案例-基于自动K值的KMeans广告效果聚类分析

“本文基于KMeans聚类算法对企业多维度广告渠道数据进行建模分析。通过平均轮廓系数确定最佳K值,将广告渠道精准划分为平庸、质量、精英及引流拉新四类,并利用雷达图直观对比各类别显著特征。分析结果为企业优化广告结构、制定差异化投放策略及提升整体营销ROI提供了科学的数据支持与业务洞察。”
企业广告渠道效果聚类分析案例
一、 案例背景与需求预设
某企业由于投放的广告渠道比较多,需要对其做广告效果分析,以实现有针对性的广告效果测量和优化工作。跟以应用为目的的案例不同的是,由于本案例是一个分析型案例,该过程的输出其实是不固定的,因此需要跟业务运营方具体沟通需求。
以下是在开展研究之前的基本预设条件:
- 广告渠道的范畴是什么?具体包括哪些渠道?
所有站外标记的广告类渠道(以
ad_开头)。 - 数据集时间选择哪个时间段? 最近 90 天的数据。
- 数据集选择哪些维度和指标? 渠道代号、日均 UV、平均注册率、平均搜索量、访问深度、平均停留时间、订单转化率、投放总时间、素材类型、广告类型、合作方式、广告尺寸、广告卖点。
- 专题分析要解决什么问题? 将广告分类并找出其重点特征,为接下来的业务讨论和数据分析提供支持。
明确了上述具体需求后,下面开始案例的主要工作部分。本节案例的输入源数据 ad_performance.txt 和源代码 chapter7_code2.py 位于“[附件-chapter7]下载源代码和数据”中,默认工作目录为“[附件-chapter7]”。程序的输出为不同聚类类别的详细信息数据以及雷达图。
二、 核心应用技术
本案例用到的主要技术包括:
- 数据预处理:数据标准化、字符串分类转整数型分类。
- 数据建模:KMeans 聚类算法。
- 数据展示:使用
matplotlib输出雷达图。
主要用到的库包括:sys、numpy、pandas、sklearn、matplotlib,其中 sklearn 是展示数据的核心。KMeans 聚类在“4.1 聚类分析”已经介绍过,本案例的重点有两个:
- 基于最优数据尺度确定最佳 K 值:最优佳的聚类类别划分,从数据特征上看是类内距离最小化的同时类间距离最大化。可以使用平均轮廓系数作为指标评估,通过枚举每个 K 计算平均轮廓系数并得到最优值。
- 雷达图的绘制:通过极坐标系的设置方式输出雷达图。
三、 案例数据概况
案例数据来自某企业的营销部门数据,该数据基于营销数据、网站分析系统数据和运营系统数据总结而来。
数据基本概况:
- 维度数:除了渠道唯一标记之外,共 12 个维度。
- 数据记录数:889 条。
- 是否有 NA 值:有。
- 是否有异常值:有。
13 个字段的详细说明:
- 渠道代号:业务方统一命名规划的唯一渠道标志。
- 日均 UV:每天的平均独立访客,从一个渠道中带来的一个访客即使一天中到达多次都统计为 1 次。
- 平均注册率:日均注册的用户数量 / 平均每天的访问量。
- 平均搜索量:平均每个访问的搜索次数。
- 访问深度:总页面浏览量 / 平均每天的访问量。
- 平均停留时间:总停留时间 / 平均每天的访问量。
- 订单转化率:总订单数量 / 平均每天的访问量。
- 投放总时间:每个广告媒介在站外投放的天数。
- 素材类型:广告素材类型,包括 jpg、gif、swf、sp。
- 广告类型:广告投放类型,包括 banner、tips、横幅、通栏、暂停以及不确定(不知道到底是何种形式)。
- 合作方式:广告合作方式,包括 roi、cpc、cpm 和 cpd。
- 广告尺寸:每个广告投放的尺寸大小,包括 140*40、308*388、450*300、600*90、480*360、960*126、900*120、390*270。
- 广告卖点:广告素材上主要的卖点诉求信息,包括打折、满减、满赠、秒杀、直降、满返。
四、 案例实操过程
步骤 1:导入依赖库
python
本案例主要用到了以下库:
sys:系统库,用来将默认编码设置为 UTF-8,目的是处理中文。numpy:基本数据处理。pandas:数据读取、审查、异常值处理等。DictVectorizer:用来将字符串分类转换为整数型分类。MinMaxScaler:数据标准化库,用来将数据做标准化处理。KMeans:K 均值聚类算法模块。metrics:sklearn 效果评估模块。pyplot:用来做雷达图展示。
步骤 2:读取原始数据
使用 pandas 的 read_table 方法读取 txt 文件,分隔符为 TAB。
python
步骤 3:数据审查与校验
该步骤包括多个环节:查看前 2 条数据、查看数据类型分布、查看缺失值、查看数据描述性统计信息、相关性分析等。
1. 查看前 2 条数据
python
从返回结果看,原始数据能正常识别且没有异常信息:
code
2. 查看数据类型分布
使用 dtypes 方法查看数据类型分布,通过 pd.DataFrame 将其结果转换为数据框,然后通过 .T 做转置。
python
各个字段类型都能被正确识别:
code
3. 查看缺失值
使用 isnull().sum() 查看所有字段中具有缺失值数据的统计量。
python
从结果中发现,在“平均停留时间”字段中有 2 个缺失值:
code
4. 查看数据描述性统计信息
使用 describe() 查看数据描述性统计信息,并使用 round(2) 保留 2 位小数。
python
描述性统计结果反映了 3 个信息点:
- 日均 UV 波动极大:说明不同渠道间的特征差异非常明显。
- 平均停留时间缺失:有效数据(非空数据)只有 887,比其他数据少 2 条,印证了缺失值统计结果。
- 部分指标看似异常:平均注册率、平均搜索量、订单转化率的多个统计量(如最小值、25% 分位数等)都为 0,看似数据不太正常。
以上三类异常点,经过跟业务方的沟通以及再次数据验证,结论如下:
- 日均 UV 的差异性:由于广告的流量型特征明显,很多广告的流量爆发明显,渠道间确实带有非常大的差异性。这些差异性应该保留,不能作为异常值处理。
- 平均停留时间的缺失值:由于统计缺失导致数据丢失,可以使用均值法做填充。
- 统计量为 0 的问题:这是由于在打印输出过程中仅保留了 2 位小数,而这几个统计量的数据本身就非常小,将其通过
round(3)保留 3 位小数后就能正常显示。
5. 相关性分析
python
通过相关性结果分析,12 个特征中平均停留时间和访问深度的相关系数为 0.72,这两个指标具有较高的相关性,但特征也不是非常明显;其他特征之间的相关性关系都不突出。
步骤 4:数据预处理
本步骤主要涉及到缺失值替换、字符串分类转换为整数分类、数据标准化、数据合并等操作。
Part 1:缺失值替换
使用 fillna 方法将“平均停留时间”中的缺失值替换为均值。
python
Part 2:字符串分类转整数分类 主要区别在于这里由于没有“预测”环节,因此无需区分训练阶段和预测阶段。
首先,定义要转换的数据并建立空列表:
python
其次,使用 for 循环获得所有列的唯一值列表,存入 unique_list:
python
接着,使用 for 循环将每条记录的具体值跟其在唯一值列表中的索引做映射:
python
最后,使用 DictVectorizer 将字符串转换为整数:
python
注:设置 sparse=False 指定转换后的数据集是一个数组,否则默认会是压缩后的稀疏矩阵,后续很多步骤和模型不支持直接基于稀疏矩阵建模。
Part 3:数据标准化 由于不同字段间存在数值的量纲差异(例如日均 UV 有几万的量级,而转化率的范围却是 0-1 之间),因此需要做数据标准化,这里使用的是 Min-Max 标准化方法。
python
Part 4:合并所有输入维度
使用 numpy 的 hstack 方法,将处理后的数值型和字符串型结果合并,形成最终输入 X。
python
注意:这里的
X不包含渠道的唯一标志列,因为该列没有实际建模意义。
步骤 5:基于平均轮廓系数确定最佳 K 值
K 值的确定一直是 KMeans 算法的关键。由于 KMeans 是非监督式学习,没有绝对的“最佳”K 值。但从数据特征来讲,最佳 K 值对应的类别下应该是类内距离最小化并且类间距离最大化。
我们可以通过枚举法计算每个 K 下的平均轮廓系数值,然后选出平均轮廓系数最大下的 K 值。
注意:即使在数据上聚类特征最明显,也并不意味着聚类结果就是有效的。因为聚类结果用来分析使用,不同类别间需要具有明显的差异性特征,并且类别间的样本量需要大体分布均衡。而单纯依靠算法确定最佳 K 值时,并没有考虑到这些“业务性”因素。
python
返回数据如下:
code
就经验看,如果平均轮廓得分值小于 0,意味着聚类效果不佳;如果在 0 到 0.5 之间,说明聚类效果一般;如果大于 0.5,则说明聚类效果比较好。本案例在 K=4 时,得分为 0.5697,说明效果较好。
步骤 6:聚类结果特征分析
Part 1:将原始数据与聚类标签整合
python
注:这里使用了经过缺失值填充后的 data_fillna 数组做合并,而不是标准化的 X,目的是为了在分析时能够再现不同特征下原始值的特征,便于业务理解。
Part 2:计算每个聚类类别下的样本量和样本占比
python
Part 3:计算各个聚类类别内部最显著特征值
python
Part 4:输出完整的类别特征信息
python
打印输出如下结果:
code
步骤 7:各类别显著数值特征雷达图对比
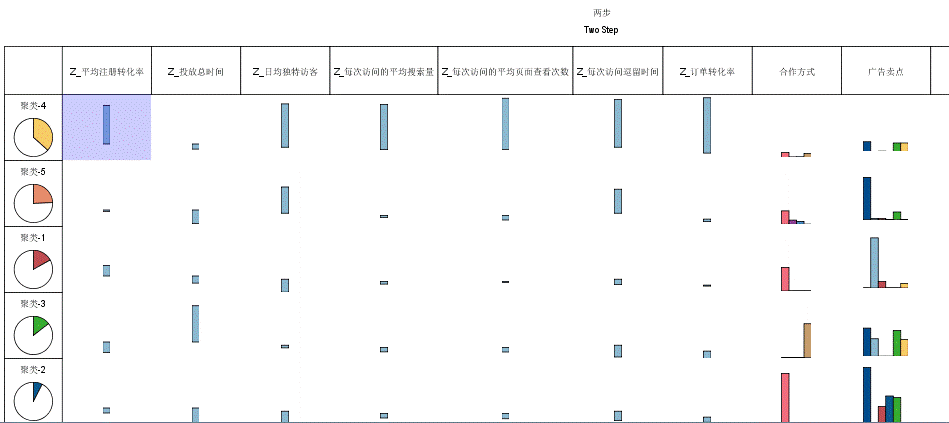
从上面的各类别特征中可能很难直观发现不同类别的显著性特征,这里通过雷达图的形式对各个聚类类别的数值型特征做对比展示。
1. 各类别数据预处理 由于不同特征的数据量级差异很大,需要先对其做标准化处理。
python
2. 画布基本设置
python
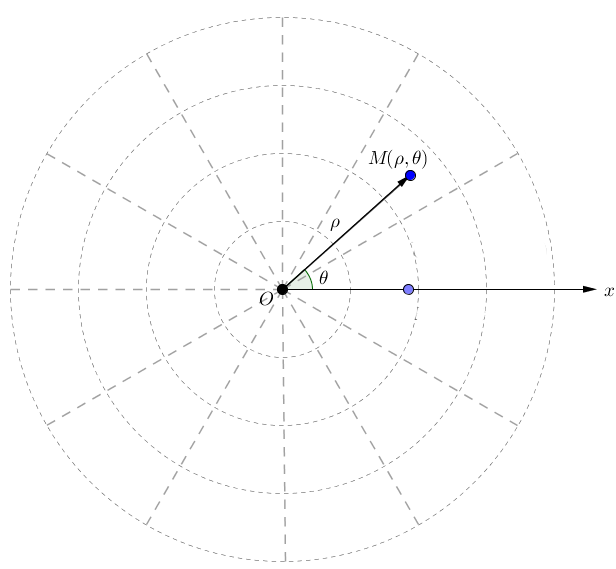
相关知识点:极坐标系 极坐标系是指在平面内由极点、极轴和极径组成的坐标系。空间中任意一个点,都可以通过
(ρ,θ)的有序对的形式表示。极坐标系是一个二维坐标系,与平面直角坐标系(笛卡尔坐标系)可以相互转换:x = ρcosθ,y = ρsinθ。python雷达图
3. 画雷达图
python
4. 设置图像显示格式
python
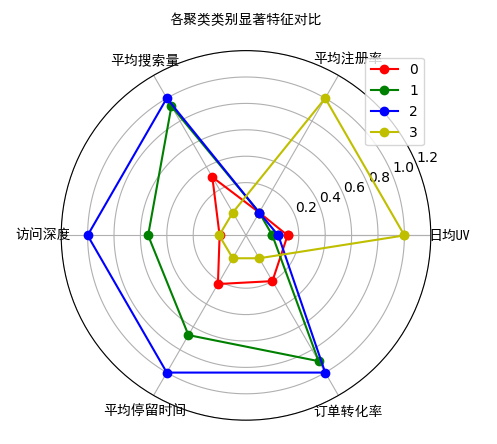
最终显示图像如下:
五、 数据结论与业务洞察
初步特征分析
从案例结果来看,所有的渠道被分为 4 个类别,每个类别的样本量分别为 411、297、27、154,对应的占比分别为 46%、33%、3%、17%。第三个类别样本量较少。
结合雷达图,可以清晰地看到不同类别广告媒体的特征倾向:
- 聚类 1(索引值为 0):各方面的特征都不明显,效果比较平庸,没有明显的优势或短板。但这些“中庸”的广告媒体却构成了整个广告的主体(占比 46%)。
- 聚类 2(索引值为 1):这类广告媒体在访问深度、平均停留时间、订单转化率以及平均搜索量等流量质量的特征上表现较好。除了注册转化率较低外,各方面比较均衡。且规模较大(占比 33%),是一类综合效果较好的媒体。
- 聚类 3(索引值为 2):跟聚类 2 非常类似,并且相对聚类 2 的典型特征表现更好。但综合其只有 3% 的媒体数量,属于少量的**“精英”类渠道**。
- 聚类 4(索引值为 3):跟其他几类渠道有个明显的特征区隔,其日均 UV 和平均注册率非常突出,证明这是一类**“引流”+“拉新”**的渠道;而其他的流量质量方面的表现却比较差。
深入业务剖析
综合初步分析的结果,再结合输出各渠道详细数据:
- 聚类 1 的广告渠道各方面表现均比较一般,因此需要业务部门重点考虑其投放的实际价值。
- 聚类 2 的广告渠道短板是日均 UV 和平均注册率,无法为企业带来大量的流量以及新用户。这类广告的特质适合用户转化,尤其是有关订单转化的提升。
- 聚类 3 的广告渠道跟聚类 2 的特质非常类似,也适合做订单转化的提升,并且由于其实际效果更好,因此效果会更加明显。
- 聚类 4 的广告渠道更加符合广告本身“广而告之”的基础诉求,因此适合在大规模的广告宣传和引流时使用,尤其对于新用户的注册转化上的效果非常明显,适合“拉新”使用。
六、 业务应用与部署策略
对于以上四类广告媒体,需要针对其不同的特征做针对性的运营应用:
- 针对聚类 1:在资金不足或优化广告结构时,重点考虑其取舍问题。
- 针对聚类 2 和聚类 3:优化应用的方向有两个:
- 增加注册转化效果的优化效应:重点从人群匹配、注册引导、注册激励等方面加强运营。打折、直降等优惠宣传点可以重点突出,广告素材本身以较大中等广告为主(例如 900*120)。
- 发挥整体广告效果的支撑价值:考虑到其流量规模的局限性,这类渠道更加适合在广告结构中作为一类具有流量质量支撑价值的角色,用来提升全局广告的订单质量效果。尤其是聚类 3,应该优先考虑投放组合。
- 针对聚类 4:可以作为在每次大型促销活动时做引流的骨干。对于这类媒体的单位流量成本需要重点关注,实际投放过程中可以满减为促销点、通过较大尺寸(如 308*338)的广告类型做引导流量点击。
提示:广告流量数量和质量是广告效果的“两条腿”。虽然大多数情况下广告更侧重于流量数量,但如果能够兼顾质量则可以锦上添花。对于广告结构中两类不同倾向的媒体,具体如何组织和结构调整,更多要看营销中心自身的核心目标定位。对于效果不好的媒体(如聚类 1),也不一定就要立刻切掉,这里面可能涉及到多方的利益关联问题。
聚类作为数据探索的初步阶段,还可以为后期的深入分析提供方向:
- 通过分类方法基于不同的类别划分,找到各自类别内的显著特征,这些特征会成为进一步落地动作确认的基础。
- 结合特定的广告运营目标并将其作为目标变量,通过分类方法找到各个广告渠道对于目标转化与否的重要性影响程度(如平均注册率、订单转化率等)。
- 结合不同类别的订单详细信息,提取购买的商品数据,分析平均订单金额、购买频率、商品购买数量,以实现对不同类别渠道购买力、消费潜力的评估。
- 将广告成本与广告效果评估指标结合起来,通过回归方法预测不同成本下能够达成的广告效果,作为广告媒体策划的基础。
七、 案例避坑指南与引申思考
关键注意点
- 异常值的保留:异常值对于聚类效果的影响是显著的,但是广告类媒体的一个典型特征就是流量规模差异非常大。因此对于这类的异常值不能轻易去除,它属于业务上的“正常现象”。
- 描述性统计的分离:在做描述性统计时,一般情况下会将数值型和字符串型的字段分开做统计。如果放在一起,会导致很多字段为空,实际效果并不直观。
- 标准化方法的选择:在做聚类之前的数据标准化方法选择上,由于数据中涉及到异常值的存在,因此使用的是可以兼顾异常值的处理方法(Min-Max)。
- 中文字体显示:
matplolib中如果要显示中文,需要设置对应的中文字体名称(如SimHei),否则无法正常显示。
引申思考与优化方向
本案例中通过平均轮廓系数的方法得到的最佳 K 值,不一定在业务上具有明显的解读和应用价值。如果最佳 K 值的解读无效怎么办?有两种思路:
- 扩大 K 值范围:例如将 K 的范围调整为
[2, 12],然后再次运算看更大范围内得到的 K 值是否更加有效,并且能符合业务解读和应用需求。 - 选择“次优” K 值:得到平均轮廓系数“次要好”(而不是最好)的 K 值,再对其结果做分析。
对于不同类别的典型特征的对比,除了使用雷达图直观地显示外,还可以使用多个柱形图的形式,将每个类别对应特征的值做柱形图统计,这也是一个非常直观的对比方法。具体参考下图: