- 1. 问题:第二版的书籍配套源代码下载地址?
- 2. 问题:第二版和第一版比有哪些变化?
- 3. 问题:为什么第五章5.7 案例-基于RFM的精细化用户管理中的from pyecharts import Bar3D导入错误?
- 4. 问题:第2章P55 "对于纯文本……,Python默认的3种方法更为合适"中的3种方法指的是什么?
- 5. 问题:P96 中位数做兜底策略? 兜底策略是什么技术?
- 6. 问题:第三章P91 维度行是什么意思呢?
- 7. 问题:get_dummies 和 onehotEncode使用上的场合或者是区别是什么?
- 8. 问题:为什么在P238导入pyecharts时会报错?
- 9. 问题:我看书上用的是mysql数据库,能用sqlserver代替吗?
- 10. 问题:为什么我的百度地图API调用无效?
- 11. 问题:P201设置的n_folds=5没有使用?
- 12. 问题:P93-P94的库使用,是否可以用Pandas,sklearn,而非书中的Pandas,sklearn,pandas这样的顺序?
- 13. 问题:P95各个打印的df对象分别是什么?
- 14. 问题:为什么我按照书上的内容敲代码,我的代码报错了?而其他人没报错??
- 15. 问题:为什么第四章我导入apriori的时候,提示没有这个库,但我已经安装了?
- 16. 问题:按照书本的内容,jupyter的插件显示不出来,勾不了,是啥原因呢?
- 17. 问题:请教一下,我依照3.10.1代码运行时,出现max() arg is an empty sequence,请问是什么情况导致的呢?
- 18. 问题:教材P231的关联规则输出结果中item2是后项还是前项?其中有"/"和“,”分别表示什么意思?
- 19. 问题:为什么第4章的关联图,使用pyecharts时,没有报错,但也没有结果展示?
- 20. 问题:为什么第7章最后的聚类雷达图,输出提示报错“ValueError: The number of FixedLocator locations (7), usually from a call to set_ticks, does not match the number of ticklabels (6).”?
在该文章中,仅总结第二版相关的问题,有关第一版的问题,请到“《Python数据分析与数据化运营》第一版常见问题”查看。
说明:由于第二版的出版时间为2019年,我已经将最新版本的代码更新到博客中,地址为:《Python数据分析与数据化运营》第二版新老版本代码对比。安装和使用最新版本的读者可参照该链接的代码。
最近更新时间:2021-06-15
1. 问题:第二版的书籍配套源代码下载地址?
代码下载: 《Python数据分析与数据化运营》第二版 附件
2. 问题:第二版和第一版比有哪些变化?
本书在第一版上市后,得到来自于各行各业很多好友和读者的支持和反馈,在此致以感谢!第二版在第一版基础上做了很多优化甚至重写,另外新增了很多内容。
优化以及重写的内容
- 全部代码基于Python3做优化或重写,书中的Python版本是7。
- 基于Jupyter做调试、分析和应用,更适合数据分析师的应用场景,包括探索性分析、数据预处理、结果可视化展示、交互式演示等。
- 网页数据解析中基于Class做功能封装和处理,更方便以网页对象为主体的数据工作。
- PIL/Pollow的替换和方法应用介绍,应用于图像处理工作
- 第四章数据挖掘的案例部分,每一部分的案例都经过重写,并增加了很多知识点,并以实际案例为需求,实际应用数据挖掘算法做建模和分析应用。
- Matplotlib调用3D图形展示多个维度的信息,并可通过拖拽展示不同角度下数据的分布情况。
- 第五章第一个案例RFM代码的重构,以及针对不同分组的精细化运营策略的制定。
- 第五章第二个案例基于嵌套Pipeline和FeatureUnion复合数据工作流的营销响应预测,基于复合(两层管道)的pipeline做数据工作流管理。
- 第六章第二个案例基于基于集成算法GBDT和RandomForest的投票组合模型的异常检测,将基础算法改为GBDT和RF,这两个是典型的代表模型“准确度”和“稳定度”的代表算法,这种兼顾“准”和“稳”的模型搭配更符合实际需求。
- 第七章基于自动节点树的数据异常原因下探分析的树形图的内容和可视化,优化了代码和样式,可视化效果更好并能获得更多信息,包括维度分解过程、主因子、其他因子和潜在因子等。
新增的内容
- 基于Anaconda的Python环境的安装和配置,更方便初学者快速搭建Python应用环境。
- Jupyter基础工具的用法,包括安装、启动、基础操作、魔术命令、新内核安装和使用、执行shell命令、扩展和插件使用、系统基础配置等。
- 基于Pandas的get_dummies做标志转换,即OneHotEncode转换。
- 特征选择的降维中新增feature_selection配合SelectPercentile、VarianceThreshold、RFE、SelectFromModel做特征选择。
- 特征转换的降维中新增PCA、LDA、FA、ICA数据转换和降维的具体方法。
- 特征组合的降维中新增基于GBDT、PolynomialFeatures、gplearn的genetic方法做组合特征。
- 第四章分类算法中新增使用XGboost做分类应用,以及配合graphviz输出矢量图形。
- pyecharts的数据可视化的应用和操作,尤其是关联关系图的应用。
- python通过rpy2调用R程序,实现关联算法的挖掘,包括直接执行程序文件、代码段、变量使用等。
- python通过rpy2调用airma实现自动ARIMA的应用,降低Python在时间序列算法应用时的门槛。
- 自动化学习:增加了对于自动化数据挖掘与机器学习的理论、流程、知识和应用库介绍,并基于TPOT做自动化回归和分类学习案例演示。
3. 问题:为什么第五章5.7 案例-基于RFM的精细化用户管理中的from pyecharts import Bar3D导入错误?
在pyecharts库中,pyecharts 分为 v0.5.X 和 v1 两个大版本,v0.5.X 和 v1 间不兼容,v1 是一个全新的版本。对应的语法也发生了较大的改变。
如果读者的环境是最新版(v1及之后),那么按照书中的from pyecharts import Bar3D 就会报错无法导入。
在v1版本之后,需要使用 from pyecharts.charts import Bar3D 方法导入Bar3D库。
所以,读者需要留意自己的pyecharts版本,然后选择对应的语法。

4. 问题:第2章P55 "对于纯文本……,Python默认的3种方法更为合适"中的3种方法指的是什么?
这里指的是使用open方法获得读取对象后,调用read、readline或readline读取的方法。

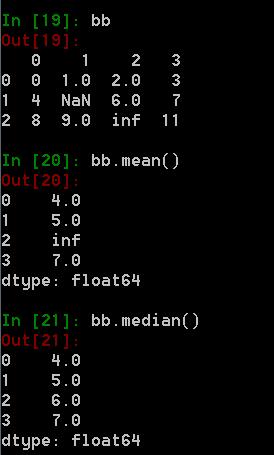
5. 问题:P96 中位数做兜底策略? 兜底策略是什么技术?
这里的“兜底策略”指在任意情况下,都能保障数据的一种方式,不是一种技术。如书中所讲,如果使用均值填充,那么当数据中存在inf时,无法计算其均值,而中位数则可以计算。这样可以保证填充的数值的有效性。例如:

6. 问题:第三章P91 维度行是什么意思呢?
在第三章P91中介绍变化维度表时,提到了维度行是什么意思呢?
该意思是,将每个变化的维度都记录下来,并形成新的记录,这样每次在匹配时,只需要匹配当时使用的维度即可。例如:
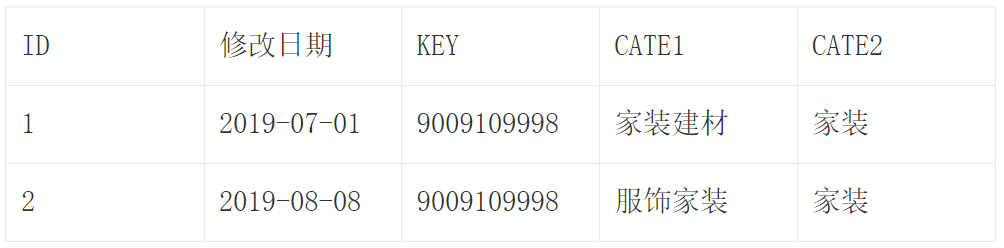
上面的表是一个变化维度表,里面的对的KEY是关联产品信息的键值,用来标记产品ID。在这个表中,基于ID可以匹配出产品类别。
在不同时期,该ID所属的一级分类(CATE1)有变化,例如2019年7月1日的值和2019年8月8日的属性值不同,这时可同时记录两个属性信息。这样后续可以基于修改日期判断,在不同周期下应该匹配哪个模式。
7. 问题:get_dummies 和 onehotEncode使用上的场合或者是区别是什么?
pandas的get_dummies 和 sklearn中的onehotEncode都能实现亚编码转换(书中称为标志转换),二者的使用区别在于:
- pandas的get_dummies 是“一次性”的,即用于单次的数据分析场景;
- sklearn中的onehotEncode 是“可复用”的,即在每次fit之后,一般后续继续其他与处理和模型训练;而如果在预测性应用中,例如分类或回归,则需要对新的数据再次做fit,这时候需要保证前面训练时的规则与后面对预测数据的规则保持一致,所以必须要用持久化的处理对象才能实现。这个原理跟模型训练和预测是相同的。
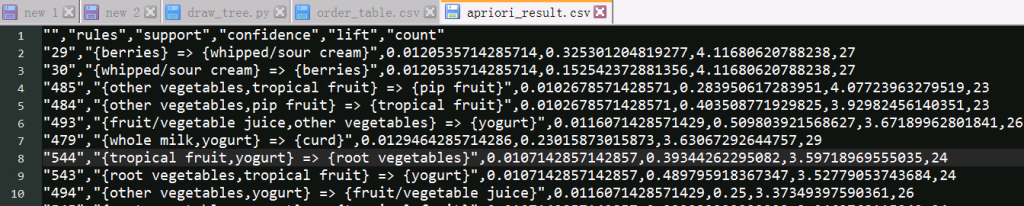
8. 问题:为什么在P238导入pyecharts时会报错?
本书第二版的pyecharts仍然基于v0.5的版本实现的,而现在最新的版本已经到v1.。目前pycharts中v1.与v0.5的版本是不兼容的,因此如果读者电脑上是v1.*的版本,那么执行pycharts展示图形时会报错。
在P238 创建关系图中,v1.*版本的代码如下:
# from pyecharts import options as opts # 先导入配置方法库
graph = Graph(init_opts=opts.InitOpts(width="800px", height="800px"))
graph.add("", nodes, edges, repulsion=8000,layout='circular',is_rot
ate_label=True) graph.set_global_opts(title_opts=opts.TitleOpts(title="商品关联结果图"))
请读者注意区别使用。有关完整的数据展示,也可以参照 [19. 问题:为什么第4章的关联图,使用pyecharts时,没有报错,但也没有结果展示?]
9. 问题:我看书上用的是mysql数据库,能用sqlserver代替吗?
Python支持几乎各种数据库,因此可以使用sqlserver代码mysql数据库,在使用时,安装并使用pymssql(第三方库),该库的用法几乎与pymysql相同;也可以使用pyodbc,通过odbc的方式连接sqlserver也是可以的,尤其是在大量(百万到千万)数据规模下,写入数据时设置fast_executemany = True,写入非常快。
10. 问题:为什么我的百度地图API调用无效?
笔者的百度API注册较早,目前的百度地图API已经升级URL地址,目前的的API地址格式为:
http://api.map.baidu.com/geocoder?address=地址&output=输出格式类型&key=用户密钥&city=城市名
而笔者的API地址为:
http://api.map.baidu.com/geocoder/v2/?address=%s&output=json&ak=%s
因此,后期注册的读者,请用百度最新的API格式,之前已经注册的API,可严用笔者书中的格式。
与百度地图API调用无效相关的另一个可能性是,部分读者没有自己注册新的账户,而目前笔者的API的调用资源已经接近限制值,所有会导致,直接使用笔者源代码中的代码和权限信息,导致无法正常返回信息。
11. 问题:P201设置的n_folds=5没有使用?
在P201页的 **n_folds=5**后续没有使用,可删除。
12. 问题:P93-P94的库使用,是否可以用Pandas,sklearn,而非书中的Pandas,sklearn,pandas这样的顺序?
是的,只是笔者在写作是没注意具体实现顺序问题。
13. 问题:P95各个打印的df对象分别是什么?
在P95-P96的各个打印对象中从上到下依次是:nan_result_pd1、nan_result_pd2、nan_result_pd3、nan_result_pd4、nan_result_pd5、nan_result_pd6,请读者注意区分
14. 问题:为什么我按照书上的内容敲代码,我的代码报错了?而其他人没报错??
我在自己的电脑上,按照书上的内容敲代码,但经常会报错。但是,其他人(本书读者)却没有发生类似的问题。为什么?
报错的原因有很多,这里的限制条件是:代码可以【在其他人的电脑上】正常运行,而在你的电脑上不行,很有可能是版本的问题。
本书的Python默认是3.7,采用anaconda安装。如果读者是自己安装的,或者即使用anaocnda安装的是3.6,那么也有可能出错。
例如:有读者自己通过其他途径,下载了anaconda3.6版本并安装,在第四章执行程序时,提示报错。后来经常查看,发现该读者用了3.6版本,对应的pandas的版本是0.20.,而我的版本是3.7,对应的pandas是0.25.。
虽然同一个库,不同的版本间功能大致相同。但也有些细微差异,例如:pandas0.20.中,对于默认缺失值的识别是不支持 null的,而在0.25.却可以。这会导致,如果数据中出现 null(注意是一个字符串),而使用0.20.版本的话,会默认将 null 识别为一个字符串,而是0.25.中,却可以识别为NULL值。
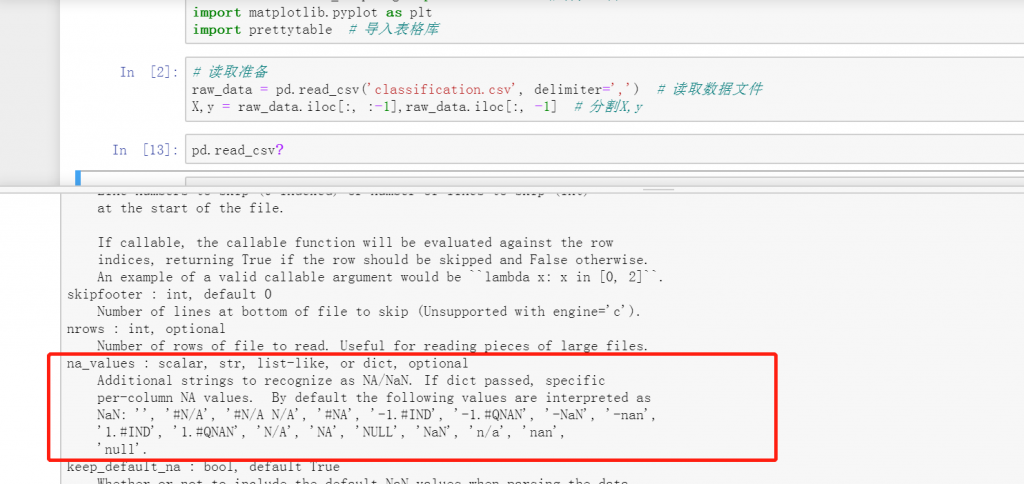
15. 问题:为什么第四章我导入apriori的时候,提示没有这个库,但我已经安装了?
该章P229中,导入库时,有如下两个部分:
import pandas as pd
import aprioir
上述代码中的apriori模块,是在当前“第四章附件目录”下的一个名为python.py的文件。

因此,在导入的时候,默认导入的就是这个文件的功能。而不是【读者】自己额外安装的第三方库。
这要求,当前的工作目录下,必须存在该文件。(在下载的默认的附件压缩包里面,默认就有)。如果没在该目录,只需要读者通过cd 命令切换到该目录(第四章)目录下即可。
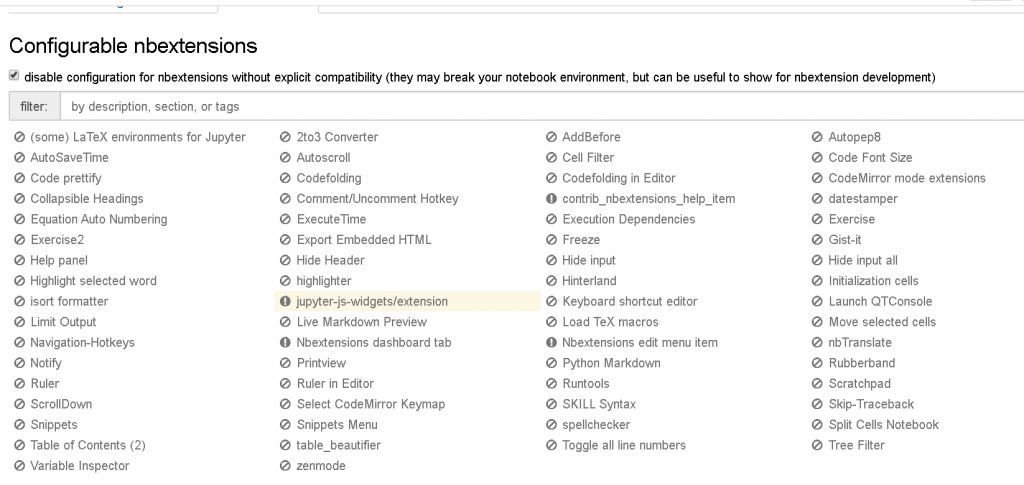
16. 问题:按照书本的内容,jupyter的插件显示不出来,勾不了,是啥原因呢?
安装书上的方式操作后,发现jupyter的插件都是无法选择配置,如何解决?
直接 取消勾选标题下面 disable configuration for ...的这段文字的复选框即可。
17. 问题:请教一下,我依照3.10.1代码运行时,出现max() arg is an empty sequence,请问是什么情况导致的呢?
之前的博客模板有问题。后续我修改了模板。现在我把模板更改回来了,目前(2020-10-12)代码已经能正常运行并返回正确数据。
18. 问题:教材P231的关联规则输出结果中item2是后项还是前项?其中有"/"和“,”分别表示什么意思?
在书的P231中,通过Python的关联规则会得到关联结果。其中的item1和item2分别表示后项和前项。其中的“ , ”表示两个前项或后项中两个不同的项目,例如pip fruit, other vegetables表示在该项目集中的2个项目。“/”则是项目本身的字符串,没有特殊含义,例如“whipped/sour cream”表示一个项目。
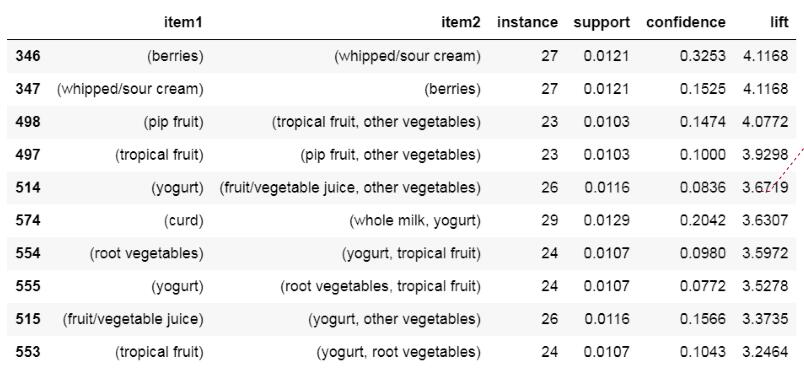
读者可参考P340通过R得到的关联规则,就比较容易理解前项和后项的规则。前项是规则的前面的部分,即条件;后项是规则后面的部分,即结果。前祥和后项都能包含多个项目,组成项目集。
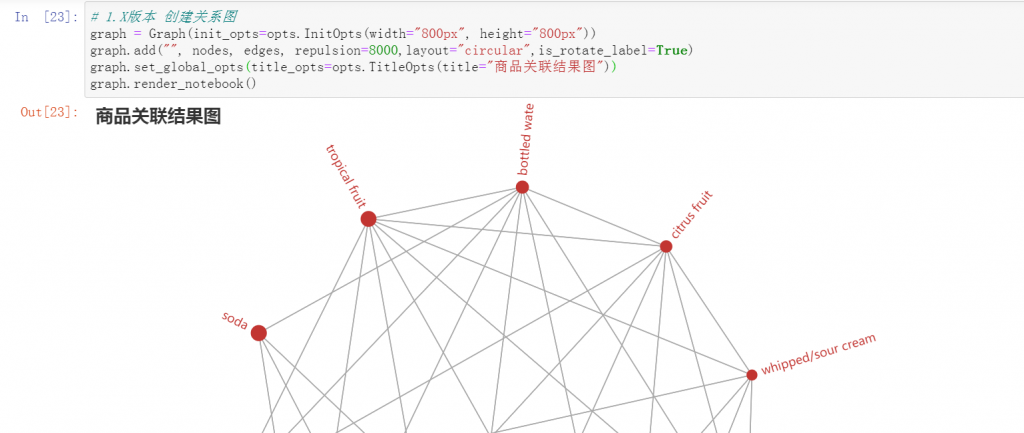
19. 问题:为什么第4章的关联图,使用pyecharts时,没有报错,但也没有结果展示?
第二版第四章的关联分析环节,调用pyechart展示关联结果时,无法加载图形。如果读者使用的是pyecharts的1.*版本,那么可使用如下代码:
# 导入库
from pyecharts.charts import Graph
from pyecharts import options as opts # 先导入配置方法库
# 1.X版本 创建关系图
graph = Graph(init_opts=opts.InitOpts(width="800px", height="800px"))
graph.add("", nodes, edges, repulsion=8000,layout="circular",is_rotate_label=True)
graph.set_global_opts(title_opts=opts.TitleOpts(title="商品关联结果图"))
graph.render_notebook()
20. 问题:为什么第7章最后的聚类雷达图,输出提示报错“ValueError: The number of FixedLocator locations (7), usually from a call to set_ticks, does not match the number of ticklabels (6).”?
新版本的matplotlib中,输出雷达图时,按照原书代 码执行会提示:
ValueError: The number of FixedLocator locations (7), usually from a call to set_ticks, does not match the number of ticklabels (6).
此时,只需要在labels中,额外增加对初始值的闭合即可,新代码为:
# part1 各类别数据预处理
num_sets = cluster_pd.iloc[:6, :].T.astype(np.float64) # 获取要展示的数据
num_sets_max_min = model_scaler.fit_transform(num_sets) # 获得标准化后的数据
# part2 画布基本设置
fig = plt.figure(figsize=(6,6)) # 建立画布
ax = fig.add_subplot(111, polar=True) # 增加子网格,注意polar参数
labels = np.array(merge_data1.index) # 设置要展示的数据标签
cor_list = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'w'] # 定义不同类别的颜色
angles = np.linspace(0, 2 * np.pi, len(labels), endpoint=False) # 计算各个区间的角度
angles = np.concatenate((angles, [angles[0]])) # 建立相同首尾字段以便于闭合
labels = np.concatenate((labels,[labels[0]])) # 新版本增加,对labels进行封闭
# part3 画雷达图
for i in range(len(num_sets)): # 循环每个类别
data_tmp = num_sets_max_min[i, :] # 获得对应类数据
data = np.concatenate((data_tmp, [data_tmp[0]])) # 建立相同首尾字段以便于闭合
ax.plot(angles, data, 'o-', c=cor_list[i], label=i) # 画线
# part4 设置图像显示格式
ax.set_thetagrids(angles * 180 / np.pi, labels, fontproperties="SimHei") # 设置极坐标轴
ax.set_title("各聚类类别显著特征对比", fontproperties="SimHei") # 设置标题放置
ax.set_rlim(-0.2, 1.2) # 设置坐标轴尺度范围
plt.legend(loc=0) # 设置图例位置
百度链接失效了
你好。感谢反馈。 你可以在这里找到所有新的下载链接入口:下载图书资源
在第四章4.4关联分析中 使用pyecharts画图展示中top_n_rules=item_count.sort_values(ascending=False).iloc[:control_num]报错 报错原因是AttributeError: 'function' object has no attribute 'sort_values' 想问一下应该怎么解决
提示说item_count是一个function,而正常情况下,应该是一个dataframe。所以你打印下item_count,看下是什么值,另外用type(item_count)看下类型。如果有问题,那么再看下item_concat的数据是否正确。
请问第二版什么时候开卖呀?
第二版已经上市了,在当当,京东,天猫都有。可以去京东、当当和天猫等查看。
宋老师,您好,第一章中: 销售预测应用 new_x = 84610 pre_y = model.predict(new_x) print(pre_y) 中会提示如下报错: ValueError: Expected 2D array, got 1D array instead: Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
这部分代码中,在新版的sklearn中,所有的数据都应该是二维矩阵,哪怕它只是单独一行或一列(比如前面做预测时,仅仅只用了一个样本数据),所以需要使用.reshape(1,-1)进行转换,具体操作如下。 new_x=84610 new_x=np.array(new_x).reshape(1,-1) pre_y = model.predict(new_x) print("预测销售额:",pre_y)
是的,感谢指出错误。该错误已经更新在勘误信息中:
勘误
3.4 处理样本分布不匀,源码 chapter3 中 data2.txt 应是数据有问题, 0 475 1 525 而不是 书中或代码中 0 942 1 58
是的,该信息已经更新到勘误中,谢谢提醒。 勘误
"# 使用岭回归算法进行回归分析\n", "model_ridge = Ridge(alpha=1.0) # 建立岭回归模型对象\n", "model_ridge.fit(x, y) # 输入x/y训练模型\n", "print(model_ridge.coef_) # 打印输出自变量的系数\n", "print(model_ridge.intercept_) # 打印输出截距" ] 使用这个方法python提示 NameError: name 'check_X_y' is not defined 是为什么呀
建立的arma模型,可以通过statsmodels自带的save函数进行持久化,但会被存储为pickle格式,不便于java读取,我查了一些关于pkl转pmml的方法,但至今找不到可用的方法。向您咨询一下,我考虑将训练后的模型应用于java,可有什么好的建议或者方法可以参考使用?谢谢!
预测函数predict_data()中,在画图时报错,predict_ts无法继续画出来。 plt.figure() # 创建画布 ts.plot(label='raw time series') # 设置推向标签 predict_ts.plot(label='predicted data', style='--') # 以虚线展示预测数据
报错信息:ValueError: view limit minimum -36866.1 is less than 1 and is an invalid Matplotlib date value. This often happens if you pass a non-datetime value to an axis that has datetime units Error in callback <function install_repl_displayhook..post_execute at 0x0000000008D29840> (for post_execute):
里面提示了你传入的应该是一个非日期时间格式的值进去,你测试下看看ts的index类型,是否是datetime类型。
正解,按照您说的方法,将ts.index转换为datetime类型,解决了。谢谢指导!
OK,好滴呀。
第6章的案例,使用集成算法,按书中代码,最后预测的订单数是846,和书中的预测的订单数833有差异,这个是什么原因呢?
在算法里面,有一个非常重要的概念叫 随机,在模型的实现中,很多算法都有random_state 这个参数,这个参数可以控制随机种子的值。通过设置在多次执行时可以保障相同的随机起始点。 你和我的电脑环境并不是1个电脑,所以即使设置相同的值,也不能获得完全相同的结果。模型在拟合的时候会有略微的“差距”,所以这个是正常的。
请教一下,我依照3.10.1代码运行时,出现max() arg is an empty sequence,请问是什么情况导致的呢?
你好。之前博客的模板有点问题,我现在调整了。现在代码执行是正常的了.
mark:由于新博客迁移了模板,因此该代码目前仍无法执行。