新奇检测Novelty Detection

“文章系统梳理了数据挖掘中的异常检测技术,涵盖基于统计、距离、密度、偏移及时间序列的五大方法,并解析了新奇检测与离群点检测的差异。结合Python实践,详细演示了利用One-Class SVM无监督学习算法实现新奇检测的原理、代码构建与模型调优过程,并总结了其在欺诈识别、网络入侵等业务场景中的实际应用。”
聚焦异常值:数据挖掘中的异常检测方法与 Python 实践
大多数数据挖掘或数据工作中,异常值都会在数据的预处理过程中被认为是“噪音”而剔除,以避免其对总体数据评估和分析挖掘的影响。但某些情况下,如果数据工作的目标就是围绕异常值,那么这些异常值就会成为数据工作的焦点。
数据集中的异常数据通常被称为异常点、离群点或孤立点等,典型特征是这些数据的特征或规则与大多数数据不一致,呈现出“异常”的特点,而检测这些数据的方法被称为异常检测。
“噪音”的出现有多种原因,例如业务操作的影响(典型案例如网站广告费用增加 10 倍,导致流量激增)、数据采集问题(典型案例如数据缺失、不全、溢出、格式匹配等问题)、数据同步问题(异构数据库同步过程中的丢失、连接错误等导致的数据异常)。在对离群点进行挖掘分析之前,需要从中区分出真正的“离群数据”,而非“垃圾数据”。
常用的异常检测方法
常用的异常检测方法可分为以下几类:
基于统计的异常检测方法
该方法的基本步骤是对数据点进行建模,再以假定的模型(如泊松分布、正态分布等)根据点的分布来确定是否异常。这种方法首先需要对数据的分布有所了解,进而通过数据变异指标来发现异常数据。常用变异指标有极差、四分位数间距、均差、标准差、变异系数等。
- 局限性:基于统计的方法检测出来的异常点产生机制可能不唯一,而且它在很大程度上依赖于待挖掘的数据集是否满足某种概率分布模型。另外,模型的参数、离群点的数目等都非常重要,确定这些因素通常比较困难。因此,实际情况中算法的应用性和可移植性较差。
基于距离的异常检测方法
该方法包含并拓展了基于统计的思想,即使数据集不满足任何特定分布模型,它仍能有效地发现离群点;特别是当空间维数比较高时,算法的效率比基于密度的方法要高得多。
- 实现逻辑:首先给出记录数据点间的距离(如曼哈顿距离、欧氏距离等),对数据进行一定的预处理后,就可以根据距离的定义来检测异常值。例如,基于 K-Means 的聚类可以将离每个类中心点最远、或者不属于任何一个类的数据点提取出来从而发现异常值。
- 优势:不需要用户拥有任何领域知识且具有比较直观的意义,算法比较容易理解,因此在实际中应用得比较多。
基于密度的离群检测方法
这种方法一般建立在距离的基础上,其主要思想是将“数据点之间的距离”和“某一范围内数据数”这两个参数结合起来,从而得到**“密度”**的概念,然后根据密度判定记录是否为离群点。
例如 LOF(局部异常因子) 就是用于识别基于密度的局部异常值的算法。离群点被定义为相对于全局的局部离群点,这与传统异常点的定义不同,异常点不再是一个二值属性(实际上的定义类似于“有 98% 的可能性是一个异常点”)。它摈弃了以前所有的异常定义中非此即彼的绝对异常观念,更加符合现实生活中的应用;但其缺点是只对数值数据有效。
基于偏移的异常点检测方法
基于偏移的离群检测算法(Deviation-based Outlier Detection),主要是通过对测试数据集主要特征的检验来发现离群点。目前,基于偏移的检测算法大多停留在理论研究上,实际应用比较少。
基于时间序列的异常点监测方法
所谓时间序列,就是将某一指标在不同时间上的数值,按照时间先后顺序排序而成的数列。这种数列虽然由于受到各种偶然因素的影响而表现出某种随机性,不可能完全准确地用历史值来预测将来,但是前后时刻的数值或数据点的相关性往往呈现某种趋势性或周期性变化,这是时间序列挖掘的可行性之所在。
时间序列中没有具体描述被研究现象与其影响因素之间的关系,而是把各影响因素分别看作一种作用力,被研究对象的时间序列则看成合力。按作用特点和影响效果,将影响因素归为 4 类:
- 趋势变动(T)
- 季节变动(S)
- 循环变动(C)
- 随机变动(I)
这四种类项的变动叠加在一起,形成了实际观测到的时间序列,因而可以通过对这四种变动形式的考察来研究时间序列的变动。目前国际和国内对时间序列相似度的研究提出了许多种解决方法,主要包括:基于直接距离、傅立叶变换、ARMA 模型参数法、规范变换、时间弯曲模型、界标模型、神经网络、小波变换、规则推导等。
异常检测的两大分类
异常检测根据原始数据集的不同,可分为两类:
- 新奇检测(Novelty Detection):前提是已知训练数据集是“纯净”的,未被真正的“噪音”数据或真实的“离群点”污染。针对这些数据训练完成之后,再对新的数据进行预测以寻找异常数据。
- 离群点检测(Outlier Detection):训练数据集本身包含“离群点”数据。对这些数据训练完成之后,再在新的数据集中寻找异常数据。
Python 实践:基于 One-Class SVM 的新奇检测
本文重点探讨新奇检测,通过 Python 的 sklearn 库实现,应用算法为 One-Class SVM(一类支持向量机)。
算法原理
One-Class SVM 的基本原理是在给定的一组样本中,检测数据集的边界,以便于区分新的数据点是否属于该类。它是基于密度检测方法的一种,属于无监督学习算法。拟合过程由于不存在数据类标签,因此只需要输入一个特征矩阵 X 即可。
代码实现
python
结果分析与模型调优
运算结果如下:
code
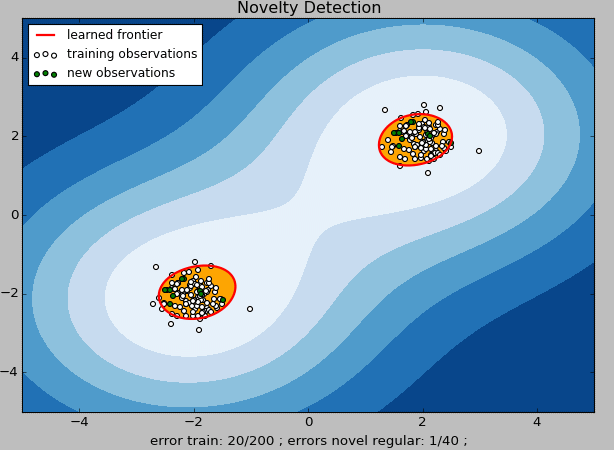
上图中,白色点表示训练数据,绿色点表示测试数据,黄色区域表示“正常数据”区域,红色线表示“正常数据”和“异常数据”的边界。
从模型的输出代码结果可以看到,其中值为 -1 的数据,以及从图中直观看到绿色标记点(新的观测点)中在红色线条之外的,即为**“新奇数据”**。这些数据就可以被单独拿出来做更进一步的分析,或触发相应的业务动作及流程。
在这个案例中,我们使用的 One-Class SVM 的拟合效果不是特别好。我们可以看到,对原始训练数据进行训练并采用相同的数据进行新奇检测后,错误的样本量达到 10%(图中 error train: 20/200 —— 这里我们已经假设原有的数据都是干净的,因此不应该存在异常数据的预测结果)。
模型中有很多参数需要不断调整和组合才能达到较高的数据预测准确性,模型的组合调优是算法的核心。可以结合模型中的支持向量值、决策函数中的支持向量系数、常量等进行调整。如果选择线性内核(kernel='linear'),还可以查看每个特征的权重值。
其中可调整的参数如下:
python
新奇检测的应用场景
新奇检测在实际业务中有着广泛的应用,主要场景包括:
- 客户异常识别
- 信用卡欺诈
- 贷款审批识别
- 药物变异识别
- 恶劣气象预测
- 网络入侵检测
- 流量作弊
总结
One-Class SVM 属于 SVM 的一种,可用于高维数据的异常检测,其底层基于 libsvm。One-Class SVM 提供了 linear、poly、rbf、sigmoid 和 precomputed 等内核可供使用,甚至支持自定义内核算法来调用。
One-Class SVM 本质上还是一种分类算法,但这种分类与传统的“分类”意义不同:One-Class SVM 的分类是将数据分为“正常数据”和“异常数据”(用 +1 和 -1 表示),而传统的分类是将正常数据按照不同的特征划分为几个不同的类别。