二次判别分析Quadratic Discriminant Analysis(QDA)

“二次判别分析(QDA)是适用于不同分类样本协方差矩阵存在差异时的判别算法。协方差与协方差矩阵用于量化多维变量间的变化趋势,经标准化处理后即为相关系数。在Python机器学习库中,QDA算法仅支持分类预测,不具备降维功能。”
深入理解二次判别分析(QDA)与协方差矩阵
LDA 与 QDA 的核心差异
与线性判别分析(LDA)类似,**二次判别分析(QDA)**是另外一种线性判别分析算法,二者拥有类似的算法特征。它们的区别仅在于:
- 当不同分类样本的协方差矩阵相同时,使用线性判别分析(LDA);
- 当不同分类样本的协方差矩阵不同时,则应该使用二次判别分析(QDA)。
为了清楚地了解 LDA 和 QDA 的应用差异,下图显示了在固定协方差矩阵以及不同协方差矩阵下 LDA 和 QDA 的表现差异:
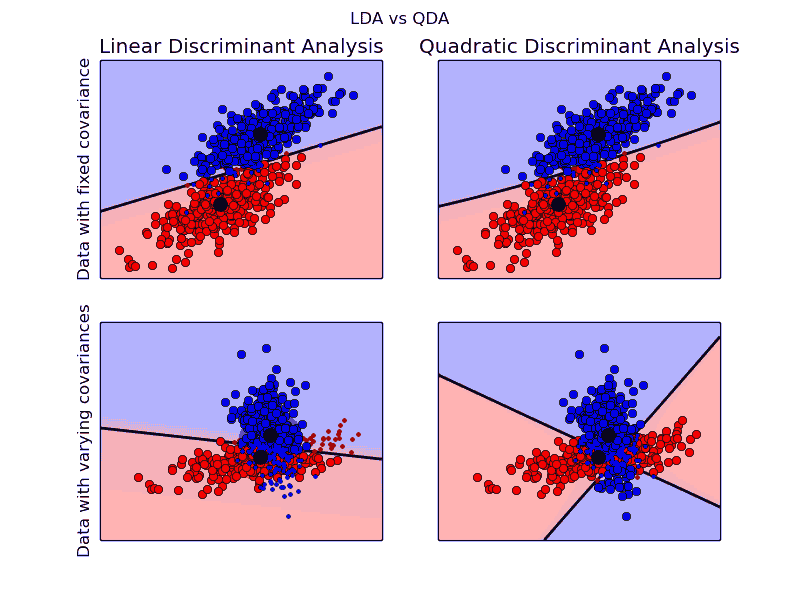
由图中可以看出,在固定协方差矩阵下,LDA 和 QDA 是没有分类结果差异的(上面两张图);但在不同的协方差矩阵下,LDA 和 QDA 的分类边界明显存在差异,而且 LDA 已经不能准确地划分数据(下面两张图)。
什么是协方差与协方差矩阵?
在统计学中,有几个描述样本分布的基本指标,例如均值、方差、标准差、峰度、偏度、最大值、最小值、极值等,这些描述的都是单一维度的特征。
如果一个样本存在多个维度,除了可以单独描述每个维度的分布规律外,如何描述不同维度间的关系?
协方差:描述维度间的关系
协方差就是用来描述维度间关系的一个指标。它的定义为:任意两个随机变量 X 和 Y 的协方差,记为 Cov(X,Y)。
它反映的是任意两个随机变量(或者是任意两个维度)间的关系:
- 当 X 取值不断增大时,Y 也不断增大,此时
Cov(X,Y) > 0 - 当 X 取值不断减小时,Y 也不断减小,此时
Cov(X,Y) > 0 - 当 X 取值不断增大时,Y 也不断减小,此时
Cov(X,Y) < 0 - 当 X 取值不断减小时,Y 也不断增大,此时
Cov(X,Y) < 0
总结 X 和 Y 之间的规律就是:当两个随机变量倾向于沿着相同趋势变化时为正协方差,反之则为负协方差。
相关系数:标准化的协方差
但我们知道,不同维度间可能由于值本身存在量级的差异而导致结果的偏差。例如,订单金额的单位可能是万元区间,而用户等级可能只是 10 以内的数字分布。
为了消除这个差异性,需要对协方差进行标准化,而标准化后的指标即相关系数(通常用 P 表示),其矩阵被称为相关性矩阵。
相关系数 P 的基本意义如下:
- 当
P > 0时,X 和 Y 呈正相关 - 当
P < 0时,X 和 Y 呈负相关
那么,当 P = 0 呢?难道意味着不相关?——当 P = 0 时,意味着 X 和 Y 不存在线性相关关系,但可能存在其他相关关系。
协方差矩阵:多维关系的矩阵化
注意:假设我们现在有 3 个维度,协方差只能显示任意 2 个维度的关系,如何把这 3 个维度同时显示出来?——这时,就要用到矩阵,即协方差矩阵。
协方差与相关系数实例解析
下面举例说明协方差和相关系数。现在有一个观测数据集,其中包含三个维度(年龄、等级和购买金额),样本量为 5,现在要对其求协方差和相关系数。
| 年龄 | 等级 | 购买金额 |
|---|---|---|
| 41 | 3 | 8,084 |
| 27 | 1 | 1,983 |
| 40 | 1 | 100 |
| 41 | 1 | 221 |
| 24 | 2 | 7,816 |
我们可以直接使用 SPSS 进行求解,得到以下结果:
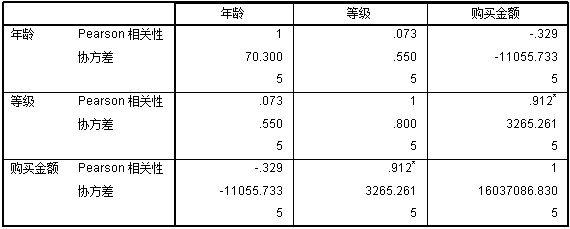
结果反映出,年龄和等级之间的协方差是 0.550,相关系数为 0.073;年龄和购买金额之间的协方差是 -11055.77,相关系数为 -0.329。同样的,我们也可以直接读出其他任意维度和其他 2 个维度的协方差以及相关系数。
互动问题:如果 A 和 B 的相关系数 P1 为 0.5,A 和 C 的相关系数 P2 为 -0.6,哪个相关性更高?欢迎大家留言讨论。
Python 实现二次判别分析(QDA)
回归本文的主体 QDA,以下是使用 Python 的 scikit-learn 库进行二次判别分析的代码示例:
python
其运行结果如下:
code
QDA 可配置的参数包括:
python
总结
Python 机器学习库中的 QDA 不具有 LDA 和 PCA 的降维功能,只能用来做分类预测。对于协方差的求解,则很容易使用 NumPy 中的 cov 函数进行计算。