[K-Means算法]是常用的聚类算法,但其算法本身存在一定的问题,例如在大数据量下的计算时间过长就是一个重要问题。为此,Mini BatchK-Means,这个基于K-Means的变种聚类算法应运而生。 大数据量是什么量级?通过当样本量大于1万做聚类时,就需要考虑选用Mini Batch K-Means算法。但是,在选择算法时,除了算法效率(运行时间)外,算法运行的准确度也是选择算法的重要因素。Mini Batch
K-Means算法的准确度如何?
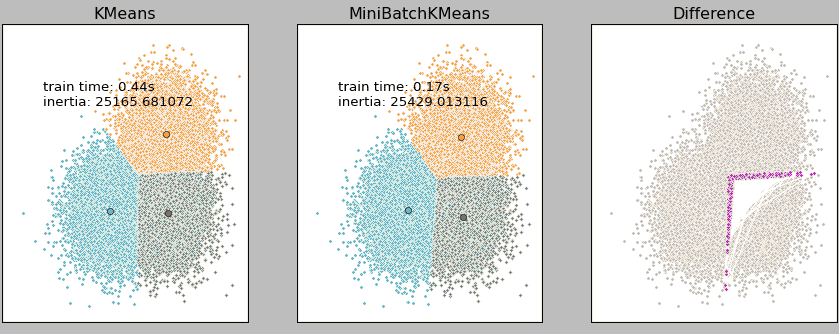
上图是我们队3万的样本点分别使用K-Means和Mini Batch KMeans进行聚类的结果,由结果可知,在3万样本点的基础上,二者的运行时间相差2倍多,但聚类结果差异却很小(右侧粉红色的错误点)。
因此,Mini Batch KMeans是一种能尽量保持聚类准确性下但能大幅度降低计算时间的聚类模型。
K-Means的计算时间到底跟样本量之间是怎样的关系(用脚想也知道是样本量越大,计算时间越长),我们用一个实例来实验下。在下面的例子中,利用Python生成一个具有三个分类类别的样本类,其中的样本点(二维空间)的数量从100开始增长到1000000(步长为1000),我们用图例来看看计算时间与样本量的关系。(为了得到下面这幅图,我等了2个小时)结果如下:
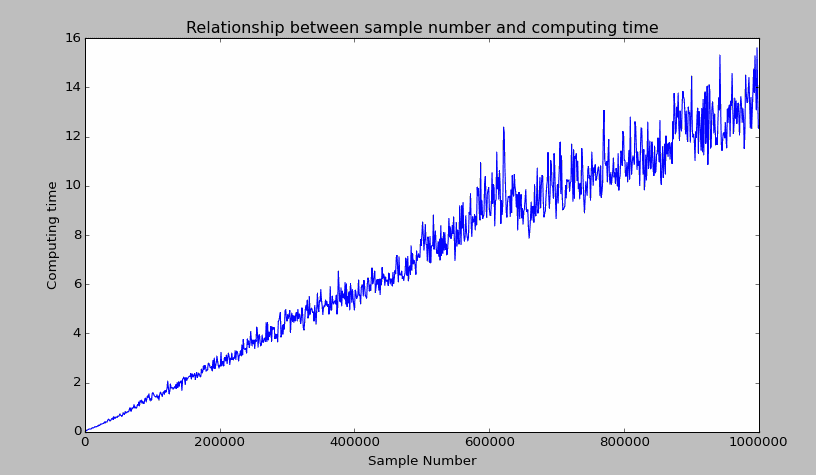
从图中可以发现,在样本点为二维空间前提下,当数据量在2之下时,计算时间都可以接受(2秒以内);但是计算时间跟数据量基本成线性关系,计算1000000个样本聚类耗时近16秒。由此可以试想,如果你的观测点有更多维度(更多维度意味着需要更多的计算量),那么耗时将比上述场景大很多。
回到本文的主体算法Mini Batch KMeans上来,应用Mini Batch KMeans能尽量在保持数据准确性的前提下降低运算时间,它是怎么做到的?
Mini Batch KMeans使用了一个种叫做Mini Batch(分批处理)的方法对数据点之间的距离进行计算。Mini Batch的好处是计算过程中不必使用所有的数据样本,而是从不同类别的样本中抽取一部分样本来代表各自类型进行计算。由于计算样本量少,所以会相应的减少运行时间,但另一方面抽样也必然会带来准确度的下降。
实际上,这种思路不仅应用于K-Means聚类,还广泛应用于梯度下降、深度网络等机器学习和深度学习算法。
Mini Batch KMeans的使用方法非常简单,跟K- Means一样,在Python的机器学习库SKlearn中,通过fit方法训练数据,然后通过labels_ 属性获得每个样本点的聚类结果值。演示代码如下:
import numpy as np
from sklearn.cluster import MiniBatchKMeans
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
clf = MiniBatchKMeans(n_clusters = 3)
clf.fit(X)
pre_clu = clf.labels_
#将原始数据集X和聚类结果标签组合成新数据集并输出前10条
new_X = np.column_stack((X, pre_clu))
print new_X[:10]
运行结果如下:
array([[ 5.1, 3.5, 1.4, 0.2, 1. ],
[ 4.9, 3. , 1.4, 0.2, 1. ],
[ 4.7, 3.2, 1.3, 0.2, 1. ],
[ 4.6, 3.1, 1.5, 0.2, 1. ],
[ 5. , 3.6, 1.4, 0.2, 1. ],
[ 5.4, 3.9, 1.7, 0.4, 1. ],
[ 4.6, 3.4, 1.4, 0.3, 1. ],
[ 5. , 3.4, 1.5, 0.2, 1. ],
[ 4.4, 2.9, 1.4, 0.2, 1. ],
[ 4.9, 3.1, 1.5, 0.1, 1. ]])
应用场景,由于Mini Batch KMeans跟K-Means是极其相似的两种聚类算法,因此应用场景基本一致,具体请参考[K均值(K-Means)] 其中,Mini Batch KMeans可配置的参数如下:
class sklearn.cluster.MiniBatchKMeans(n_clusters=8, init='k-means++', max_iter=100, batch_size=100, verbose=0, compute_labels=True, random_state=None, tol=0.0, max_no_improvement=10, init_size=None, n_init=3, reassignment_ratio=0.01)
尾巴
默认情况下,无论是K-Means还是MiniBatchKMeans都是需要指定聚类数量,即算法里面的n_clusters参数值,但实际应用时发现不指定也是可以的。这并不意味着Python会“自动”帮你选择最佳类别数,而是已经预置了一个默认的类别8。如果你不去设置,它会默认分为8个类别。既然是通过MiniBatch进行抽样,那到底Mini Batch是什么?Mini Batch是原始数据集中的子集,这个子集是在每次训练迭代时抽取抽取的样本。这个值默认是100个,可以通过batch_size进行设置。