说明:本文是《Python数据分析与数据化运营》中的“2.2 使用Python获取运营数据”中的第一部分,由于本节内容较多,这里分几个文章。
2.2.1 从文本文件读取运营数据
1. 使用read、readline、readlines读取数据
Python可以读取任何格式的文本数据,使用Python读取文本数据的基本步骤是:
- 定义数据文件
- 获取文件对象
- 读取文件内容
- 关闭文件对象
定义数据文件 定义数据文件即定义要读取的文件,该步骤不是必须的,可以跟“获取文件对象”整合。但为了后续操作的便捷性、全局数据对象的可维护性以及减少代码冗余,建议读者养成习惯,将数据文件预先赋值给一个对象。
定义文本数据文件的方法是:file_name = [文件名称]。示例:file_name = 'd:/python_data/data/text.txt'
文件名称中可以只写文件名,此时默认Python读取当前工作目录下的文件;也可以加入路径,默认使用斜杠,尤其是Windows下要注意用法。
获取文件对象
获取文件对象的意义是基于数据文件产生对象,后续所有关于该数据文件的操作都基于该对象产生。 语法
file object = open(name [, mode][, buffering])
参数
- name:要读取的文件名称,即上一个环节定义的file_name,必填。
- mode:打开文件的模式,选填,在实际应用中,r、r+、w、w+、a、a+是使用最多的模式;完整mode模式如表2-1:
表2-1 Python文件打开模式(mode)
| 模式(mode) | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。默认打开模式。 |
| rb | 以二进制格式打开一个文件用于只读。 |
| r+ | 打开一个文件用于读写。 |
| rb+ | 以二进制格式打开一个文件用于读写。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| a | |
| 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 | |
| ab | |
| 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 | |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
| buffering:文件所需的缓冲区大小,选填;0表示无缓冲,1表示线路缓冲。 返回 通过open函数会创建一个文件对象(file object)。 示例 |
file_name = 'text.txt'
file_object = open(file_name)
在“定义数据文件”部分提到可以将前两个环节结合起来,定义的语法是:
file_object = open('text.txt')
读取文件内容
Python基于文件对象的读取分为三种方法,如表2-2:
表2-2 Python读取文件内容的3中方法
| 方法 | 描述 | 返回数据 |
|---|---|---|
| read | 读取文件中的全部数据,直到到达定义的size字节数上限。 | 内容字符串,所有行合并为一个字符串 |
| readline | 读取文件中的一行数据,直到到达定义的size字节数上限。 | 内容字符串 |
| readlines | 读取文件中的全部数据,直到到达定义的size字节数上限。 | 内容列表,每行数据作为列表中的一个对象 |
示例,在“附件-chapter2”文件夹中有一个名为“text.txt”的数据文件,其中包含2个文本行,数据内容如下图2-2:
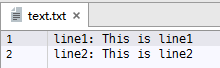 图2-2 示例数据源文件内容
图2-2 示例数据源文件内容
- 通过read方法读取该数据文件得到的数据结果:'line1: This is line1\nline2: This is line2'
- 通过readline方法读取该数据文件得到的数据结果:'line1: This is line1\n'
- 通过readlines方法读取该数据文件得到的数据结果:['line1: This is line1\n', 'line2: This is line2
总结:在实际应用中,read方法和readlines方法比较常用,而且二者都能读取全部文件中的数据。 二者的区别只是返回的数据类型不同,前者返回字符串,适用于所有行都是完整句子的文本文件,例如大段文字信息; 后者返回列表,适用于每行是一个单独的数据记录,例如日志信息。不同的读取方法会直接影响后续基于内容的处理应用; readline由于每次只读取一行数据,因此通常需要配合seek、next等指针操作才能完整遍历读取所有数据记录。
相关知识点:指针
Python文件操作中的指针类似于Word操作中的“光标”,指针所处的位置就是“光标”的位置,它决定了Python的读写从哪里开始。
默认情况下,当通过open函数打开文件时,文件的指针处于第一个对象的位置。
因此,在上述通过readline读取文件内容时,获取的是第一行的数据。仍然是上面示例中的数据文件,我们通过如下代码演示基于不同指针位置读取的内容:
fn = open('text.txt')# 获得文件对象
print (fn.tell())# 输出指针位置
line1 = fn.readline()# 获得文件第一行数据
print (line1) # 输出第一行数据
print (fn.tell())# 输出指针位置
line2 = fn.readline()# 获得文件第二行数据
print (line2)# 输出第二行数据
print (fn.tell())# 输出指针位置
fn.close() # 关闭文件对象
执行上述代码后,返回如下信息:
0
line1: This is line1
22
line2: This is line2
42
从返回结果看:
- 当打开文件时,文件指针的位置处于文件开头,输出为0;
- 当读取完第一行之后,文件指针位置处于第一行行末,位置是第22个字符后面(也就是'\n'后面,'\n'是换行符);
- 当读取完第二行(最后一行)之后,文件指针位置处于第二行行末,位置是第42个字符后面(注意:由于是最后一行,没有换行符'\n')。
关闭文件对象
每次使用完数据对象之后,需要关闭数据对象。方法是file_object.close()
提示 理论上,Python可以读取任意格式的文件,但在这里通常以读取格式化的文本数据文件为主,其中包括有扩展名的txt、csv、tsv等格式的文件,以及有固定分隔符分隔并以通用数据编码和字符集编码(例如utf8、ASCII、GB2312等)存放的无扩展名格式的数据文件。在2.3中我们会介绍使用Python读取非结构化的数据的方法。
2. 使用Numpy的loadtxt、load、fromfile读取数据
Numpy读取数据的方法包括loadtxt、load和fromfile三种方法,概要描述如表2-3:
表2-3 Numpy读取文件的三种方法
| 方法 | 描述 | 返回数据 |
|---|---|---|
| loadtxt | 从txt文本中读取数据 | 从文件中读取的数组 |
| load | 使用Numpy的 load方法可以读取Numpy专用的二进制数据文件,从npy、npz或pickled文件加载数组或pickled对象 | |
| 从数据文件中读取的数组、元组、字典等 | ||
| fromfile | 使用Numpy的fromfile方法可以读取简单的文本文件数据以及二进制数据 | 从文件中读取的数据 |
使用loadtxt方法读取数据文件
Numpy可以读取txt格式的数据文件,数据通常都是1维或2维。 语法
loadtxt(fname, dtype=<type 'float'>, comments='#',
delimiter=None, converters=None, skiprows=0, usecols=None, unpack=False,
ndmin=0)
参数
- fname:文件或字符串,必填,这里指定要读取的文件名称或字符串,支持压缩的数据文件,包括gz和bz格式。
- dtype:数据类型,选填,默认为float(64位双精度浮点数)。Numpy常用类型如表2-4:
| 表2-4 Numpy数据类型 类型 | 描述 |
|---|---|
| bool | 用一位存储的布尔类型(值为TRUE或FALSE) |
| inti | 由所在平台决定其精度的整数 |
| int8 | 整数,大小为一个字节,范围:-128 ~ 127 |
| int16 | 整数,范围:-32768 ~ 32767 |
| int32 | 整数,范围:-2*31 ~ 231-1 |
| int64 | 整数,范围:-2*31 ~ 231-1 |
| uint8 | 无符号整数,0 ~ 255 |
| uint16 | 无符号整数:0 ~ 65535 |
| uint32 | 无符号整数: 0 ~ 2**32-1 |
| uint64 | 无符号整数: 0 ~ 2**64-1 |
| float16 | 半精度浮点数: 16位 ,正负号1位,指数5位,精度10位 |
| float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 |
| float64 / float | 双精度浮点数: 64位,正负号1位,指数11位,精度52位 |
| complex64 | 复数,分别用于两个32位浮点数表示实部和虚部 |
| complex128 / complex | 复数,分别用两个64位浮点数表示实部和虚部 |
备注:其中2**32代表2的32次方,其他表示方法类似。
- comments:字符串或字符串组成的列表,用来表示注释字符集开始的标志,选填,默认为#。
- delimiter:字符串,选填,用来分割多个列的分隔符,例如逗号、TAB符,默认值为空格。
- converters:字典,选填,用来将特定列的数据转换为字典中对应的函数的浮点型数据,例如通过将空值转换为0,默认为空。
- skiprows:跳过特定行数据,选填,用来跳过特定前N条记录,例如跳过前1行(可能是标题或注释),默认为0。
- usecols:元组,选填,用来指定要读取数据的列,第一列为0,以此类推,例如(1,3,5),默认为空。
- unpack:布尔型,选填,用来指定是否转置数组,如果为真则转置,默认为False。
- ndmin:整数型,选填,用来指定返回的数组至少包含特定维度的数组,值域为0/1/2,默认为0。
返回
从文件中读取的数组 示例 在“附件-chapter2”文件夹中有一个名为numpy_data.txt的数据文件,数据为3行5列的矩阵,数据内容如下图2-3,该示例通过loadtxt方法读取其中的数据:
 图2-3 示例numpy数据源文件内容
图2-3 示例numpy数据源文件内容
import numpy as np # 导入numpy库
file_name = 'numpy_data.txt' # 定义数据文件
data = np.loadtxt(file_name, dtype='float32', delimiter=' ') # 获取数据
print (data) # 打印数据
上述代码输出的结果如下:
[[ 0. 1. 2. 3. 4.]
[ 5. 6. 7. 8. 9.]
[ 10. 11. 12. 13. 14.]]
使用load方法读取数据文件
使用Numpy的load方法可以读取Numpy专用的二进制数据文件,从npy、npz或pickled文件加载数组或pickled对象,该文件通常基于Numpy的save或savez等方法产生。
语法
load(file, mmap_mode=None, allow_pickle=True, fix_imports=True,
encoding='ASCII')
参数
- file:类文件对象或字符串格式,要读取的文件或字符串,必填,类文件对象需要支持seek()和read()方法。
- mmap_mode:内存映射模式,值域为:None、'r+'、'r'、'w+'、'c',选填。
- allow_pickle:布尔型,选填,是否允许加载存储在npy文件中的pickled对象数组,默认值为True。
- fix_imports:布尔型,选填,如果为True,pickle将尝试将旧的Python 2名称映射到Python 3中使用的新名称,仅在Python 2生成的pickled文件加载Python 3时才有用,默认值为True。
- encoding:字符串,读取Python 2字符串时使用何种编码,选填。
返回
从数据文件中读取的数组、元组、字典等。 示例 我们将在这个示例中,先定义一份数据,然后保存为.npy格式的数据文件(该文件也在“附件-chapter2”中,名为load_data.npy),接着使用Numpy的load方法读取并打印输出。代码如下:
import numpy as np # 导入nump库
write_data = np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])# 定义要存储的数据
np.save('load_data', write_data) # 保存为npy数据文件
read_data = np.load('load_data.npy') #读取npy文件
print (read_data)# 输出读取的数据
上述代码输出的结果如下:
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
使用fromfile方法
使用Numpy的fromfile方法可以读取简单的文本文件数据以及二进制数据。
通常情况下,该方法读取的数据来源于Numpy的tofile方法,即通过Numpy的tofile方法将特定数据保存为文件(默认为二进制数据文件,无论文件扩展名如何定义),然后通过fromfile方法读取该二进制文件。
语法
fromfile(file, dtype=float, count=-1, sep='')
参数
- file:文件或字符串。
- dtype:数据类型,具体参照“表2-3 Numpy数据类型”。注意数据类型要与文件存储的类型一致。
- count:整数型,读取数据的数量,-1意味着读取所有数据。
- sep:字符串,如果file是一个文本文件,那么该值就是数据间的分隔符。如果为空("")则意味着file是一个二进制文件,多个空格将按照一个空格处理。
返回
从文件中读取的数据。 示例 我们仍然以“附件-chapter2”文件夹numpy_data.txt数据文件为例,首先通过tofile方法创建1个二进制文件,然后再对该文件进行读取。
import numpy as np # 导入numpy库
file_name = 'numpy_data.txt' # 定义数据文件
data = np.loadtxt(file_name, dtype='float32', delimiter=' ') #获取数据
tofile_name = 'binary' # 定义导出二进制文件名
data.tofile(tofile_name) # 导出二进制文件
fromfile_data = np.fromfile(tofile_name, dtype='float32') # 读取二进制文件
print (fromfile_data) # 打印数据
上述代码输出的结果如下:
[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14.]
注意 请务必确保读入文件跟存储文件时的数据类型保持一致,否则将导致数据的错误。有兴趣的读者在使用fromfile导入数据时,不指定float32格式,看下输出结果。另外,由于使用tofile方法保存的数据会丢失数据形状信息,因此导入时无法重现原始数据矩阵。
3. 使用Pandas的read_csv、read_fwf、read_table读取数据
相对于Python默认函数以及Numpy读取文件的方法,Pandas读取数据的方法更加丰富。Pandas读取文本文件数据的常用方法如表2-5:
表2-5 Pandas读取数据的常用方法
| 方法 | 描述 | 返回数据 |
|---|---|---|
| read_csv | 读取csv文件 | DataFrame 或TextParser |
| read_fwf | 读取表格或固定宽度格式的文本行到数据框 | DataFrame 或TextParser |
| read_table | 读取通用分隔符分隔的数据文件到数据框 | DataFrame 或TextParser |
使用read_cvs方法读取数据
通过read_csv方法可以读取csv格式的数据文件。
语法
read_csv(filepath_or_buffer, sep=',', delimiter=None,
header='infer', names=None, index_col=None, usecols=None, **kwds)
参数
(read_csv的参数众多,以下介绍最常用的几个参数)
- filepath_or_buffer:字符串,要读取的文件对象,必填。
- sep:字符串,分隔符号,选填,默认值为英文逗号','。
- names:类数组,列名,选填,默认值为空。
- skiprows:类字典或整数型,要跳过的行或行数,选填,默认为空。
- nrows:整数型,要读取的前记录总数,选填,默认为空,常用来在大型数据集下做初步探索之用。
- thousands:字符串,千位符符号,选填,默认为空。
- decimal:字符串,小数点符号,选填,默认为点(.),在特定情况下应用,例如欧洲的千位符和小数点跟中国地区相反,欧洲的4.321,1对应中国的4,321.1。
返回
DataFrame 或TextParser 示例 我们以“附件-chapter2”文件夹csv_data.csv数据文件为例,直接读取文件并打印输出。
数据内容如下图2-4:
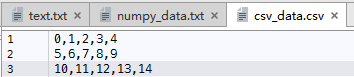 图2-4 数据文件内容
图2-4 数据文件内容
import pandas as pd # 导入Pandas库
csv_data = pd.read_csv('csv_data.csv', names=['col1', 'col2',
'col3', 'col4', 'col5']) # 读取csv数据
print (csv_data) # 打印输出数据
上述代码输出的结果如下:
col1 col2 col3 col4 col5
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
使用read_fwf方法读取数据
通过read_fwf方法可以读取表格或固定宽度格式的文本行到数据框。 语法
read_fwf(filepath_or_buffer, colspecs='infer', widths=None, **kwds)
参数
read_fwf跟read_csv一样都具有非常多的参数(只是在语法中前者通过kwds省略了,查询完整语法请使用help(pd.read_fwf)),并且大多数参数的用法相同。
除了read_csv中的常用参数外,以下介绍几个read_fwf特有且常用的参数。
- widths:由整数组成的列表,选填,如果间隔是连续的,可以使用的字段宽度列表而不是“colspecs”。
返回
DataFrame 或TextParser 示例 我们以“附件-chapter2”文件夹fwf_data数据文件为例,直接读取文件并打印输出。
数据内容如图2-5:
 图2-5 数据文件内容
图2-5 数据文件内容
import pandas as pd # 导入Pandas库
fwf_data = pd.read_fwf('fwf_data', widths=[5, 5, 5, 5],
names=['col1', 'col2', 'col3', 'col4']) # 读取csv数据
print (fwf_data) # 打印输出数据
上述代码输出的结果如下:
col1 col2 col3 col4
0 a2331 a9013 a3211 a9981
1 b4432 b3199 b9766 b2212
2 c3294 c1099 c7631 c4302
使用read_table方法读取数据
通过read_table方法可以读取通用分隔符分隔的数据文件到数据框。 语法
read_table(filepath_or_buffer, sep='\t', delimiter=None,
header='infer', names=None, index_col=None, usecols=None, **kwds)
参数
对于read_table而言,参数与read_csv完全相同。其实read_csv本来就是read_table中分隔符是逗号的一个特例,表现在语法中是read_csv的sep=','(默认)。因此,具体参数请查阅read_csv的参数部分。
返回
DataFrame 或TextParser 我们以“附件-chapter2”文件夹table_data.txt数据文件为例,直接读取文件并打印输出。数据内容如下图2-6:
 图2-6 数据文件内容
图2-6 数据文件内容
{kind=link}
import pandas as pd # 导入Pandas库
table_data = pd.read_table('table_data.txt', sep=';', names=['col1',
'col2', 'col3', 'col4', 'col5']) # 读取csv数据
print (table_data) # 打印输出数据
上述代码输出的结果如下:
col1 col2 col3 col4 col5
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
总结:作为数据分割(或分列)的常用思路分为两种,一种是基于固定宽度,一种是基于分割符号。上述三种方法中,常用的方法是第二和第三种,即read_fwf和read_table方法。
除了上述用于读取文本文件的方法外,Pandas还提供了非常丰富的用于其他场景的数据读取方法,限于篇幅,在此不做更多介绍,仅提供读取列表供有兴趣的读者参考以及做知识延伸。具体如表2-6:
表2-6 Pandas其他数据读取方法
| 方法 | 描述 | 返回数据 |
|---|---|---|
| read_clipboard | 读取剪贴板数据,然后将对象传递给read_table方法 | DataFrame 或TextParser |
| read_excel | 从excel中读取数据 | DataFrame或DataFrame构成的字典 |
| read_gbq | 从Google Bigquery中读取数据 | DataFrame |
| read_hdf | 读取文件中的Pandas对象 | 所选择的数据对象 |
| read_html | 读取HTML中的表格 | 由DataFrame构成的字典 |
| read_json | 将JSON对象转换为Pandas对象 | Series或 DataFrame,具体取决于参数typ设置 |
| read_msgpack | 从指定文件中加载msgpack Pandas对象 | 文件中的对象类型 |
| read_pickle | 从指定文件中加载pickled Pandas或其他pickled对象 | 文件中的对象类型 |
| read_sas | 读取XPORT或SAS7BDAT格式的SAS(统计分析软件)文件 | DataFrame或SAS7BDATReader或XportReader,具体取决于设置 |
| read_sql | 读取SQL请求或数据库中的表 | DataFrame |
| read_sql_query | 从SQL请求读取数据 | DataFrame |
| read_sql_table | 读取SQL数据库中的表 | DataFrame |
| read_stata | 读取Stata(统计分析软件)文件 | DataFrame或StataReader |
4. 如何选择最佳读取数据的方法
关于“最佳”方法其实没有固定定义,因此所谓的最佳方法往往跟以下具体因素有关:
- 数据源情况:数据源中不同的字段类型首先会制约读取方法的选择,文本、数值、二进制数据都有各自的适应方法约束。
- 数据处理目标:读取数据往往是第一步,后续会涉及到数据探索、预处理、统计分析等复杂过程,这些复杂过程需要用到哪些方法都会一定程度上受数据源的读取影响,影响最多的点包括格式转换、类型转换、异常值处理、分类汇总等。
- 模型数据要求:不同的模型对于数据格式的要求是不同的,应用到实际中不同的工具对于数据的表示方法也有所差异。
- “手感”最好的方法:很多时候,最佳方法往往是对哪个或哪些方法最熟悉,这些所谓的“手感”最好的方法便是最佳方法。
当然,即使使用了不是“最佳”的数据读取方法也不必过于担心,因为Python强大的功能提供了众多可以相互进行转换的方法,从Python存储数据的基本对象类型来看,无非是字符串、列表、字典、元组、数组、矩阵等(当然不同的库对于这些对象的定义名称可能有所不同,但基本含义相同),不同对象的类型转换都非常容易。但本着少走弯路的原则,在这里笔者还是针对不同的场景提供了较为适合的数据读取方法:
- 对于纯文本格式或非格式化、非结构化的数据,通常用于自然语言处理、非结构化文本解析、应用正则表达式等后续应用场景下,Python默认的三种方法更为适合。
- 对于结构化的、纯数值型的数据,并且主要用于矩阵计算、数据建模的,使用Numpy的loadtxt更为方便,例如本书中使用的sklearn本身就依赖于Numpy。
- 对于二进制的数据处理,使用Numpy的load和fromfile更为合适。
- 对于结构化的、探索性的数据统计和分析的场景,使用Pandas进行读取效果更佳,因为其提供了类似于R的数据框,可以实现“仿SQL”式的操作方式,对数据进行任意的翻转、切片(块等)、关联等都非常方便。
- 对于结构化的、数值型和文本型组合的数据统计分析场景,使用Pandas更为合适,因为每个数据框中几乎可以装载并处理任意格式的数据。