说明:本文是《Python数据分析与数据化运营》中的“3.2 将分类数据和顺序数据转换为标志变量”。 -----------------------------下面是正文内容-------------------------- 分类数据和顺序数据是常见的数据类型,这些值主要集中在围绕数据实体的属性和描述的相关字段和变量中。
3.2.1 分类数据和顺序数据是什么
在数据建模过程中,很多算法无法直接处理非数值型的变量。例如KMeans算法是基于距离的相似度计算,而字符串则无法直接计算距离。另外,即使算法本身支持,很多算法实现包也无法直接基于字符串做矩阵运算,例如Numpy以及基于Numpy的sklearn,虽然这些库允许直接使用和存储字符串型变量,但却无法发挥矩阵计算的优势。这些类型的数据变量可以分为两类:
分类数据
分类数据指某些数据属性只能归于某一类别的非数值型数据,例如性别中的男、女就是分类数据。分类数据中的值没有明显的高、低、大、小等包含等级、顺序、排序、好坏等逻辑的划分,只是用来区分两个或多个具有相同或相当价值的属性。例如:性别中的男和女,颜色中的红、黄和蓝,他们都是相同衡量维度上不同的属性分类而已。
顺序数据
顺序数据是只能归于某一有序类别的非数值型数据,例如用户的价值度分为高、中、低,学历分为博士、研究生、学士,这些都属于顺序数据。在顺序数据中,有明显的排序规律和逻辑层次的划分。例如:高价值的用户就是比低价值的用户价值高(业务定义该分类时的已经赋予了这样的价值含义)。
3.2.2 运用标志方法处理分类和顺序变量
分类数据和顺序数据要参与模型计算,通常都会转化为数值型数据。当然,某些算法是允许这些数据直接参与计算的,例如分类算法中的决策树、关联规则等。要将非数值型数据转换为数值型数据的最佳方法是:将所有分类或顺序变量的值域从一列多值的形态转换为多列只包含真值的形态,其中的真值可通过True、False或0、1的方式来表示。这种标志转换的方法有时候也称为真值转换。以用户性别变量举例,原有的用户数据如表3-2:
表3-2 原有用户数据
用户ID| 用户性别
---|---
3566841 | 男
6541227 | 女
3512441 | 女
经过转换后的数据如表3-3:
表3-3 标志转换后的用户数据
| 用户ID | 用户性别-男 | 用户性别-女 |
|---|---|---|
| 3566841 | 1 | 0 |
| 6541227 | 0 | 1 |
| 3512441 | 0 | 1 |
为什么不能直接用数字来表示不同的分类和顺序数据,而一定要做标志转换?这是因为在用数字直接表示分类和顺序变量的过程中,无法准确还原不同类别信息之间的信息差异和相互关联性性。例如:
- 针对分类数据:性别变量的属性值是男和女,无论用什么值来表示都无法表达出两个值的价值相等且带有区分的含义。如果用1-2区分,那么1和2本身已经带有距离为1的差异,但实际上二者是不具有这种差异性的,其他任意数字都是如此;如果用相同的数字来表示,则无法达到区分的目的。
- 针对顺序数据:学历变量的属性值是博士、研究生和学士,可以用3-2-1来表示顺序和排列关系,那么如何三个值之间的差异是3-2-1而不是30-20-10或者1000-100-2呢?因此,任何一个有序数字的排序也都无法准确表达出顺序数据的差异性。
3.2.3 代码实操:Python标志转换
在本示例中,将模拟有两列数据分别出现分类数据和顺序数据,通过自定义代码以及sklearn代码分别进行标志转换。
# 3.2 将分类数据和顺序数据转换为标志变量
import pandas as pd # 导入pandas库
from sklearn.preprocessing importOneHotEncoder # 导入OneHotEncoder库
# 生成数据
df = pd.DataFrame({'id': [3566841, 6541227,3512441],'sex': ['male', 'Female','Female'], 'level': ['high', 'low','middle']})
print (df) # 打印输出原始数据框
# 自定义转换主过程
df_new = df.copy() # 复制一份新的数据框用来存储转换结果
for col_num, col_name in enumerate(df): # 循环读出每个列的索引值和列名
col_data = df[col_name] # 获得每列数据
col_dtype = col_data.dtype # 获得每列dtype类型
if col_dtype == 'object': # 如果dtype类型是object(非数值型),执行条件
df_new = df_new.drop(col_name, 1) # 删除df数据框中要进行标志转换的列
value_sets = col_data.unique() # 获取分类和顺序变量的唯一值域
for value_unique in value_sets: # 读取分类和顺序变量中的每个值
col_name_new = col_name + '_' + value_unique # 创建新的列名,使用原标题+值的方式命名
col_tmp = df.iloc[:, col_num] # 获取原始数据列
new_col = (col_tmp == value_unique) # 将原始数据列与每个值进行比较,相同为True,否则为False
df_new[col_name_new] = new_col # 为最终结果集增加新列值
print (df_new) # 打印输出转换后的数据框
# 使用sklearn进行标志转换
df2 = pd.DataFrame({'id': [3566841,6541227, 3512441],'sex': [1, 2, 2],'level': [3, 1, 2]})id_data = df2.values[:, :1] # 获得ID列
transform_data = df2.values[:, 1:] # 指定要转换的列
enc = OneHotEncoder() # 建立模型对象
df2_new = enc.fit_transform(transform_data).toarray() # 标志转换
df2_all = pd.concat((pd.DataFrame(id_data),pd.DataFrame(df2_new)), axis=1) # 组合为数据框
print (df2_all) # 打印输出转换后的数据框
该代码段按空行分为4个部分:
第一部分导入库,本示例使用Pandas库和sklearn。
第二部分生成原始数据,数据为3行3列的数据框,分别包含id、sex和level列,其中的id为模拟的用户ID,sex为用户性别(英文),level为用户等级(分别用high、middle和low代表三个等级)。该段代码输出原始数据框如下:
id level sex
0 3566841 high male
1 6541227 low Female
2 3512441 middle Female
注意 虽然在Python中可以通过一定的方法来处理中文,但鉴于我们用到的库基本都是外国人开发,对中文的支持不太好,所以不建议在程序中直接使用中文进行计算和建模,除非是基于文本的自然语言和文本挖掘等直接面向中文的主题建模。
第三部分为自定义转换主过程。
步骤1
创建数据框副本。通过copy()方法创建一个原始数据库的副本,用来存储转换后的数据。该步骤不能省略,原因是新的副本数据框和原始数据框在下面的步骤都要用到。
步骤2
通过循环获得原始数据框的列索引和列名。
在for循环中使用enumerate()方法,返回可供迭代的列索引和列名。
然后获得每列数据和对应的dtype数据类型,用来做是否进行标志转换的条件判断。
在if表达式中,当数据类型为object时进行转换,转换的核心思路:
- 通过drop()方法删除复制得到的数据框中要进行转换的列,并将结果赋值给df_new,这样每次df_new中就会通过循环不断删除要转换的列,避免数据重复。drop方法的第一个参数是要删除的列名,第二个参数是指定要删除的轴,1表示按列删除。
- 通过unique()方法获取分类和顺序变量的唯一值域,后续的判断主要针对值域列表进行。
- 通过for循环遍历得到值域中的每个值。通过原始列名称+值的形式新建一个列名,这样得到的新列名能保留原始列的含义;由于df_new通过不断循环其本身的索引已经改变,因此需要使用iloc()方法获得原始数据框的列;通过将原始数据列与值域列表中的每个值进行比较,相同为True,否则为False,并将值赋值到df_new结果数据框中。
- 最后打印输出结果数据框。
上述代码执行后得到的结果如下:
id level_high level_low level_middle sex_male sex_Female
0 3566841 True False False True False
1 6541227 False True False False True
2 3512441 False False True False True
结果数据框中的True和False可以参与后续数据建模和距离计算中,True的值是1而False的值为0。
第四部分为使用sklearn.preprocessing中的OneHotEncoder方法进行标志转换。
步骤1
创建模拟数据。数据为3行3列的数据框。
提示 很多情况下,原始数据都不会以字符串(第一种方法中的示例)的形式存储,而是先将数据存储为数字进行存储,这些数字可通过维度表匹配出对应的字符串。当然,如果是这种数据存储方法,第一种自定义转换过程也可以实现,但需要改变对于分类或顺序数据的识别规则,此时的数据类型就不是object,需要根据实际情况通过指定列名等方法转换。
步骤2
获得ID列并指定要转换的列。获得ID列的目的是用于后续将ID列和转换后的列做拼接,便于数据格式的还原和对照。如果不需要做多个方法的对比或对转换后的数据列不作判别应用,则可以跳过本步骤,以及步骤4中的拼接过程。
步骤3
建立模型对象并进行转换输出。该过程中,主要使用的是OneHotEncoder库中的fit_transform方法直接训练并应用转换,然后使用toarray方法输出为矩阵。如果不使用toarray进行转换,那么输出的数据是一个3行5列的稀疏矩阵。
步骤4
将ID列和转换后的列拼接为完整主体,用于跟原始数据和通过方法1得到数据做比较。
得到的结果如下:
0 0 1 2 3 4
0 3566841 0.0 0.0 1.0 1.0 0.0
1 6541227 1.0 0.0 0.0 0.0 1.0
2 3512441 0.0 1.0 0.0 0.0 1.0
上述结果中,由于sklearn的转换算法是基于Numpy做矩阵计算的,因此无法直接使用字符串做转换。另外,输出的转换列的排序也不是按照预先的逻辑,笔者将通过自定义方法和sklearn方法得到的结果做比较,二者的数据是一致的,但是列的顺序却是不同的。如下图3-1:
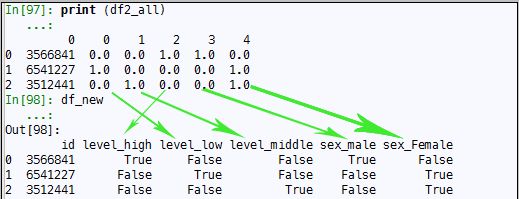 图3-1自定义转换和sklearn转换的列顺序对照
图3-1自定义转换和sklearn转换的列顺序对照
虽然列的顺序不同,但不会影响数据建模,因为列的顺序对建模不构成任何影响。只是在得到结果后,如果需要做基于特征的解读时,可能会导致无法对应到原始特征变量和转换值。如果是直接面向机器处理的应用则没有任何影响。
上述过程中,主要需要考虑的关键点是:
- 如何判断要转换的数据是分类或顺序变量
- 要在结果数据框中不断删除被转换的原始列并新增转换后的数据列,以防止数据列的重复
代码实操小结:本小节示例中,主要用了几个知识点:
- 通过pd.DataFrame构建新的数据框
- 通过pandas中的df[col_name]和iloc[]进行数据切片
- 通过pandas中的drop()方法删除特定列,当然也可以用于删除行
- 通过pandas的dtype获得对象的dtype类型,df.dtypes也能实现所有对象的类型
- 通过unique()方法获得唯一值
- 通过字符串组合(示例中直接使用的+)创建一个新的字符串
- 直接使用矩阵(Series)对象而无需遍历每个值进行矩阵比较和数值计算
- 通过pandas的df_new[col_name_new]方法直接新增列值