- 1.在P302“5.8.4 案例过程——步骤3 数据预处理——第二个函数是NA值替换”的描述中有误。(2018.3更已修正)
- 2.为本书写推荐语的两位大佬兴宝和郑来轶,兴宝老师的名字写错了,郑来轶老师的title也已经变更。在此致歉!(2018.3更已修正)
- 3.本书的P80第四行,有一段这样的描述“例如苹果iPhone7属于个人电子消费品,这样才能将_所有所有_商品分配到唯一类别属性值中”,其中出现了两个“所有”,该重复会重印时去掉。(2018.3更已修正)
- 4.本书的P60的最下面有一段代码中的output值写错(备注:在chapter2_code.py中的代码是正确的,只是在粘贴到word文稿时有问题)。(2018.3更已修正)
- 5.本书的P47代码中的print用法不规范。
- 6.本书的P53关于limit的解释有误。(2018.3更已修正)
- 7.本书的P39关于Numpy中float32的精度描述有误。(2018.3更已修正)
- 8.本书的P54最下面8)使用正则表达式查询具有复杂条件的数据的描述有误。(2018.3更已修正)
- 9.本书的P83最下面“第五部分通过sklearn的数据预处理方法对缺失值进行处理的内容中”的描述有错误。(2018.3更已修正)
- 10.本书的P82代码段中“使用sklearn将缺失值替换为特定值”的一段代码注释的描述有错误。(2018.3更已修正)
- 11.本书的P84上半部分中“第六部分使用Pandas做缺失值处理”解释文字中,有两行的示例举证颠倒。(2018.3更已修正)
- 12.本书的P86最下面“第三部分为缺失值判断过程”解释文字中,该段落的第一句有误。(2018.3更已修正)
- 13.本书的P117关于“3.7.1 如何检验共线性”中的容忍度的值域描述有误。(2018.3更已修正)
- 14.本书的P262关于“5.2.2会员营销指标”中的营销收入描述有误。(2018.3更已修正)
- 15.本书的P130关于“3.10.5 代码实操:Python数据离散化处理”中第四部分“第四部分针对多值离散数据的离散化”的描述有误。(2018.3更已修正)
- 16.本书的P165关于“4.1.6 代码实操:Python聚类分析”代码段中,“打印输出指标值”一段代码缺少\t分隔符。(2018.3更已修正)
- 17.本书的P194关于决策树规则解读是有一个数字错误。(2018.3更已修正)
- 18.本书的P191关于“相关知识点:混淆矩阵(confusion matrix)”中的TN/FP/NP的名称错误(2018.3更已修正)
- 19.本书的P209代码块中关于“数据准备”、“异常结果统计”模块中代码有误(2018.3更已修正)
- 20.本书的P228中关于“相关知识点:使用strftime将字符串解析为日期格式”的描述有误(2018.3更已修正)
- 21.本书的P166中的代码块中关于“模型应用”中predict方法中的参数(预测点)的shape有问题(2018.3更已修正)
- 22.本书的P300中的关于“df.isnull().any()”的解释有误(2018.3更已修正)
- 23.本书的P216代码块中的关于“pvalue1和pvalue2”和规则的对应有误(2018.3更已修正)
- 24.本书的P437代码块中的关于“使用fillna方法将“平均停留时间”中的缺失值替换为均值”的代码注释有误(2018.3更已修正)
- 25.本书的P423 part6代码块中的注释有误(2018.3更已修正)
- 26.本书的P364代码块中的注释有误(2018.3更已修正)
- 27.本书的P322“4.滞销金额”中的公式名称有误(2018.3更已修正)
- 28.本书的P311最下面的提示中的“Noen”应改为“None”(2018.3更已修正)
- 29.本书的P348最下面一段文字中的loos应该改为loss(2018.3更已修正)
- 30.本书的P378中图7-3下面的描述文字,有错别字(2018.3更已修正)
- 31.本书的P418计算整体波动量中“求相对昨天的环比变化率”的逻辑有误,对应到P419中的结果输出也错误,P415的图7-17数据结果图有误,P427的图7-19数据结果图有误(2018.11更已修正)
- 32.本书的page83第三部分通过“df.null”描述有误(2018.11更已修正)
- 33.本书的page101使用这种方法时“需要”描述有误(2018.11更已修正)
- 34.本书的page112使用“实施”计算的引擎描述有误(2018.11更已修正)
- 35.本书的page169最后使用“atplotlib”描述有误(2018.11更已修正)
- 36.本书的page295第五章的结论有误(2018.11更已修正)
- 37.本书的page216中的adf_val和p217中的acorr_val中print字符串有误(2018.11更已修正)
- 38.本书的page217中代码段的aic、bic和hqic代码有误(2018.11更已修正)
- 39.本书的P32页提示中的cvs应改为csv(2018.11更已修正)
- 40.本书的P196页关于提升度的计算结果有误
- 41.本书的P319页关于客单价公式的名称应该由“每订单金额”改为“客单价”
- 42.本书的第三章3.6的分层抽样的内层代码逻辑有问题
由于本书的作者水平有限并受限于有限的撰稿时间,以及整个出版环节众多可能会出现信息不对称,书中难免会出现一些错误或者不准确的地方,在此陈列出来供读者参考。这些已经发现的“错误”,会在下一次重印或再版时修正,有关修正的部分,会额外做标记,请读者朋友留意。
特别提示:由于第一版采用的仍然是Python2代码,因此在Python2下能正常工作,但是Python3下会出现的问题,不在此看勘误列表内。
最近更新时间:2019-04-22
提示:在2018年11月的第一版第三次重印中,更新了部分问题,请读者留意。辨别购买版本的问题,请读者翻到如下页面的框选处:

1.在P302“5.8.4 案例过程——步骤3 数据预处理——第二个函数是NA值替换”的描述中有误。(2018.3更已修正)
代码下面有一段如下的解释文字:
“功能实现过程中,先定义一个包括变量维度名称和对应的缺失值替换方法的字典,这里主要用到了均值mean和中位数median,其中均值用于数值型变量,中位数用于字符串变量;接着用df.fillna方法使用自定义的每列的不同方法批量替换缺失值;然后查看数据框中是否还存在缺失值并打印输出。”
其中“中位数用于字符串变量”的解释是错误的,原因是对于字符串变量而言,它是没有中位数的,他们只有gourpby 后的count(计数)信息,即每个字符串的频数分布,而频数分布跟中位数是不一样的概念。
对于字符串的NA填充,由于没有更多统计性指标,一种思路是可以使用count后的TOP值填充,但这种填充其实不符合真实情况;另一种思路是将NA作为一个特殊的字符串分类值,参与到后续的变量计算中。例如,假如性别的取值是男和女,如果对于性别中的NA值,可以填充为“未知”或对应的英文字母。
2.为本书写推荐语的两位大佬兴宝和郑来轶,兴宝老师的名字写错了,郑来轶老师的title也已经变更。在此致歉!(2018.3更已修正)
3.本书的P80第四行,有一段这样的描述“例如苹果iPhone7属于个人电子消费品,这样才能将_所有所有_商品分配到唯一类别属性值中”,其中出现了两个“所有”,该重复会重印时去掉。(2018.3更已修正)
4.本书的P60的最下面有一段代码中的output值写错(备注:在chapter2_code.py中的代码是正确的,只是在粘贴到word文稿时有问题)。(2018.3更已修正)
url = 'http://api.map.baidu.com/geocoder/v2/?address=%s&output=xml&ak=%s' # 请求URL
其中output后面的参数应该是json,即:
url = 'http://api.map.baidu.com/geocoder/v2/?address=%s&output=json&ak=%s' # 请求URL
否则无法返回下面的json字符串结果(其结果是以key-value形式存在的)。
5.本书的P47代码中的print用法不规范。
P47的代码
print ('Sheet1 Name: %s\nSheet1 cols: %s\nSheet1 rows: %s') % (sheet1_name, sheet1_cols, sheet1_nrows)
代码中的的用法是print something,其中something是要打印输出的对象。在本书的代码版本(2.7)中print 可以用两种方法:
print something # 早期版本
print(something) # 后期版本
其中第一种写法是早期版本的写法,可以直接print对象;后者是后期版本,也就是未来py3也兼容的版本。在后期版本中,print是一个函数,而something是print的参数值。
在本书中,由于2.7的版本是兼容这两种写法的,因此这样写不会有问题。但是考虑到未来py3一定是方向,因此建议读者用后期写法。上面的代码应该更正为:
print (('Sheet1 Name: %s\nSheet1 cols: %s\nSheet1 rows: %s') % (sheet1_name, sheet1_cols, sheet1_nrows))
关于代码还是需要规范起来,不然在不同的版本做迁移或升级时,容易出问题,请大家引以为戒。
6.本书的P53关于limit的解释有误。(2018.3更已修正)
在“1)只查询前N条数据而非全部数据行记录”的解释中,有如下一段文字:
“知识点:LIMIT为限制的数据记录数方法,语法为limit m, n,意思是从第m到_n-1_条数据。”。其中,n-1的描述有误,应该是从第m到m+n条数据,或从m开始偏移n条数据(也就是取n条数据)。
7.本书的P39关于Numpy中float32的精度描述有误。(2018.3更已修正)
在表2-4 Numpy数据类型中float32的描述中,其精度是23位,不是32位。
8.本书的P54最下面8)使用正则表达式查询具有复杂条件的数据的描述有误。(2018.3更已修正)
在“8)使用正则表达式查询具有复杂条件的数据”中的示例描述中“示例:查询user_id以_106_开头且order_id包含04的所有订单数据。”中的106有误,应该为103.
9.本书的P83最下面“第五部分通过sklearn的数据预处理方法对缺失值进行处理的内容中”的描述有错误。(2018.3更已修正)
在本段中,有一句“首先通过Imputer方法创建一个预处理对象,其中_strategy_为默认缺失值的字符串,默认为NaN”,其中的strategy应该为missing_values,而strategy是缺失值替换方法的变量。
10.本书的P82代码段中“使用sklearn将缺失值替换为特定值”的一段代码注释的描述有错误。(2018.3更已修正)
在本段代码如下:
# 使用sklearn将缺失值替换为特定值
nan_model = Imputer(missing_values='NaN', strategy='mean', axis=0) # 建立替换规则:将值为Nan的缺失值以均值做替换
nan_result = nan_model.fit_transform(df) # 应用模型规则
print (nan_result) # 打印输出
在上述代码中的第一段注释中“建立替换规则:将值为_Nan_的缺失值以均值做替换”,其中的Nan应该为NaN(第三个字母大写)。严格意义上,'NaN'和'Nan'是不同字符串,因此这里的描述应该跟代码中的missing_values的值一致。
11.本书的P84上半部分中“第六部分使用Pandas做缺失值处理”解释文字中,有两行的示例举证颠倒。(2018.3更已修正)
本段中有如下两行解释:
- pad和ffill:使用前面的值替换缺失值,示例中nan_result_pd1和nan_result_pd2使用了该方法。
- backfill和bfill:使用后面的值替换缺失值,示例中nan_result_pd3使用了该方法。
上面的描述中,示例中nan_result_pd1和nan_result_pd2使用的分别是backfill和bfill,而nan_result_pd3使用的是pad方法。两段的示例应该颠倒过来。
12.本书的P86最下面“第三部分为缺失值判断过程”解释文字中,该段落的第一句有误。(2018.3更已修正)
本段的原文如下“第三部分为_缺失值判断_过程。本过程中,先通过df.copy()复制一个原始数据框的副本用来存储Z-Score标准化后的得分...”。在该段落中,解释的是异常值,而非缺失值,因此本段的第一句应该为“第三部分为异常值判断过程”。
13.本书的P117关于“3.7.1 如何检验共线性”中的容忍度的值域描述有误。(2018.3更已修正)
在关于容忍度的描述中有如下一段文字“ 容忍度(Tolerance),容 忍度是每个自变量作为因变量对其他自变量进行回归建模时得到的残差比例,大小用1减得到的决定系数来表示。容忍度的值介于0.1和1之间,如果值越小,说明这个自变量与其它自变量间越可能存在共线性问题。”
由于容忍度是1-R2(R平方)得到的,而R2的值域是[0,1],因此容忍度的值域是[0,1],因此这里需要更正为“容忍度的值介于0和1之间”。
14.本书的P262关于“5.2.2会员营销指标”中的营销收入描述有误。(2018.3更已修正)
在关于营销收入的描述中,有一段如下的描述“会员营销收入是通过会员营销渠道和会员相关运营活动产生的_费用_,包括电子邮件、短信、会员通知、线下二维码、特定会员优惠码等。”其中“费用”应该更正为“收入”
15.本书的P130关于“3.10.5 代码实操:Python数据离散化处理”中第四部分“第四部分针对多值离散数据的离散化”的描述有误。(2018.3更已修正)
在P130页底部关于第四部分针对多值离散数据的离散化的描述中,有如下一段文字“第四部分针对多值离散数据的离散化。该过程中先通过dp.Dataframe定义一个新的转换区间,用来将原数据映射到新区间来;然后通过merge方法将原数据框和新定义的数据框进行关联,关联的两个key(left_on和_left_on_)分别是age和age...”,其中的第二个left_one应该更正为right_on。
16.本书的P165关于“4.1.6 代码实操:Python聚类分析”代码段中,“打印输出指标值”一段代码缺少\t分隔符。(2018.3更已修正)
在“打印输出指标值”一段代码中,有如下的代码:
print ('%d%.2f\t%.2f\t%.2f\t%.2f\t%.2f\t%.2f\t%.2f\t%d' % (
inertias, adjusted_rand_s, mutual_info_s, adjusted_mutual_info_s, homogeneity_s, completeness_s, v_measure_s,
silhouette_s, calinski_harabaz_s)) # 打印输出指标值
其中第一个打印字符串%d后面缺少\t,所以导致P168的输出结果中,ine和ARI的值没有间隔开。此段代码应该为:
print ('%d\t%.2f\t%.2f\t%.2f\t%.2f\t%.2f\t%.2f\t%.2f\t%d' % (
inertias, adjusted_rand_s, mutual_info_s, adjusted_mutual_info_s, homogeneity_s, completeness_s, v_measure_s,
silhouette_s, calinski_harabaz_s)) # 打印输出指标值
17.本书的P194关于决策树规则解读是有一个数字错误。(2018.3更已修正)
在决策树解读(树形图下面第三行)有如下一段话“上述决策树规则显示了当income< =55654时,总样本量为15348,其中负例样本和正例样本分别为13700、1648。当income<=55654且rfm_score<=7.8375时,总样本量有_13581,其中负例样本和正例样本分别为13700、881。以此类推可以读出其他的规则。”
其中的13581应为14581_
18.本书的P191关于“相关知识点:混淆矩阵(confusion matrix)”中的TN/FP/NP的名称错误(2018.3更已修正)
原文中对于TF/TN/FP/NP的解释如下:
表示分类正确:
-
真正(True Positive,TP):本来是正例,分类成正例。
-
假正(True Negative,TN):本来是负例,分类成负例。
表示分类错误:
-
假负(False Positive,FP):本来是负例,分类成正例。
-
真负(False Negative,FN):本来是正例,分类成负例。
其中:第二个TN应为真负、第三个FP应为假正、第四个FN应为假负。
19.本书的P209代码块中关于“数据准备”、“异常结果统计”模块中代码有误(2018.3更已修正)
在数据准备中有如下模块:
test_set = raw_data[:100, :] # 测试集
其中的raw_data[:100, :]应为test_set = raw_data[900:, :] 取后100个数据。
在异常结果统计模块中,有如下部分的代码:
n_test_outliers = outlier_test_data.shape[1] # 获得异常的结果数量
其中的shape[1]应该为shape[0],这里取的是记录数量(行数)。
上面的两段代码变更后,对应的输出统计结果的部分,更改为:
outliers:9/100
**************** all result data (limit 5) *****************
[[ 0.02556003 0.00803704 0.01359044 -0.01797511 0.02275128 1. ]
[ 0.03402373 -0.0051787 -0.02550607 -0.00169221 0.04747183 1. ]
[ 0.00586382 0.00212346 0.00672234 0.03181351 0.00295844 1. ]
[-0.01463104 -0.01212641 -0.01317896 0.0048775 -0.05054379 1. ]
[ 0.02214313 -0.02276267 0.02436253 -0.05875858 -0.01724721 1. ]]
20.本书的P228中关于“相关知识点:使用strftime将字符串解析为日期格式”的描述有误(2018.3更已修正)
本段相关知识点中,有一句如下描述“pandas中的datetime库是处理与日期相关主要功能库,其中的_strftime_用来将字符串解析为日期格式”,其中的strftime应为strptime。
21.本书的P166中的代码块中关于“模型应用”中predict方法中的参数(预测点)的shape有问题(2018.3更已修正)
在P166的左上角代码块中,模型应用有一段如下的代码:
# 模型应用
new_X = [1, 3.6]
cluster_label = model_kmeans.predict(_new_X_)
print ('cluster of new data point is: %d' % cluster_label)
在上述运行过程中,由于new_X是一个点,其shape是一维的,而predict的数据要求是二维的,因此默认运行会报错。

因此,需要对new_X的shape做reshape操作。有两种方法:
1.直接加[],代码如下:
# 模型应用
new_X = [[1, 3.6]]
cluster_label = model_kmeans.predict(new_X)
print ('cluster of new data point is: %d' % cluster_label)
2.先转换为numpy数组,然后用reshape方法做转换:
# 模型应用
new_X = np.array([1, 3.6]).reshape(1,-1)
cluster_label = model_kmeans.predict(new_X)
print ('cluster of new data point is: %d' % cluster_label)
上面两种方法,从便捷程度上来讲,肯定是第一种更方便;从实际应用的“标准化”方向上,第二种更合适,因为这种用法可以相对更清晰的了解到底new_X的shape是怎样的;而第一种需要先向上寻找信息,去了解new_X的定义情况。大家各取所需,但就1个点的简单应用而言,第一种更合适。
跟这个问题类似是P176“ 4.2.6 代码实操:Python回归分析”中的“模型应用”和P189“4.3.6 代码实操:Python分类分析”中的“模型应用”中的predict方法的应用。
在P176中的代码块中,
new_pre_y = model_gbr.predict(new_point) # 使用GBR进行预测
应该改为
new_pre_y = model_gbr.predict([new_point]) # 使用GBR进行预测
或
new_pre_y = model_gbr.predict(np.array(new_point).reshape(1,-1)) # 使用GBR进行预测
在P189中的代码块中,
y_pre_new = model_tree.predict(data)
应该改为
y_pre_new = model_tree.predict([data])
或
y_pre_new = model_tree.predict(np.array(data).reshape(1,-1))
22.本书的P300中的关于“df.isnull().any()”的解释有误(2018.3更已修正)
在该页中,有一段如下的解释“使用df.isnull().any()判断指定轴是否含有缺失值,当设置axis=0时以列为判断依据,当设置_axis=0_时以行为判断依据。”其中第二个axis=0应改为1,即当axis=1时以行为判断依据。
23.本书的P216代码块中的关于“pvalue1和pvalue2”和规则的对应有误(2018.3更已修正)
在该页的刚开始有如下代码:
lbvalue, pvalue1 = acorr_ljungbox(ts, lags=1) # 白噪声检验结果
adf, pvalue2, usedlag, nobs, critical_values, icbest = adfuller(ts) # ADF检验
rule_1 = (adf < critical_values['1%'] and adf < critical_values['5%'] and adf < critical_values['10%'] and pvalue1 < 0.01) # 稳定性检验
rule_2 = (pvalue2 < 0.05) # 白噪声检验
rule_3 = (i < 5)
代码中,从白噪声检验和ADF检验得到的结果值中的P值分别为pvalue1和pvalue2,这两个值下面的规则对应有误。正确的代码应该是:
lbvalue, pvalue2 = acorr_ljungbox(ts, lags=1) # 白噪声检验结果
adf, pvalue1, usedlag, nobs, critical_values, icbest = adfuller(ts) # ADF检验
rule_1 = (adf < critical_values['1%'] and adf < critical_values['5%'] and adf < critical_values['10%'] and pvalue1 < 0.01) # 稳定性检验
rule_2 = (pvalue2 < 0.05) # 白噪声检验
rule_3 = (i < 5)
24.本书的P437代码块中的关于“使用fillna方法将“平均停留时间”中的缺失值替换为均值”的代码注释有误(2018.3更已修正)
在P437中的中间靠上的部分,步骤4 数据预处理 中 使用fillna方法将“平均停留时间”中的缺失值替换为均值 的代码为:
data_fillna = raw_data.fillna(raw_data['平均停留时间'].mean()) # 用后面的值替换缺失值
代码注释中“用后面的值替换缺失值”应改为“用均值值替换缺失值”
25.本书的P423 part6代码块中的注释有误(2018.3更已修正)
在本页中的下半部分,有一段如下的代码:
split_node_list.append(min_increase_node) # 将分裂节点定义为增长最大值节点
其中的注释错误,应该将改为“# 将分裂节点定义为增长最大值节点”改为“# 将分裂节点定义为增长最小值节点”
26.本书的P364代码块中的注释有误(2018.3更已修正)
本页中的代码第二行中的注释,应将“分割输入变量X,并丢弃订单ID列和最后一列目标变量”改为“分割输入变量X,并丢弃订单ID列”,即去掉其中的“和最后一列目标变量”,正确注释代码为:
X_raw_new = X_raw_data.ix[:, 1:] # 分割输入变量X,并丢弃订单ID列
27.本书的P322“4.滞销金额”中的公式名称有误(2018.3更已修正)
其中的公式“销售金额占比 = 滞销金额 / 库存金额”应该改为“滞销金额占比”
28.本书的P311最下面的提示中的“Noen”应改为“None”(2018.3更已修正)
在描述文字中,有一段如下的文字:
“提示 使用read_excel方法读取Excel时,可以通过参数sheetname定义要读取哪个sheet的数据,其值可以定义为4种,数值、字符串、数值和字符串的混合列表以及Noen。其中数值代表sheet的索引值”
其中的Noen,应该改为None。
29.本书的P348最下面一段文字中的loos应该改为loss(2018.3更已修正)
在描述文字中,有一段如下的文字:
*loss:loos是GradientBoostingRegressor的损失函数,主要包括四种ls、lad、huber、quantile。ls(Least squares),默认方法,是基于最小二乘法方法的基本方法,也是普通线性回归的基本方法...
其中的loos应该改为loss。
30.本书的P378中图7-3下面的描述文字,有错别字(2018.3更已修正)
其中有如下一段文字:
“服务器日志、在线其他系统数据以及离线数据也可以通过特定FTP服务器上传数据,具体流程为:企业内部通过程序生成特定数据文档,将稳定自动上传到网站分析系统指定的FTP服务器,网站分析系统从FTP服务器采集数据,通过验证后处理数据。”
其中的“稳定”应该改为“文档”,即将文档自动上传到网站分析系统指定的FTP服务器。
31.本书的P418计算整体波动量中“求相对昨天的环比变化率”的逻辑有误,对应到P419中的结果输出也错误,P415的图7-17数据结果图有误,P427的图7-19数据结果图有误(2018.11更已修正)
在P418中,求相对昨天的环比变化率的计算方法为(今日-昨日)/今日,该逻辑应改为(今日-昨日)/昨日,对应到代码中:
day_change_rate = (day_change_value / day_summary).round(3).rename('change_rate') # 求相对昨天的环比变化率
这段应改为:
day_change_rate = (day_change_value.shift(-1) / day_summary).round(3).rename('change_rate').shift(1) # 求相对昨天的环比变化率
对应到P419中的输出结果应该为:
visit change change_rate date
2017-05-15 117260 NaN NaN
2017-05-16 166124 48864.0 0.417
2017-05-17 157727 -8397.0 -0.051
2017-05-18 155805 -1922.0 -0.012
2017-05-19 115644 -40161.0 -0.258
2017-05-20 120833 5189.0 0.045
2017-05-21 123145 2312.0 0.019
2017-05-22 113624 -9521.0 -
0.077 2017-05-23 131248 17624.0 0.155 2017-05-24 149783 18535.0 0.141 2017-05-25 112208 -37575.0 -0.251 2017-05-26 98556 -13652.0 -0.122 2017-05-27 125342 26786.0 0.272 2017-05-28 122626 -2716.0 -0.022 2017-05-29 134067 11441.0 0.093 2017-05-30 137391 3324.0 0.025 2017-05-31 150686 13295.0 0.097 2017-06-01 80334 -70352.0 -0.467 2017-06-02 90468 10134.0 0.126 2017-06-03 79892 -10576.0 -0.117 2017-06-04 91720 11828.0 0.148 2017-06-05 97115 5395.0 0.059 2017-06-06 97984 869.0 0.009 2017-06-07 79529 -18455.0 -0.188 2017-06-08 83676 4147.0 0.052 2017-06-09 74351 -9325.0 -0.111 2017-06-10 76256 1905.0 0.026 2017-06-11 78155 1899.0 0.025 2017-06-12 133994 55839.0 0.714 2017-06-13 77315 -56679.0 -0.423 2017-06-14 46273 -31042.0 -0.402
P415的图7-17应该为:
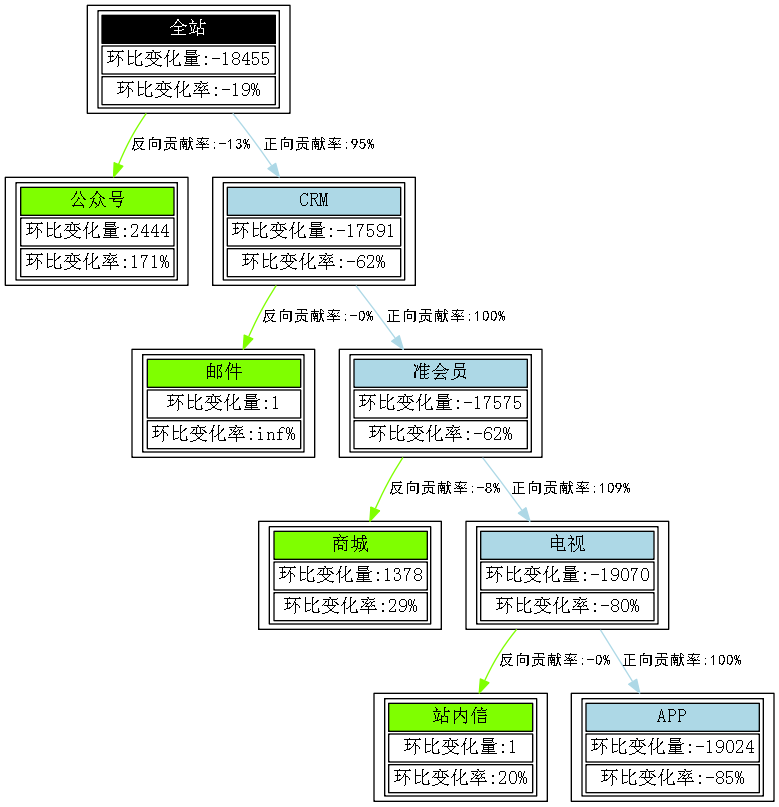
P427的图7-19应该为:

32.本书的page83第三部分通过“df.null”描述有误(2018.11更已修正)
本页中,在代码下面有一段如下的描述:
*“第三部分通过df.null()方法找到所有数据框中的缺失值(默认缺失值是NaN格式),然后使用any()或all()方法来查找含有至少1个或全部缺失值的列”,其中的df.null应该为df.isnull。
33.本书的page101使用这种方法时“需要”描述有误(2018.11更已修正)
本页中,有一段如下的描述:
*“使用这种方法时_需要_对样本本身做额外处理,只需在算法模型的参数中进行相应设置即可。很多模型和算法中都有基于类别参数的调整设置”,其中的需要应该为不需要。
34.本书的page112使用“实施”计算的引擎描述有误(2018.11更已修正)
本页中,有一段如下的描述:
*“以上的数据记录数不是固定的,笔者在实际工作时,如果没有特定时间要求,一般都会选择一个适中的样本量做分析,此时会综合考虑特征数、特征值域分布数、模型算法适应性、建模需求等;而如果是面向机器计算的工作项目时,一般都会选择尽量多的数据参与计算,而有关算法实时性和效率的问题会让技术和运维人员配合实现,例如提高服务器配置、扩大分布式集群规模、优化底层程序代码、使用_实施_计算的引擎和机制等。”,其中的实施应该为实时。
35.本书的page169最后使用“atplotlib”描述有误(2018.11更已修正)
本页中,有一段如下的描述:
*“第五部分模型效果可视化。先通过K均值模型对象的cluster_centers_方法获得类别中心点;然后定义一个颜色集用来显示不同类别样本的颜色;通过Matplotlib的figure 方法建立一块画布,再通过for循环读出每个类别,使用numpy的where方法得到不同分类下的数据集索引并建立各聚类数据子集,最后使用atplotlib的scatter方法 和plot方法做散点图展示聚类子集内的样本点以及中心,如图4-3。”其中的atplotlib应该为matplotlib。
36.本书的page295第五章的结论有误(2018.11更已修正)
在本页中,在“基于RFM得分业务方得到这样的结论:”一段中有如下描述:
-
*本周表现处于一般水平以上的用户的比例(R、F、M三个维度得分均在3以上的用户数)相对上周环比增长了1.3%。这种良好趋势体现了活跃度的提升。
-
*本周低价值(R、F、M得分为111以上)用户名单中,新增了1221个新用户,这些新用户的列表已经被取出。
这两段的描述中,由于RFM本身是基于相对区间划分的,在不同时间内的数据是不能直接用于对比的。例如:
上周的客户指标得分是1/2/3/4/5,最后的RFM得分也是1/2/3/4/5;
而如果本周的客户指标得分是11/12/13/14/15,那么最后的RFM得分仍然是1/2/3/4/5
因此,这种基于相对区间的划分是“一次性”的,而不应该用于直接对比。如果要对比,可以使用绝对值的划分方法,即自定义区间划分方法。例如<3时得分为1,3-5得分为2,5-8得分为3,以此类推。
37.本书的page216中的adf_val和p217中的acorr_val中print字符串有误(2018.11更已修正)
在adf_val中有如下代码:
print ('stochastic score') # 打印标题”
在acorr_val中有如下代码:
print ('stationarity score') # 打印标题”
这两段代码的标题应该互换,在adf_val中应该是:
print ('stationarity score') # 打印标题”
在acorr_val中应该是:
print ('stochastic score') # 打印标题”
38.本书的page217中代码段的aic、bic和hqic代码有误(2018.11更已修正)
P217 中间靠下的代码框中,其中
aic = tmp_bic # 最优模型ARMA的aic
bic = tmp_bic # 最优模型ARMA的bic
hqic = tmp_bic # 最优模型ARMA的hqic
应改为:
aic = tmp_aic # 最优模型ARMA的aic
bic = tmp_bic # 最优模型ARMA的bic
hqic = tmp_hqic # 最优模型ARMA的hqic
39.本书的P32页提示中的cvs应改为csv(2018.11更已修正)
本书的P32页提示中,有如下一段描述:
提示 大多数清下txt(任意指定分隔符)、cvs(以逗号分隔的数据文件)、tsv(以tab制表符分隔的数据文件)是最常用的数据文件格式。当数据文件大小在百兆级别以下时,可以使用Excel等工具打开;数据文件大小在百兆级别时,推荐使用Notepad打开;当数据文件大小在G级别时,推荐使用UltraEdit打开。
其中的“cvs”应该改为“csv”
40.本书的P196页关于提升度的计算结果有误
在左上角的关于提升度的计算中,其中有一段“在本示例中,Lift=(400)/(800)=0.5”的描述。在这个例子中,准确的Lift应该是:
Lift = P(B|A)/p(B)
即,在购买了A的人中同时购买了B的比例(也就是置信度)除以购买B的比例,因此应该是:
lIFT = (400/600)/(800/1000) = 0.67 / 0.8 = 0.83
41.本书的P319页关于客单价公式的名称应该由“每订单金额”改为“客单价”
本页中,关于客单价的定义,书中写为:
*每订单金额=订单金额/订单用户量
应该改为:
*客单价=订单金额/订单用户量
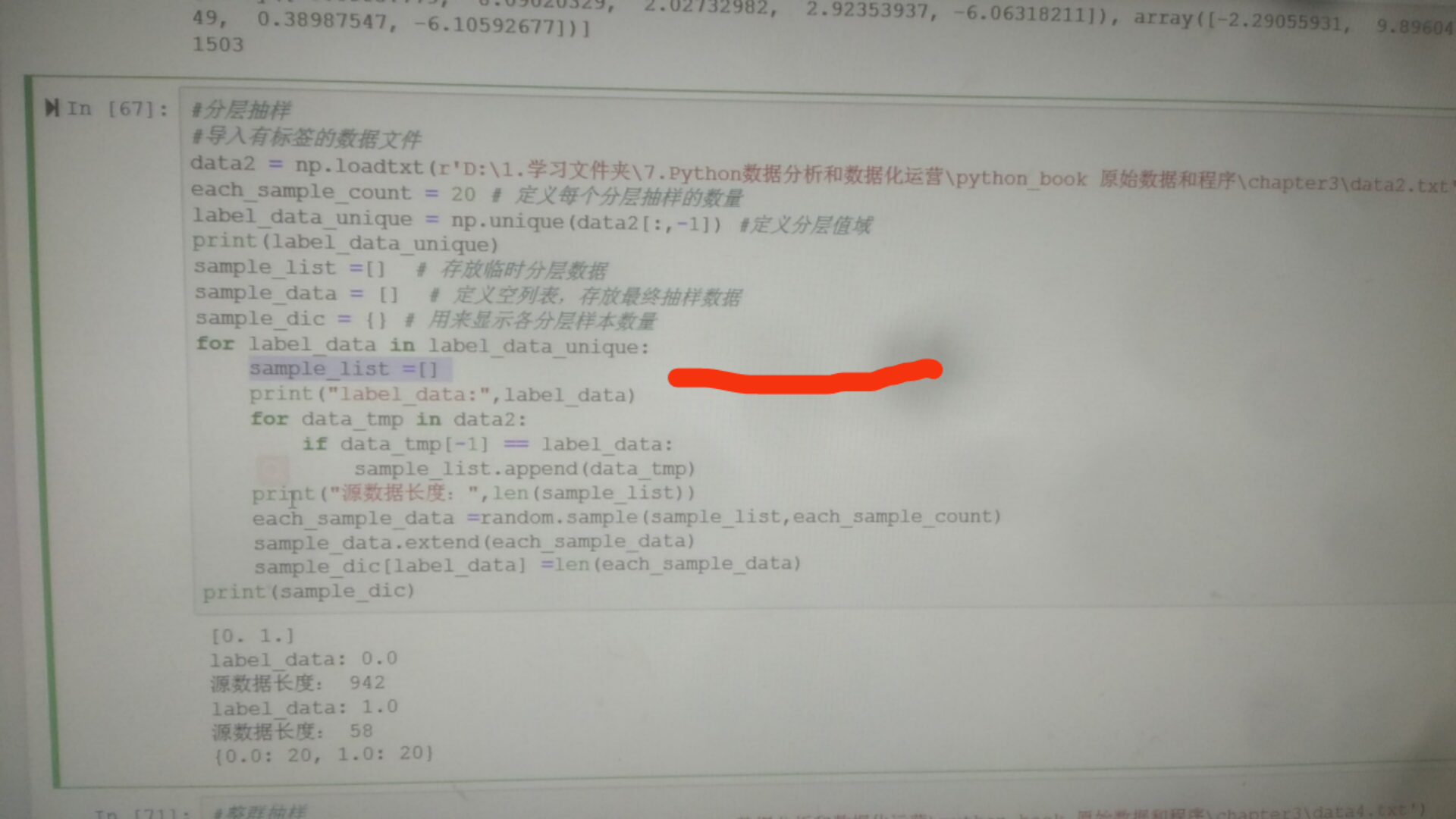
42.本书的第三章3.6的分层抽样的内层代码逻辑有问题
在本书第三章的3.6分层抽样过程中,sample_list(空列表)应该放在外层for循环里面,否则会导致抽样的sample_list中的结果会出现重复完整的值。正确的代码格式如下:
需要注意的是:由于原始文件的正样本为58,因为抽样200个样本会导致错误。所以,需要调低each_sample_count的值,例如50、30或20。
老师,第一章的第一个案例,在我本地环境执行报错,后来研究predict()的参数需要一个多维数组,我修改代码new_x = np.array(84610).reshape(1,-1) 后执行结果出来了。 修改前:new_x = 84610
是的,关于该问题,我已经更新到 常见问题里面了。常见问题
Scapy?是不是写错了,Scrapy...
是的,笔误,感谢指正!