神经网络模型Neural network models

“神经网络模型通过模拟人类大脑神经元的生物学机制,实现数据的自我学习与演化。其核心在于将神经元信号处理过程抽象为加权求和与激发函数。常见的网络模型包括BP、Hopfield和ART等。结合Python与RBM算法的非监督特征提取实战表明,该模型能有效提升预测准确率,是未来智能控制与数字智能领域的核心方法。”
深入浅出神经网络模型:从生物学原理到机器学习实践
神经网络模型是模拟人类神经网络工作原理进行自我学习和演化的一种数据工作方法。神经网络在系统辨识、模式识别、智能控制等领域应用广泛,尤其在智能控制中被视为解决自动控制中控制器适应能力这个难题的关键钥匙之一。
神经网络理论是巨量信息并行处理和大规模平行计算的基础,是高度非线性动力学系统,又是自适应组织系统,可用来描述认知、决策及控制的智能行为。它的中心问题是智能的认知和模拟,更重要的是它具有“认知”、“意识”和“感情”等高级大脑功能。它再一次拓展了计算概念的内涵,使神经计算、进化计算成为新的学科,神经网络的软件模拟得到了广泛的应用。
神经网络的起源:人类大脑的工作机制
既然神经网络模型是模拟人类神经网络的工作原理,那么首先来了解下人类的神经网络(也就是大脑)是如何工作的。人类的大脑从外到内可以简单分为两层:灰色的外层和白色的内层。
大脑的物理结构:灰质与白质
- 灰质(灰色外层):正常工作下的大脑(或者叫“活体”)其实是粉红色的,只是我们看到的大脑一般都是经过福尔马林固定的大脑,因此呈现灰色。灰色层只有几毫米厚,其中紧密地压缩着几十亿个被称作 Neuron(神经细胞、神经元)的微小细胞。
- 白质(白色内层):在皮层灰质的下面,占据了皮层的大部分空间,是由神经细胞相互之间的无数连接线组成。
皮层像核桃一样起皱,这可以把一个很大的表面区域塞进到一个较小的空间里。这与光滑的皮层相比能容纳更多的神经细胞。人的大脑大约含有 10 G(即 100 亿)个这样的微小处理单元,而一只蚂蚁的大脑大约也有 250,000 个。
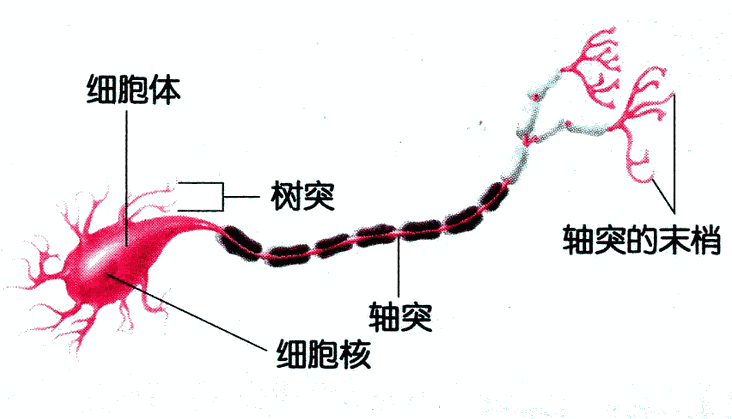
上图就是其中一个神经网络细胞或者叫神经元,这是我们用来做神经网络模型的关键,它的作用相当于电脑内的 CPU,只不过一个人会有 100 亿个 CPU 在同时工作。
神经元的微观构造与工作流程
从图中可以看出,一个神经网络细胞由树突、细胞体、轴突和轴突末梢组成:
- 树突与树突末梢(接收信号):和其他神经细胞的树突相连接,用来接收输入的信号,这些信号来源于其他神经细胞。每个神经细胞通过它的树突和大约 10,000 个其他的神经细胞相连。这就使得你的头脑中所有神经细胞之间连接总计可能有 100,000,000,000,000 个。
- 细胞体(处理信号):用来处理接收到的所有信号并最终形成处理结果。利用电-化学过程交换信号,当收到来自于树突的信号后,通过某种机制,将不同的信号进行处理(例如可能是加权或更复杂的算法,目前还不得而知),最终得出该信号的处理结果是兴奋还是不兴奋。尽管每一个神经细胞仅仅工作于大约 100 Hz 的频率,但由于数量巨大且并行工作,可以处理极其复杂的数据量和数据信号,且具有一定的自我学习、演进、修复等能力。
- 轴突和轴突末梢(输出信号):将细胞体处理的结果反馈给其他神经细胞。
因此,每个神经细胞的工作过程是:当从其他神经细胞接收到信号后,经过自身的综合处理,把得到的结果传递给其他神经细胞。整个人大脑中由于存在数以亿计的神经细胞,而这些细胞又可以并行工作,因此可以在非常短时间内完成外部信号的处理并将处理结果反馈给人体机能组织,然后做出信息反馈。
弄清楚人类大脑的工作机制之后,基于此的人工神经网络基本思想就比较明确了:
- 首先,神经网络中需要有接收信号的主体,类似于树突和树突末梢。
- 其次,需要有一个类似于细胞体的结构来综合处理接收到的信号。
- 最后,通过一个机制将处理完成的信号发送出去,类似于轴突的工作。
从生物到人工:单个人工神经元的数学抽象
单个人工神经元到底是什么样子?简单来讲可以想象成如下图的过程:
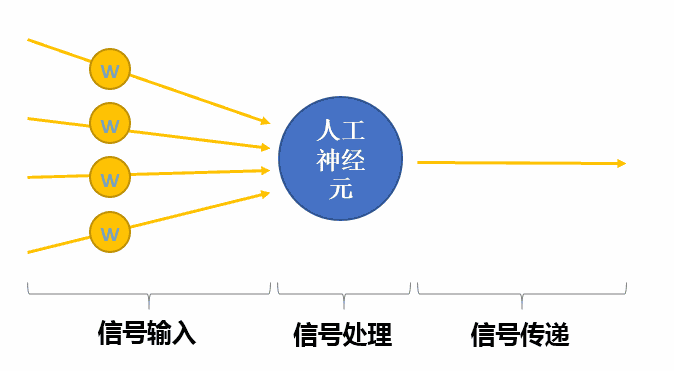
信号经过外部输入到“人工神经元”进行处理,然后将处理结果传递给其他人工神经元。但实际情况肯定要比我们这样“简单”构造的情况复杂得多。
信号的加权求和
可能不是所有接收到的不同信号来源的“强度”都是相同的,因此每个来源都会有一个权重 w。假设一个神经元有 n 个信号来源,那么来源的信号的求和过程就会变成每个信号的值乘权重,用以下表达式来表示输入信号:
x1w1 + x2w2 + x3w3 + ... + xnwn
进行简化后可以写成:
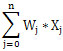
在模拟信号输入和传递的过程中,我们已经假设结果包括兴奋和不兴奋两类,那么我们可以用 1 和 0 表示(1 代表兴奋,0 代表不兴奋)。因此,我们得到 x 取值范围是一个 0 和 1 的有限集合 [0, 1];在构造权重的过程中,不同的信号来源的强度既有大小之分,也有正负之别,因此我们可以都标准化转换到 [-1, 1] 之间,所以得到 w 的取值范围是 [-1, 1]。
激发函数(Activation Function)与阈值
在人工模拟的神经元阶段,通过上面的加权求和是一种简单的构造方式,但最终得出的结果会是一个浮点数或整数 sum。如何将 sum 转换成 1 或者 0?这里会假设有一个阈值:当高于这个阈值时结果为 1,当低于这个阈值时结果为 0(这个逻辑跟 SVM 类似,结果大于 0 那么输出为 1,结果小于 0 结果输出为 -1)。
每个神经元的计算逻辑搞清楚了,下面举一个例子来说明如何在单个神经元里计算得分。假设一个神经元有 4 个信号输入分别为 X1、X2、X3、X4,其值分别为 1, 0, 0, 1;权重分别为 0.1, -0.6, 0.9, -0.4。那么单个神经元的初步计算得分为:
sum = 1 * 0.1 + 0 * (-0.6) + 0 * 0.9 + 1 * (-0.4) = -0.3
现在的问题就是如何确定一个阈值,使得 -0.3 被正确地识别为 0 或 1。这个过程会由一个函数来具体定义,叫做激发函数,最常见的有 S 型、阶跃型和线性型三种形式:
-
S 型(Sigmoid):名如其意,其形状就是一个 S 形曲线,可以使用反正切函数
arctan或指数函数exp来实现,如f(x) = arctan(x)/(pi/2),f(x) = 1/(1+e^-x)。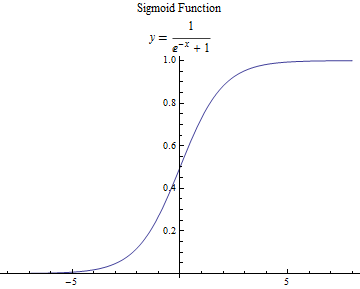
4933130441930973522 -
阶跃型:则是 Sigmoid 函数的不可导版本,当输入 X 在某个区间内时,输出 f(x) 取固定值。
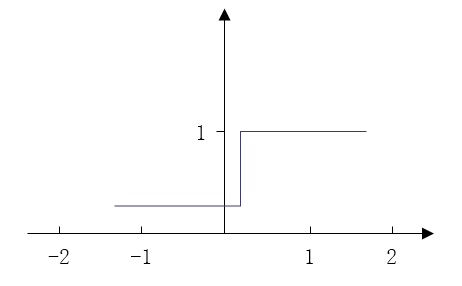
QQ截图20150507154721 -
线性型:则是一种简单的
f(x) = ax + b的形式。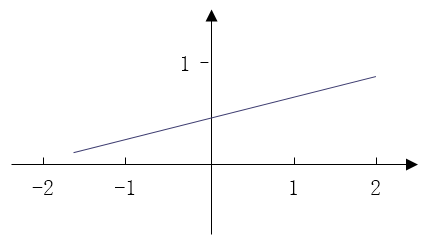
QQ截图20150507154449
实际上,关于每个输入信号的权重 w 以及阈值函数都需要经过大量的训练得以强壮。例如一个婴儿刚出生不知道哪个人是爸爸,哪个人是妈妈,但在经过大量的训练(婴儿训练及自我学习和成长)之后,便可以准确识别。
走向复杂:常见的人工神经网络模型
上面只是介绍了单个人工神经元的工作过程,实际上真正工作中需要很多甚至成千上万(人类就以亿计算)个神经元组成神经网络进行综合处理。
常见的神经网络模型包括 BP 神经网络模型、Hopfield 神经网络模型、ART 神经网络模型等。除此以外,还包括双向联想存储器(BAM)、Boltzmann 机(BM)、对流传播网络(CPN)、Madaline 算、认知机(Neocognitron)和感知器(Perceptron)等。
BP 神经网络模型(Back Propagation)
BP 神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。
- 核心特点:能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
- 拓扑结构:包括输入层(Input Layer)、隐层(Hidden Layer)和输出层(Output Layer)。
- 优缺点:属于监督式学习。短处是训练时间较长,且易陷于局部极小。
Hopfield 神经网络模型
Hopfield 神经网络是一种递归神经网络,是一种结合存储系统和二元系统的神经网络。
- 核心特点:提供了模拟人类记忆的模型。它保证了向局部极小的收敛。
- 优缺点:属于监督式学习。短处为计算代价较高,需要对称连接,且可能发生收敛到错误的局部极小值(Local Minimum)而非全局极小(Global Minimum)的情况。
ART 神经网络模型(自适应谐振理论模型)
ART 是一个根据可选参数对输入数据进行粗略分类的网络。
- 核心特点:ART-1 用于二值输入,而 ART-2 用于连续值输入。属于非监督式学习。
- 优缺点:不足之处在于过分敏感,输入有小的变化时,输出变化很大。
机器学习实战:基于 RBM 的非监督特征提取
在下面的案例中,我们使用 Python 的机器学习库 SKlearn 中的 Restricted Boltzmann machines (RBM) 算法来进行非监督式学习,目的是提取图像识别中的关键特征,常用于机器学习或数据挖掘前的特征提取或选择的工作。
python
输出的结果为:
code
通过结果我们看到,基于 Restricted Boltzmann machines (RBM) 提取后的 Logistic 预测准确率由 95% 提高到 97%,准确性有所提升。RBM 是一种基于概率论的非线性学习算法,属于非监督式学习的一种,它在非线性特征提取场景中的效果也不错。
RBM 可调节的参数如下:
python
尾巴
神经网络模型是一个跨学科的综合性领域,目前尚未清楚人类的大脑到底是如何工作的,而基于神经元和多种神经网络模型的挖掘也只是模拟或探索人类大脑工作进程中宝贵知识的冰山一角而已。
神经网络模型由于具有模拟人类思维和工作方法的潜力,因此未来可能会成为“数字智能”的代表工作方法之一,也会成为所有“智能”控制领域的核心。但时间还很久,路还很长。