1.4 第一个用Python实现的数据化运营分析实例-销售预测

“以促销费用预测商品销售量为业务场景,完整演示使用Python进行数据化运营分析的端到端流程。核心涵盖数据读取与预处理、散点图分布观察、基于sklearn构建线性回归模型、模型效果评估及最终预测输出7个关键步骤,并补充了Python代码的执行与调试方法,提供基础的数据分析实战指南。”
说明:本文节选自《Python 数据分析与数据化运营》中的“1.4 第一个用 Python 实现的数据化运营分析实例-销售预测”。
第一个用 Python 实现的数据化运营分析实例:销售预测
一、 案例概述
本节通过一个简单的案例,来介绍如何使用 Python 进行数据化运营分析。
案例场景:每个销售型公司都有一定的促销费用,促销费用可以带来销售量的显著提升。当给出一定的促销费用时,预计会带来多大的商品销售量?
在“附件-chapter1”中,data.txt 存储了建模所需的原始数据,get_started_example.py 是案例完整代码。以下是原始数据概况:
- 来源:生成的模拟数据,非真实数据
- 用途:用来做第一个销售预测案例
- 维度数量:1
- 记录数:100
- 字段变量:第一列是促销费用,第二列是商品销售量
- 数据类型:全部是浮点数值型
- 是否有缺失值:否
二、 案例过程
下面逐步解析整个分析和实践过程。
第一步:导入库
本案例中,我们会使用四个核心库:
re:正则表达式库,程序中通过该库来实现字符串分割。numpy:数组操作和处理库,程序中用来做格式转换和预处理。sklearn:算法模型库,程序中使用了线性回归方法linear_model。matplotlib:图形展示库,用来在建模前做多个字段关系分析。
代码如下:
python
💡 相关知识点:Python 导入库的两种方式
- 直接导入库:方法是
import [库名],例如import numpy。对于名称较长的库,通常使用as赋予别名以方便后续使用,例如import numpy as np。- 导入库中的指定函数:方法是
from [库名] import [函数名],例如from sklearn import linear_model。这种情况下也可以使用as命名别名,例如from matplotlib import pyplot as plt。
第二步:导入数据
本案例中的数据为 txt 文件,我们使用 Python 默认的读取文件方法。代码如下:
python
- 打开文件:
fn = open('data.txt', 'r')的作用是打开名为data.txt的文件,文件模式是只读(r),并创建一个名为fn的文件对象,后续所有关于该文件的操作都通过fn执行。- 路径说明:由于程序文件和数据文件处于同一个目录下,因此无需指定路径。也可以通过相对路径(如
'../data/data.txt')或绝对路径(如'd:/python_data/data/data.txt')来设置。注意绝对路径推荐使用正斜杠/,若使用 Windows 默认的反斜杠\,则需要写成转义字符形式'd:\\python_data\\data\\data.txt'。
- 路径说明:由于程序文件和数据文件处于同一个目录下,因此无需指定路径。也可以通过相对路径(如
- 读取数据:
all_data = fn.readlines()的意思是,从fn中读取所有的行记录,并保存到一个名为all_data的列表中。 - 关闭文件:
fn.close()的意思是关闭文件对象的占用。
⚠️ 提示:及时释放资源 不仅是文件对象,包括数据库游标、数据库连接等资源,在使用完成后都需要及时关闭,以减少对资源的无效占用,并防止其他模块操作该文件时因被占用而报错。
我们可以通过 all_data[0] 来查看该列表的第一个数据(Python 中的数据索引从 0 开始):
python
通过查看第一个数据,我们发现这是一个由数字、水平制表符(\t)和回车符(\n)组成的字符串。这为后续的数据预处理提供了思路。
💡 相关知识点:常用转义字符 在 Python 中,反斜杠
\作为转义字符存在。
\\:反斜杠符号\n:换行符\t:水平制表符\r:回车符
第三步:数据预处理
本阶段主要对读取的列表数据进行清洗转换,以满足数据分析展示和数据建模的需要。代码如下:
python
- 创建空列表:
x = []和y = []用来存放自变量和因变量数据。 - 循环读取:
for single_data in all_data通过循环每次从列表中读取一条数据。 - 数据分割:
re.split('\t|\n', single_data)分别使用\t和\n作为分割符,将字符串进行分割。 - 类型转换与追加:
x.append(float(tmp_data[0]))将分割后的第一个值转换为浮点型并追加到列表x中,y同理。 - 矩阵转换:
numpy.array(x).reshape([-1, 1])将列表转换为数组类型,并重塑为 N 行 1 列的矩阵。
💡 提示:关于
reshape在使用reshape做矩阵单行或单列的转换时,可直接使用reshape([-1, 1])转换为一列,或使用reshape([1, -1])转换为一行,而不必具体指定行或列的绝对数量。
第四步:数据分析
现在我们已经拥有了格式化的数据,为了确定使用哪种模型,先通过散点图来观察数据分布。代码如下:
python
代码执行后会弹出如图 1-9 所示的散点图。
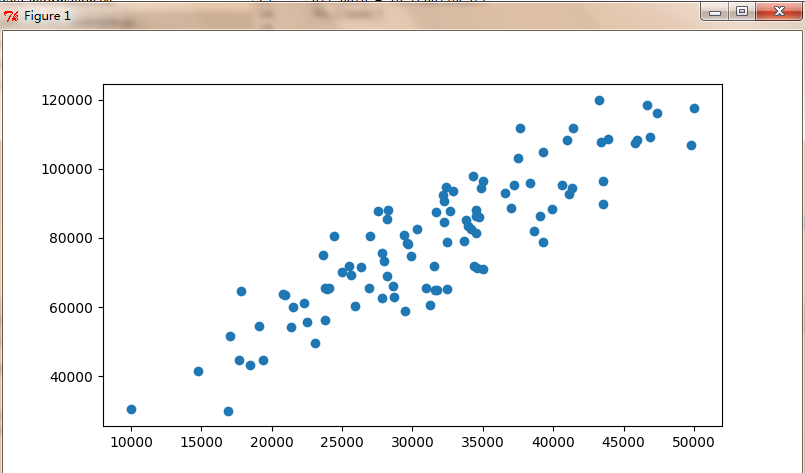
通过散点图发现,x 和 y 呈现明显的线性关系:当 x 增大时,y 增大;当 x 减小时,y 减小。初步判断可以选择线性回归进行模型拟合。
第五步:数据建模
建模阶段我们使用 sklearn 中的线性回归模块实现,代码如下:
python
- 创建模型:
model = linear_model.LinearRegression()创建一个线性回归模型对象。 - 模型训练:
model.fit(x, y)将x和y分别作为自变量和因变量输入模型进行训练。
第六步:模型评估
模型创建完成后,需要进行模型拟合的校验和评估,代码如下:
python
- 获取系数:
model.coef_获取模型的自变量系数。 - 获取截距:
model.intercept_获取模型的截距。 - 决定系数:
model.score(x, y)获取模型的决定系数 R 的平方。
通过上述步骤,我们可以获得线性回归方程:y = 2.09463661 * x + 13175.36904199。该回归方程的决定系数 R 的平方是 0.7876,整体拟合效果不错。
第七步:销售预测
我们已经拥有了一个可以预测的模型,现在给定促销费用(x)为 84610,进行销售预测:
python
- 创建常量:
new_x = 84610创建促销费用常量。 - 输入预测:
model.predict(new_x)将常量输入模型进行预测。 - 打印结果:
print(pre_y)输出销售预测值。
代码执行后,会输出 [[190402.57234225]],这就是预测的销售量。为了符合实际销量必须是整数的特点,后续可以使用 round(pre_y) 对数据做四舍五入,获得预测的整数销量。
三、 补充知识点:如何执行 Python 代码
对第一次接触 Python 的读者来讲,了解代码的执行方式是必要的。Python 代码既可以只执行特定代码行/段,也可以执行整个代码文件。
场景 1:执行特定代码行 / 段
这种方式通常是以调试的方式,逐行/模块运行代码,大多应用在单功能、模块的开发、调试和测试。
- 在 Python 命令行中执行:打开系统终端,输入
python进入命令行界面,逐行输入代码。 - 在 IPython 命令行中执行:打开系统终端,输入
ipython进入交互界面,逐行输入代码。 - 在 PyCharm 中执行(推荐):PyCharm 是本书推荐使用的 Python IDE。
PyCharm 调试指南:
-
第一次需要新建一个项目,
Location(位置)指向本书的“附件”根目录,点击Create(创建)。
图1-10 在PyCharm中新建Python项目 -
PyCharm 界面分为 4 部分:项目/结构区、代码区、调试区、智能提示区。
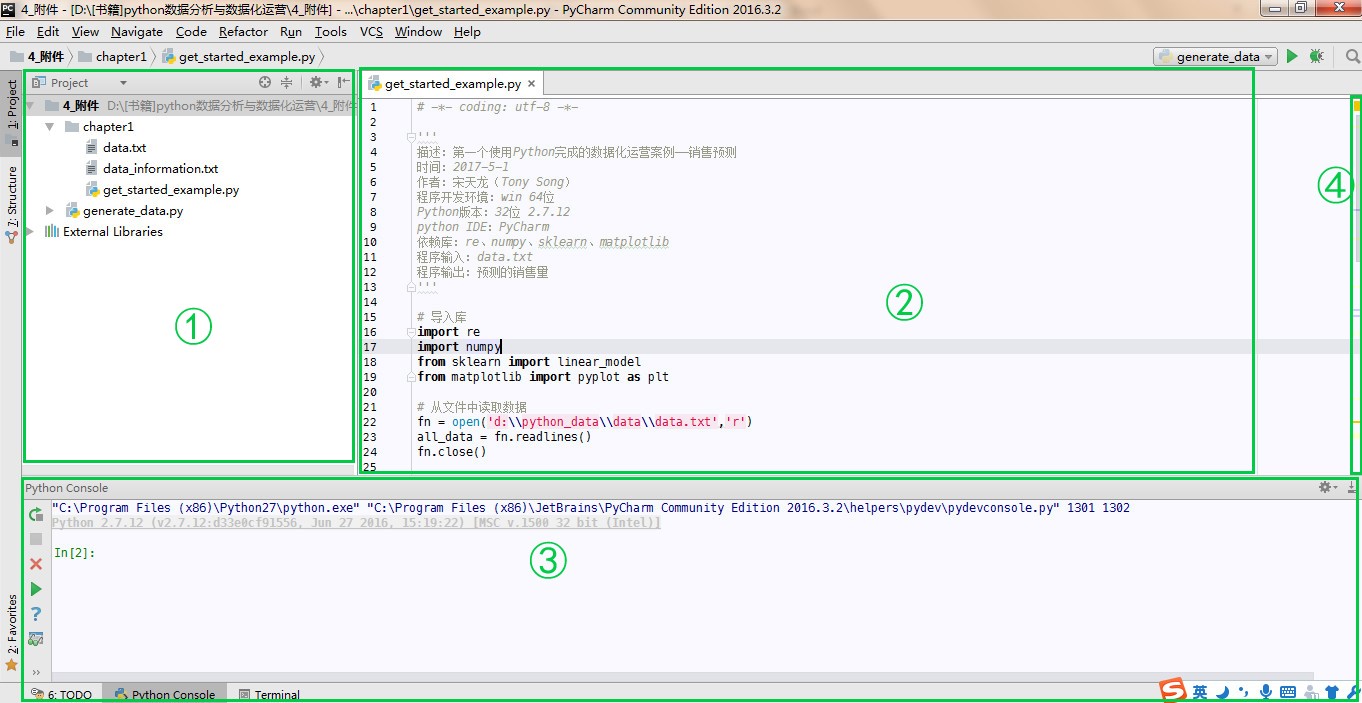
图1-11 PyCharm项目界面概览 -
在代码区,用鼠标选中要调试的程序,直接输入快捷组合键
ALT + Shift + E,即可在调试区看到代码执行状态。
图1-12程序调试执行结果
场景 2:执行整个代码文件
这种方式通常在单个功能或模块开发完成后,做整体测试或程序间调用时使用。
-
在系统终端命令行中执行:输入
python [python文件名称].py。执行结果将先显示图形文件,关闭图形后会继续运行显示预测结果。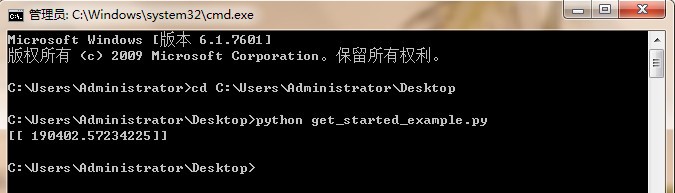
图1-13通过系统终端命令行中调用Python命令执行 -
在 IPython 命令行中执行:输入
ipython进入界面后,输入run [python文件名称].py。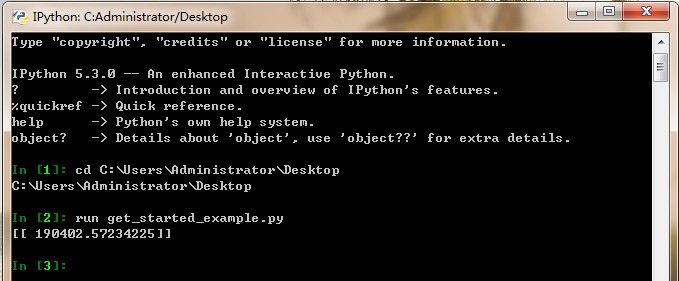
图1-14在IPython中执行Python文件 -
在 PyCharm 中执行:双击要执行的文件,输入快捷键
Alt + Shift + F10或通过顶部菜单栏Run -> Run执行,结果会在底部调试窗口显示。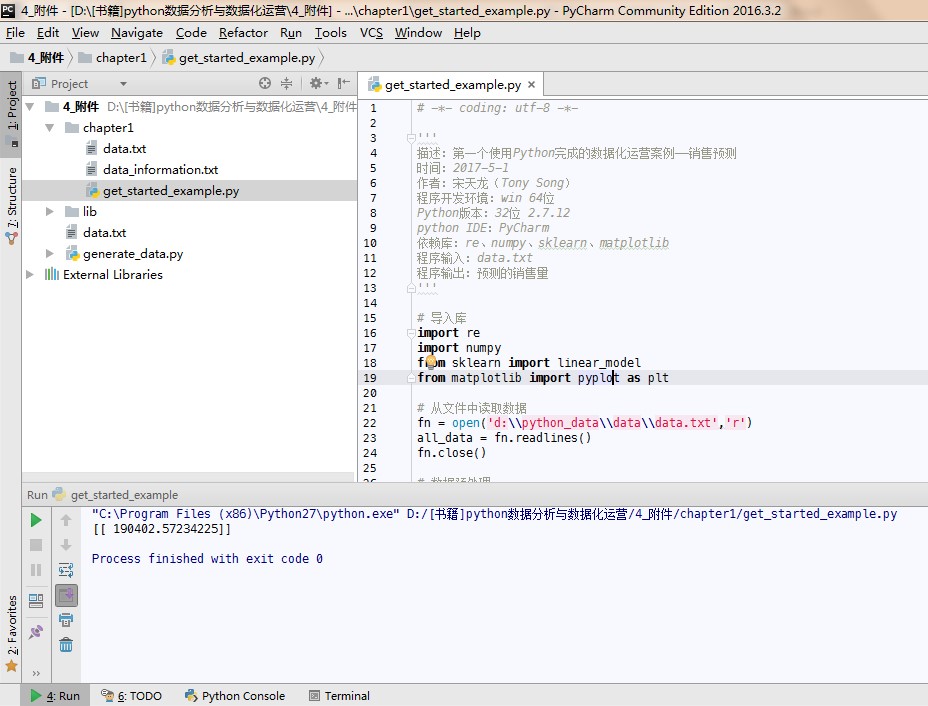
图1-15在PyCharm中执行Python文件
💡 为什么推荐 PyCharm? 在 PyCharm 中已经集成了 IPython 命令行(
Python Console)和系统终端窗口(Terminal)功能。在一个工具里可以实现不同的调试场景:安装第三方库、使用友好的交互提示、进行完整的项目资源管理与代码审查。
四、 案例小结
本案例看似篇幅很长,其实代码本身只用了 40 多行,完整演示了从输入数据到输出结果的整个过程。我们实现了 7 个关键步骤:导入库、获取数据、数据预处理、数据展示分析、数据建模、模型评估和销售预测。
其中,我们用到了以下基础知识:
- Python 文件的读取
- Python 基本操作:列表(新建、追加)、
for循环、变量赋值、字符串分割、数值转换 - Numpy 数组操作:列表转数组、重新设置数组形状
- 使用 Matplotlib 进行散点图展示
- 使用
sklearn进行线性回归的训练和预测 - 使用
print输出指定数据
这是本书的第一个完整案例,目的是引导读者快速进入使用 Python 进行数据化运营的场景。以下内容供读者作拓展思考之用:
- 通过散点图初步判断线性回归是比较好的拟合模型,是否有其他回归方法会得到更好的效果?(例如广义线性回归、SVR、CART 等)
- 通过图形法观察数据模型只适合用于二维数据,如果数据输入的维度超过 2 个或 2 个以上呢?
- 本案例中的数据量比较小,如果数据量比较大(假如有一千万条),如何进行数据归约?
- 回归模型除了案例中的评估指标外,还有哪些指标可以做效果评估?