3.7.1 用户访问行为的渠道概述
在做渠道组合投放管理时,也可以从用户的实际访问行为中获得启发,尤其是在考虑少量渠道的组合应用时非常有效。例如用户经常从A渠道进入网站后,再次从B渠道进入网站,那么渠道A和B之间可能具有用户先后序列访问的行为模式,基于此规律,可以考虑二者组合投放,这是一种行之有效的投放组合策略。
3.7.2 如何识别用户访问的来源渠道
用户访问的来源渠道识别通常有两种模式:
一是根据每次用户进入网站中服务器日志的“引荐信息”获得,其中包含的引荐URL信息可用于识别流量来源。默认情况下,无需对这部分流量做额外特殊跟踪,网站分析工具都能自动监测流量来源。其主要用于免费流量(包括直接流量、SEO、普通引荐)的识别。下面的服务器日志中显示了该流量来源于搜狗搜索(SEO),其中带有下划线的代码部分即引荐来源信息:
222.205.124.49 - - [07/Nov/2020:20:32:00 +0800] "GET /blog/%E6%A0%B8%E5%AF%86%E5%BA%A6%E4%BC%B0%E8%AE%A1kernel-density-estimation_kde/ HTTP/1.1" 200 14337 "https://www.sogou.com/link?url=DSOYnZeCC_rOa9S9HGoZlgS1AKqQSICX_fU-xPzM98XFyFUQtznX-irV7zLx_4TVerovoi_5RVaVBc3qzlRJKXi4p8rCD0I11FvEOmdAJO9-SoJmoYjj9bUAynT_xcgQtTisceZxUbk." "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0"
二是根据站外URL的参数标记实现的来源跟踪,这是监测站外付费广告投放的标准实施方法。该方式需要广告投放人员在站外的广告落地页链接中进行特殊参数标记。以某网站的百度品专投放链接为例,其落地页URL中使用了utm参数标记来源渠道、媒介、广告活动、关键字等信息:
https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_98bbf2df7907480cbc3409708bf3b4d8
当上述自定定义标记完成并有流量进入网站后,在网站分析工具中可以看到如图3-23渠道流量报告。该报告在Google Analytics中的“流量获取”-“所有流量”-“渠道”中,主要维度是“来源/媒介”,其中包含了付费流量(例如google/cpc、facebook/ocpm等)和免费流量(例如(direct)/(none)、google/organic)。
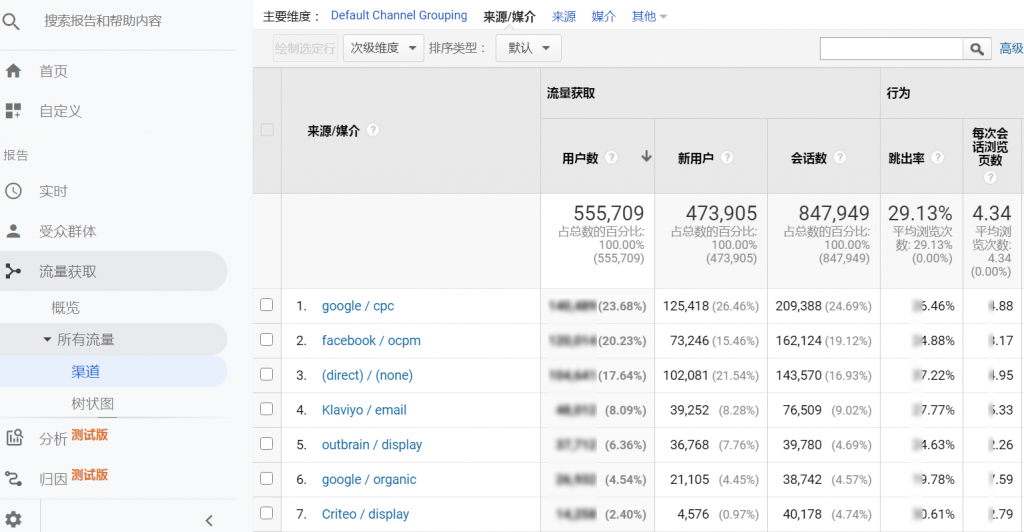
图 3-23 Google Analytics中的流量渠道报告
3.7.3 通过序列关联模式挖掘渠道组合策略
本案例以网站分析系统(Google Analytics)的流量数据为例,分析其中是否存在较强的渠道组合模式。该案例借助于Python的第三方库prefixspan实现。有关Python环境的准备以及附件压缩包的配置,请见“附录2 通过Anaconda准备Python环境”。
点击图3-24中的①“Anaconda Powershell Prompt (Anaconda3)”,在新打开的shell窗口中,输入“pip install prefixspan”来通过pip方法安装prefixspan库,安装完成后会出现“Successfully”字样;再点击②“Jupyter Notebook (Anaconda3)”在浏览器中进入Jupyter环境。
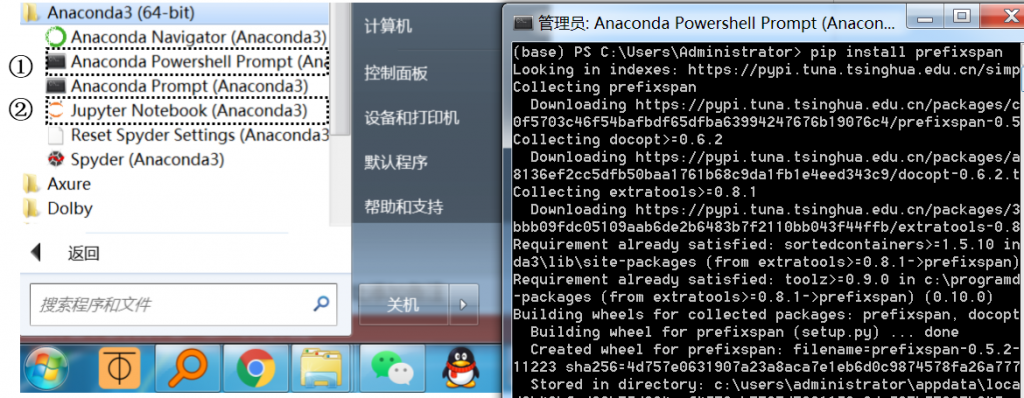
图 3-24 Jupyter程序入口
按照“附录2 通过Anaconda准备Python环境”中的“2. 将附件压缩包解压到C:\Users\Administrator目录”配置完成后,会出现图3-25中“流量数据化运营_附件”入口,点击进入目录会出现附件文件列表,点击 “第3章.ipynb”查看本案例代码及执行结果。
图 3-25 Jupyter中的附件入口
Python实现过程具体如下:
第1步 导入库
from prefixspan import PrefixSpan #①
import pandas as pd #②
代码①中导入prefixspan中的PrefixSpan方法,后续使用PrefixSpan来实现序列模式的挖掘。代码②导入Pandas库并指定别名为pd,后续使用pd来代替Pandas实现数据处理。
第2步 读取数据
df = pd.read_excel('第3章.xlsx',sheet_name='3-7') #①
print(df.head()) #②
print(df.info())
代码①使用pandas的read_excel方法,从“第3章.xlsx”中sheet名为3-7的工作簿中读取所有数据。代码②使用print方法打印读取结果,df.head方法默认展示前5行结果。打印展示的目的是查看数据是否读取正常,包括字段正常识别、中文是否有乱码、值是否正确等,经过查看如下结果,数据读取正常:
CookieID 时间戳 渠道类型 渠道
0 2234102182402625 2013-05-22 05:14:12 sem baidu
1 2227486864700747 2013-05-25 16:30:02 dh hao123
2 2360671593636464 2013-05-27 03:00:00 snm weibo
3 3007709982402625 2013-05-25 10:58:41 bd 360
4 1842085682402625 2013-05-27 12:56:14 sem baidu
代码③print结合df.info()方法打印数据框的详细信息,主要用于查看字段类型、缺失值情况等。关键信息包括:数据框中共有数据记录260条,一共四个字段且都没有缺失值(non-null),CookieID为数值型(int64),时间戳为日期时间类型(datetime64[ns]),渠道类型和渠道是字符串型(object)。
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 260 entries, 0 to 259
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CookieID 260 non-null int64
1 时间戳 260 non-null datetime64[ns]
2 渠道类型 260 non-null object
3 渠道 260 non-null object
dtypes: datetime64[ns](1), int64(1), object(2)
memory usage: 8.
2+ KB
第3步 按时间戳排序
该步骤的意义是基于用户的访问时间戳,对来源渠道进行排序。该步骤需要确保时间戳是日期时间类型,而不能是字符串类型,否则用户实际访问渠道可能无法正确排序。
data = df.sort_values(['CookieID','时间戳'],ascending=True) #①
print(data.head()) #②
代码①使用数据框的sort_values方法基于CookieID和时间戳排序,通过ascending=True指定为正序排序,即时间早的值在前面。代码②打印排序后的数据的前5条结果如下:
CookieID 时间戳 渠道类型 渠道
205 13878050023 2013-12-24 00:38:17 ad youjian
127 13878105793 2013-12-24 17:00:26 cps yiqifa
77 1841745023299541 2013-12-25 02:43:58 sem baidu
212 1841745023299541 2013-12-25 19:10:58 sem baidu
213 1841745023299541 2013-12-30 21:58:00 sem baidu
上述结果可以看到数据已经正确排序。当用户出现多个渠道记录时,越早的记录越靠前。
第4步 将用户的渠道数据从事务性记录格式转换为序列格式
该模型要求数据的格式必须是基于列表的序列格式,因此需要转换原始事务性记录格式。
ids = data['CookieID'].unique().tolist() #①
seq_data = [data[data['CookieID'] == i]['渠道'].tolist() for i in ids] #②
frequent_seq_data = [i for i in seq_data if len(i) >= 2] #③
print(frequent_seq_data[:2]) #④
代码①目标是获得所有用户的CookieID的集合,先通过data['CookieID'].unique()获得用户CookiID的唯一值,并通过tolist()方法转换为列表格式。代码②目标是获得所有用户访问渠道的序列集合,通过列表推导式,将每个用户的所有渠道数据取出来并转化为列表格式,由此形成了列表嵌套,外层列表为所有用户的集合,内层列表是每个用户访问渠道的序列集合;其中data[data['CookieID'] == i]['渠道'].tolist()的含义是从data数据框中将CookieID等于i的用户的渠道过滤出来,然后转换为列表格式,其中的i是for循环获得的每个用户的CookieID值。代码③目标是将访问了超过2个渠道的列表保存下来,目的是降低后续计算量并提高运行效率;该过程通过列表推导式实现,列表推导式中,通过for循环遍历每个子列表(用户访问渠道列表),将访问渠道数量≥2的保存下来。代码④打印处理后的列表的前2条记录:
[['baidu', 'baidu', 'baidu', 'baidu', 'baidu'], ['baidu', 'baidu']]
结果中的第一个列表['baidu','baidu', 'baidu', 'baidu', 'baidu'] 表示用户A先后5次都从baidu进入网站;第二个列表为['baidu','baidu']表示用户B先后2次都从baidu进入网站。用户A和用户B为两个不同的用户。
第5步 建立序列模型并查找规则
该步骤实现序列模式的提取和挖掘,从中提取频繁的用户访问渠道的规则。
ps = PrefixSpan(frequent_seq_data) #①
ps.maxlen = ps.minlen = 2 #②
top_rules = ps.topk(100) #③
print(top_rules[:4]) #④
代码①通过PrefixSpan建模序列挖掘模型对象ps。代码②通过ps的maxlen和minlen设置挖掘频繁项集时项目的数量为2,这样做的目的是只分析2个渠道之间的相互关系,而把超过2个渠道的规则去掉,例如['360', 'kongque']中的项目为2个,而['360', 'kongque', 'hao123']中的项目为3个,由于前者是后续的子集,因此我们只需要提取出子集来即可;否则两个集合之间存在规则重叠关系。代码③使用ps的topk方法提取最频繁的前100个序列关联规则。代码④打印输出前4个结果:
[(9, ['baidu', 'baidu']), (7, ['360', '360']), (7, ['360', 'kongque']), (7, ['kongque', '360'])]
top_rules中的每个规则结果都包含三个要素,以(9, ['baidu', 'baidu'])为例,这是一个元组,元组的第一个元素是支持度,第二个元素是由前项和后项组成的规则。支持度越高,说明规则本身越频繁,也就意味着有越多的用户习惯于通过这两个渠道先后进入网站。
第6步 将数据转换为数据框
上述列表格式不便于查看和处理数据,我们转换为数据框。
rules = [[i[0], i[1][0], i[1][1]] for i in top_rules]#①
sequences = pd.DataFrame(rules, columns=['SCORE', 'ITEM1', 'ITEM2']) #②
sequences = sequences.sort_values(['ITEM1','SCORE'], ascending=False) #③
sequences['SCORE_RATE'] = sequences['SCORE']/len(frequent_seq_data) #④
sequences.head() #⑤
代码①中将元组的第二个元素(规则)中的前项和后项拆分为单独的元素。代码②使用pd.DataFrame建立新的数据框,指定列名为'SCORE'、'ITEM1'、'ITEM2',其中SCORE为支持度,ITEM1为前项渠道,即前面出现的渠道,ITEM2为后项渠道,即后面出现的渠道。代码③使用数据框的sort_values方法对'ITEM1'和'SCORE'排序,通过ascending=False指定倒序排序,即支持度得分高的在前面。代码④基于支持度数值计算规则出现的比率,用于分析不同规则出现的“频率”,这样我们能从数量和比率两个角度分析规则的有效性;通过SCORE除以len(frequent_seq_data)得到的有效ID的数量得到结果。代码⑤打印前5条记录查看结果:
SCORE ITEM1 ITEM2 SCORE_RATE
28 5 youjian kongque 0.416667
54 4 youjian 360 0.333333
55 4 youjian baidu 0.333333
56 4 youjian hao123 0.333333
57 4 youjian sogou 0.333333
由此我们得到的序列关联分析结果。该结果在使用时,可按照特定渠道单独筛选其可能的组合渠道,例如通过print(sequences[sequences['ITEM1']=='baidu'].head())打印出可以与百度(前项)一起投放组合的TOP渠道,结果如下:
SCORE ITEM1 ITEM2 SCORE_RATE
0 9 baidu baidu 0.750000
12 5 baidu 360 0.416667
13 5 baidu kongque 0.416667
14 5 baidu yiqifa 0.416667
30 4 baidu dianxin 0.333333
也可以基于SCORE的支持度总排名,将支持度最高的渠道组合先拿出来,再做后续投放分析,代码为print(sequences.sort_values(['SCORE'], ascending=False).head()),得到如下结果:
SCORE ITEM1 ITEM2 SCORE_RATE
0 9 baidu baidu 0.750000
2 7 360 kongque 0.583333
3 7 kongque 360 0.583333
1 7 360 360 0.583333
4 6 kongque kongque 0.500000
3.7.4 基于用户访问行为的渠道组合策略的限制条件
基于用户访问行为的渠道组合策略依赖于用户的到站和渠道识别,如果用户仅仅在站外产生广告曝光但没有进入网站,那么无法产生流量数据。除此以外,这种行为模式还可能存在以下问题:
多设备、多浏览器的行为模式的干扰
例如用户先从手机访问百度进入网站,再从电脑上通过信息流广告进入网站,正常的用户行为模式应该别识别为百度→信息流。但在这个过程中,由于不同设备会生成不同的Cookie,导致用户的跨设备行为无法直接关联匹配,因此该路径无法形成,在报告中将显示为两个不同的人及其对应的渠道数据。
Cookie 的失效问题
Cookie失效指Cookie无法正确工作并用于识别匿名用户,潜在问题场景包括:浏览器禁用Cookie跟踪(目前很多浏览器都有该功能)、Cookie过期(默认每个Cookie都有过期时间,超过该时间则会生成新的Cookie,导致对用户的识别标志发生改变)、用户手动清楚Cookie、特定第三方工具删除或清理Cookie及缓存等。
企业投放的媒体覆盖度不够
受限于广告预算以及媒体碎片化问题,很多企业无法投放大量的广告媒体并从中获得直接可参考的数据,这会导致由于覆盖的媒体以及投放数据不够,无法产生有效的序列关联规则。
3.7.5 知识拓展:将渠道组合策略扩展到跨设备领域
在“3.7.4 基于用户访问行为的渠道组合策略的限制条件”提到了多设备、多浏览器的行为模式的会干扰序列规则的产生。但企业可以通过激励措施引导用户留下唯一联系信息,实现多个设备信息的Mapping,典型的唯一信息包括:登陆ID(同CRM中的用户ID)、手机号、Email、设备ID(在手机APP上的MAC地址、手机串号等)等,在一定时间内,这些ID不会频繁变动,因此只要能获取到这些信息,在企业后台就能建立一个全局用户ID来将CookieID与这些ID关联起来。
在实际数据中,能够获得多个渠道关联ID信息的用户量相对总体用户来看占比较少。以登陆为例,普通自营电商网站登陆用户的比例大概占总访问用户的10%左右。但是,我们仍然可以将这10%的群体作为典型研究用户,因为这些用户的后续转化价值相对较高(登陆用户更具有转化意向),研究这些群体的用户行为模式将更有利于将转化目标(高转化率)与流量目标(渠道组合投放引流)结合起来。
得到了用户跨设备的关联访问路径,可以在渠道投放组合中产生更多的玩法。例如:将PC端流量渠道A与Mobile端的渠道B组合,具体策略可能是先在PC端投放A渠道3天,然后再在Mobile端投放渠道B。这样就能将原来局限于相同平台或设备的投放策略延伸到跨设备投放策略上去,这种基于数据的组合投放策略将更利于效果达成。