
k = cv2.waitKey(1000 / int(frame_fps)) # 每次帧播放延迟一定时间,同时等待输入指令
if k == 27: # 如果等待期间检测到按键ESC
break # 退出循环
cv2.destroyAllWindows() # 关闭所有窗口
cap.release() # 释放视频文件对象
上述代码分为4个部分,以空行分隔。
第一部分为前3行,先导入库,然后读取视频文件并获得视频对象,再获得视频读取状态。其中的关键方法是VideoCapture,用来读取图像。 语法
cv2.VideoCapture(VideoCaptureID|filename|apiPreference)
描述
读取视频设备或文件,并创建一个视频对象实例 参数 必填,VideoCaptureID|filename VideoCapture ID:int型,系统分配的设备对象的ID,默认的设备对象的ID为0。 Filename:
- 视频文件的名称,字符串,例如abc.avi。目前版本下只支持avi格式。
- 序列图像,字符串,例如img_%2d.jpg(图像序列包括img_00.jpg, img_01.jpg, img_02.jpg, ...)
- 视频URL地址,字符串,例如protocol://host:port/script_name?script_params|auth
- apiPreference:int型,后台使用的API
返回
一个视频对象实例
第二部分为if循环体内的9行代码,该代码主要用来在判断文件被正确读取的情况下,输出视频文件的整体信息。除了代码中get方法使用的参数值外,OpenCV还支持更多图像属性,如表2-7。
表2-7 get方法支持的图像属性
| 值 | 属性 | 描述 |
|---|---|---|
| 0 | CV_CAP_PROP_POS_MSEC | 当前位置(单位:ms) |
| 1 | CV_CAP_PROP_POS_FRAMES | 当前位置(单位:帧数,从0开始计) |
| 2 | CV_CAP_PROP_POS_AVI_RATIO | 当前位置(单位:比率, 0表示开始,1表示结尾) |
| 3 | CV_CAP_PROP_FRAME_WIDTH | 帧宽度 |
| 4 | CV_CAP_PROP_FRAME_HEIGHT | 帧高度 |
| 5 | CV_CAP_PROP_FPS | 帧速率 |
| 6 | CV_CAP_PROP_FOURCC | 4-字符表示的视频编码(如:’M‘, ’J‘, ’P‘, ’G‘) |
| 7 | CV_CAP_PROP_FRAME_COUNT | 总帧数 |
| 8 | CV_CAP_PROP_FORMAT | retrieve().调用返回的矩阵格式 |
| 9 | CV_CAP_PROP_MODE | 后端变量指示的当前捕获的模式 |
| 10 | CV_CAP_PROP_BRIGHTNESS | 明亮度(仅用于摄像头) |
| 11 | CV_CAP_PROP_CONTRAST | 对比度(仅用于摄像头) |
| 12 | CV_CAP_PROP_SATURATION | 饱和度(仅用于摄像头) |
| 13 | CV_CAP_PROP_HUE | 色调(仅用于摄像头) |
| 14 | CV_CAP_PROP_GAIN | 增益(仅用于摄像头) |
| 15 | CV_CAP_PROP_EXPOSURE | 曝光度 (仅用于摄像头) |
| 16 | CV_CAP_PROP_CONVERT_RGB | 是否应该将图像转化为RGB图像(布尔值) |
| 17 | CV_CAP_PROP_WHITE_BALANCE | 白平衡(暂不支持 v2.4.3) |
第三部分为具体读取和展示视频的每一帧内容。
首先读取视频的第一帧,如果状态为True,则展示图像并读取下一帧,期间通过cv2.waitKey参数做图像延迟控制,同时延迟期间等待系统输入指定,如果有输入ESC则退出循环读取帧内容。
相关知识点:动态图像如何产生
我们视觉上看到的视频(或动态图)在计算机中其实是不存在的,计算机中存储的是一幅一幅的图像,在视频里面被称为帧,一帧对应的就是一幅图像。当图像连续播放的速度超过一定阀值间时,由于人类的视觉具有视觉暂留(延迟效应),多个暂留的叠加便形成了我们看到的动态图像。一般情况下,如果一秒钟播放超过16帧时,我们会认为这是一幅动态图像。
在视频中有几个关键名词:
- 帧率(FPS):每秒播放的帧数被定义为帧率,帧率越高,在视觉上认为图像越连贯,就越没有卡顿的现象。常见的帧率包括23.967(电影)、25(PAL电视),示例图像大约为15。帧率与图像清晰度无关,它只是决定了视频的连贯性。
- 帧分辨率:帧分辨率基本决定了视频的清晰度(当然除此之外还有视频处理效果、设备播放差异等,这里指的是同等条件下的视频源)。在同样大小的图像中,分辨率越高图像通常就会越清晰。所以形容视频时提到的1080P(19201080)、720P(1280720)其实指的就是分辨率标准。当然,对于同样分辨率下,在不同国家、不同电视规制、不同扫描标注下,也会更加细分。
注意 在OpenCV中的图像读取和处理,其实是不包括语音部分的,但从视频文件的组成来讲通常包括序列帧和与语音两部分。目前的方式通常是对两部分分开处理。
第四部分为当所有操作结束后,删除所有由OpenCv创建的窗体,释放视频文件对象。
有关OpenCV的更多信息,具体查阅[http://opencv.org]
2.3.5 读取语音数据
对于语音文件的读取,可以使用Python的audioop、aifc、wav等库实现。但针对语音处理这一细分领域,当前市场上已经具备非常成熟的解决方案,例如科大讯飞、百度语音等,大多数情况下,我们会通过调用其API实现语音分析处理的功能,或者作为分析处理前的预处理功能。
在具体实现过程中,既可以直接下载SDK做离线应用,也可以使用在线的服务。
如图2-29为科大讯飞的语音服务。
 图2-29科大讯飞语音服务
图2-29科大讯飞语音服务
本节将以百度语音API服务应用为例,说明如何通过请求百度语音的API,将语音数据转换为文字信息。
在正式应用百度语音API之前,请读者先参照“2.2.5从API获取运营数据”中的步骤,建立百度账户以及注册成为百度开发者。基于该条件下,我们继续开通语音识别服务。
具体方法如下:
进入http://yuyin.baidu.com/app,在弹出的界面中点击要针对哪个应用开通语音识别服务。
我们默认使用在之前建立的API_For_Python应用中。因此,点击该应用的“开通服务”,如图2-30。
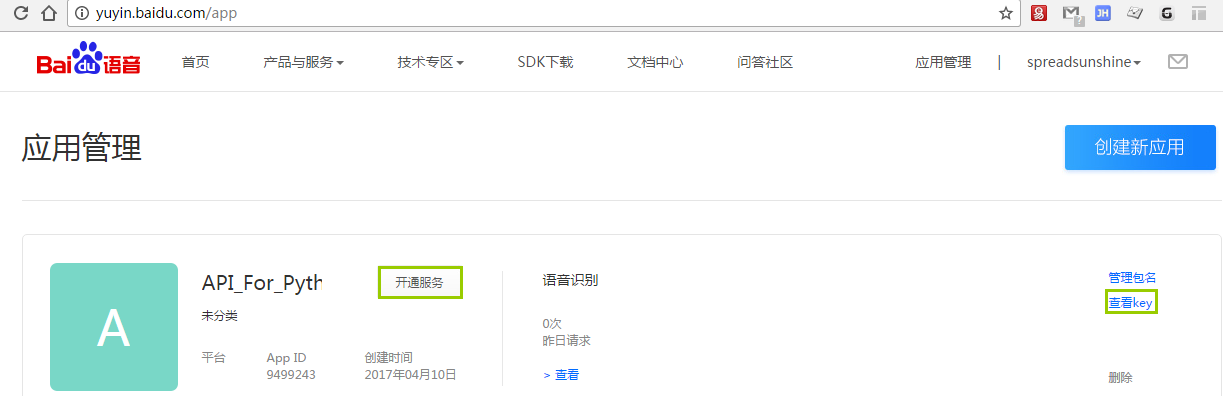 图2-30开通服务 在弹出的窗口中,点击选择“语音识别”并确定,如图2-31。
图2-30开通服务 在弹出的窗口中,点击选择“语音识别”并确定,如图2-31。
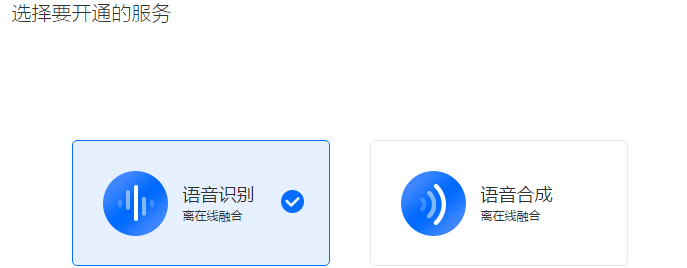 图2-31 选择开通语音识别服务
图2-31 选择开通语音识别服务
开通成功后系统会提示 服务已开通,然后点击图2-34中右侧的 查看key ,会弹出如下信息:
 图2-32 应用key信息
图2-32 应用key信息
上述弹出中的API Key和Secret Key为在后续语音识别中要使用的信息。 以下为完整代码:
# 导入库
import json # 用来转换JSON字符串
import base64 # 用来做语音文件的Base64编码
import requests # 用来发送服务器请求
# 获得token
API_Key = 'DdOyOKo0VZBgdDFQnyhINKYDGkzBkuQr' # 从申请应用的key信息中获得
Secret_Key = 'oiIboc5uLLUmUMPws3m0LUwb00HQidPx' # 从申请应用的key信息中获得
token_url = "https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id=%s&client_secret=%s" # 获得token的地址
res = requests.get(token_url % (API_Key, Secret_Key)) # 发送请求
res_text = res.text # 获得请求中的文字信息
token = json.loads(res_text)['access_token'] # 提取token信息
# 定义要发送的语音
voice_file = 'baidu_voice_test.pcm' # 要识别的语音文件
voice_fn = open(voice_file, 'rb') # 以二进制的方式打开文件
org_voice_data = voice_fn.read() # 读取文件内容
org_voice_len = len(org_voice_data) # 获得文件长度
base64_voice_data = base64.b64encode(org_voice_data) # 将语音内容转换为base64编码格式
# 发送信息
# 定义要发送的数据主体信息
headers = {'content-type': 'application/json'} # 定义header信息
payload = {"format": "pcm", # 以具体要识别的语音扩展名为准
"rate": 8000, # 支持8000或16000两种采样率
"channel": 1, # 固定值,单声道
"token": token, # 上述获取的token
"cuid": "B8-76-3F-41-3E-2B", # 本机的MAC地址或设备唯一识别标志
"len": org_voice_len, # 上述获取的原始文件内容长度
"speech": base64_voice_data # 转码后的语音数据
}
data = json.dumps(payload) # 将数据转换为JSON格式
vop_url = 'http://vop.baidu.com/server_api' # 语音识别的API
voice_res = requests.post(vop_url, data=data, headers=headers) # 发送语音识别请求
api_data = voice_res.text # 获得语音识别文字返回结果
text_data = json.loads(api_data)['result']
print (api_data) # 打印输出整体返回结果
print (text_data) # 打印输出语音识别的文字
代码以空行作为分隔,包括4个部分: 第一部分为导入需要的库信息,具体用途见代码注解。
第二部分为获得要使用百度语音识别API的token信息。
其中的API_Key和Secret_Key从“图2-32应用key信息”获得。token_url通过占位符定义出完整字符串,并在请求时发送具体变量数据,从返回的信息中直接读取token便于下面应用中使用。有关获取token的更多信息,具体查阅http://yuyin.baidu.com/docs/asr/56
提示 在请求获取token时,可使用get或post(推荐使用)两种方法,Token的有效期默认为1个月,如果过期需要重新申请。
第三部分主要用于获取和处理语音文件数据。通过最常见的open方法以二进制的方式读取语音数据,然后从获得的语音数据中获取原始数据长度并将原始数据转换为base64编码格式。
注意 百度语音识别API对于要识别的音频源是有要求的:原始 PCM 的录音参数必须符合 8k/16k 采样率、16bit 位深、单声道,支持的压缩格式有:pcm(不压缩)、wav、opus、amr、x-flac。
第四部分为本节内容的主体,发送请求获取语音识别结果。
- 本段落中先定义了发送头信息;
- 然后定义了一个字典,用于存储要发送的key-value字符串并将其转换为json格式;
- 接着通过post方法以隐示发送的方式进行上传并获得返回结果,最后输出返回结果和其中的语音转文字的信息。
该部分内容的细节比较多,具体参见百度语音API开发说明http://yuyin.baidu.com/docs/asr/57。
关于cuid的获取,由于笔者是在本地电脑上测试的,因此使用的是MAC地址。
- 获取MAC地址的方法是:打开系统终端命令行窗口(Win+R,输入cmd并回车)
- 在命令行中输入命令ipconfig/all,在列出的所有连接中找到其中媒体状态不是“媒体已断开”并且属于当前连接的物理地址信息,如图2-33为笔者电脑MAC信息:
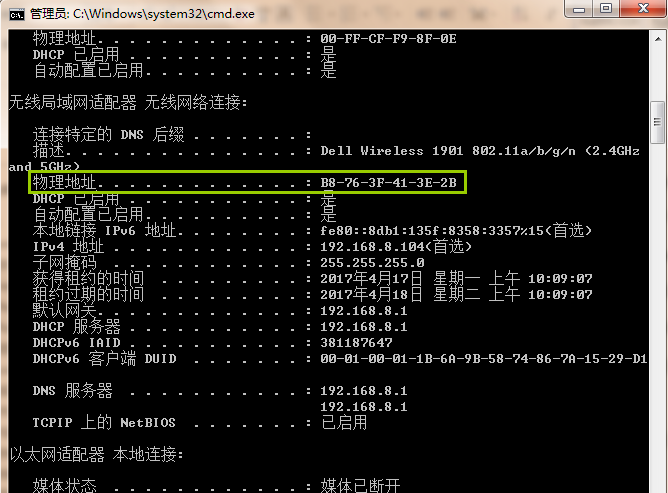 图2-33 获取MAC地址信息
图2-33 获取MAC地址信息
有关语音服务的更多信息,具体查阅http://www.xfyun.cn/。
上述代码执行后返回如下结果:
{"corpus_no":"6409809149574448654","err_msg":"success.","err_no":0,"result":["百度语音提供技术支持,"],"sn":"83327679891492399988"}
[u'\u767e\u5ea6\u8bed\u97f3\u63d0\u4f9b\u6280\u672f\u652f\u6301\uff0c']
系统成功返回是识别结果,录音的内容是“百度语音提供技术支持”,第二端的编码是unicode编码格式的中文。
总结:上述语音识别仅提供了关于语音转文字的方法,其实语音本身包括非常多的信息,除了相对浅层的生理和物理特征,例如语速、音调、音长、音色、音强等外;还包括更深层次的社会属性,这部分内容需要自然语音理解的深层次应用。
目前的语音数据读取后主要应用方向包括:
- 语音转文字。这也是广义上语音识别的一种,直接将语音信息转为文字信息,例如微信中就有这个小功能。
- 语音识别。语音识别指的是对说话者通过选取语音识别单元、提取语音特征参数、模型训练、模型匹配等阶段实现其角色识别和个体识别的过程,例如通过某段语音识别出是哪个人说的话。
- 语音语义理解。在语音识别的基础上,需要对语义特征进行分析,目的是通过计算得到语音对应的潜在知识或意图,然后提供对应的响应内容或方法。语音识别和语音理解的差异之处在于,语音识别重在确定语音表达的字面含义,属于表层意义;而语音理解重在挖掘语音的背后含义,属于深层意义。
- 语音合成。语音合成就是让计算机能够“开口说话”,这是一种拟人的技术方法。语音合成,又称文本转语音(Text to Speech)技术,它通过机械的、电子的方法将文字信息转变为人类可以听得懂的语音。
- 应用集成。经过分析、识别后的信息可以与硬件集成,直接通过语音发送指令。例如通过跟Siri的“沟通”,除了可以进行日常沟通,它还可以告诉你天气情况、帮你设置系统日程、介绍餐厅等。这是智能机器人在模式识别方面的典型应用。
基于上述的复杂应用场景,通常语音后续分析、处理和建模等过程都无法由数据工程师单独完成,还需要大量的语料库素材、社会学、信号工程、语言语法、语音学、自然语音处理、机器学习、知识搜索、知识处理等交叉学科和相关领域才有可能解开其中的密码。