混合高斯模型Gaussian Mixture Model(GMM)

“混合高斯模型(GMM)通过组合多个单高斯分布来拟合复杂的连续概率密度分布。该模型利用最大期望(EM)算法进行参数评估,实现基于概率密度的软聚类。相比K-means,GMM更适合处理簇大小不同或存在相关性的复杂数据,广泛应用于数据分类、图像分割、语音特征提取及密度检测等机器学习场景。”
深入理解混合高斯模型(GMM):原理、算法与实战
**混合高斯模型(Gaussian Mixture Model,简称 GMM)**是用高斯概率密度函数(正态分布曲线)精确地量化事物,将一个事物分解为若干的基于高斯概率密度函数形成的模型。
通俗点讲,无论观测数据集如何分布以及呈现何种规律,都可以通过多个单一高斯模型的混合进行拟合。
如下图是一个观测数据集,数据集明显分为两个聚集核心,我们通过两个单一的高斯模型混合成一个复杂模型来拟合数据。这就是一个混合高斯模型。
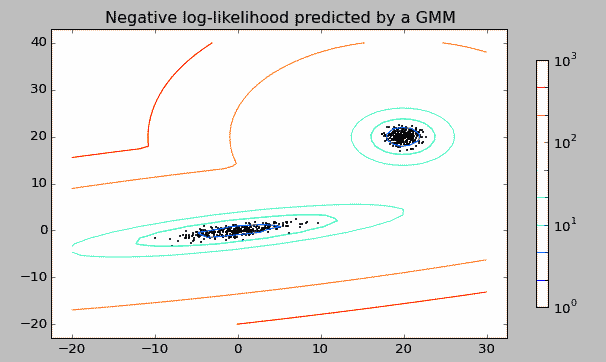
从单高斯模型(SMM)说起
既然混合高斯模型是由 n 个(或多个)单高斯模型组成,那么首先需要了解下单高斯模型(Single Mixture Model,简称 SMM)。
最常见的单高斯模型(或者叫单高斯分布)就是钟形曲线,只不过钟形曲线只是一维下的高斯分布。
高斯分布(Gaussian distribution)又叫正态分布(Normal distribution),是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。因其曲线呈钟形,因此人们又经常称之为钟形曲线。
如下图为标准正态分布图:
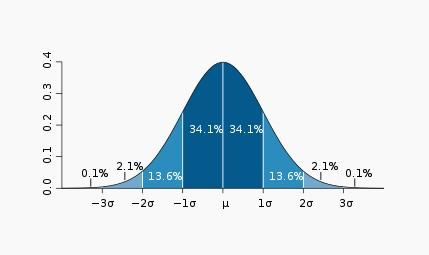
一维高斯分布
它的基本定义是:若随机变量 X 服从一个数学期望为 μ、方差为 σ^2 的高斯分布,则记为 N(μ, σ^2)。
- 数学期望
μ:指的是均值(算术平均值)。 - 标准差
σ:方差开平方后得到标准差。
高斯分布的概率密度函数为:
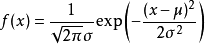
多维高斯分布
上述公式只是一维下的高斯分布模型,多维高斯分布模型下概率密度函数如下:
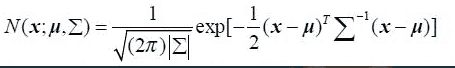
在上述公式中:
x是维度为d的列向量。u是模型期望(实际应用中通常用样本均值来代替)。Σ是模型方差(实际应用中通常用样本方差来代替)。
很容易判断一个样本 x 是否属于类别 C:因为每个类别都有自己的 u 和 Σ,把 x 代入公式中,当概率大于一定阈值时,我们就认为 x 属于 C 类。
单高斯模型的局限性
从几何形状上讲,单高斯分布模型在二维空间应该近似于椭圆(如本文最开始的图形),在三维空间上近似于椭球。
但单高斯分布模型的问题在于:在很多分类问题中,属于同一类别的样本点并不满足“椭圆”分布的特性。因此,就需要引入高斯混合模型来解决这个问题。
我们可以用不同的分布来随意地构造 XX Mixture Model(例如泊松混合模型等),但由于 GMM 的计算性能强、拟合程度高等因素导致其最为流行。另外,混合模型本身也可以变得非常复杂,通过增加 Model 的个数,改变权重的计算方法等,我们可以任意地逼近任何连续的概率密度分布。
混合高斯模型的数学定义
基于单高斯模型的混合高斯模型公式定义如下:

- 参数
K:需要事先确定好,就像 K-means 中的K一样。只要K足够大,这个模型就会变得足够复杂,就可以用来逼近任意连续的概率密度分布。 - 权值因子
πk:代表各个成分的权重。 - 成分(Component):其中的任意一个高斯分布
N(x; uk, Σk)叫作这个模型的一个 component。
GMM 是一种聚类算法,每个 component 就是一个聚类中心。
模型参数评估:EM 算法
既然已经了解模型的定义,如何确定这些参数值?GMM 通常使用**最大期望(Expectation Maximum,简称 EM)**进行参数评估。
EM 算法的基本迭代思路如下:
- 随机初始化一组参数
θ(0)。 - 根据后验概率
Pr(Y|X;θ)来更新Y的期望E(Y)。 - 用
E(Y)代替Y求出新的模型参数θ(1)。 - 如此循环迭代,直到
θ趋于稳定。
Python 实战:使用 GMM 进行分类
接下来使用 Python 的机器学习库 SKlearn 中的 GMM 算法演示实例——使用 GMM 来做分类。
python
运行结果如下:
code
在该函数中,可配置的核心参数如下:
python
GMM 的典型应用场景
混合高斯模型的应用场景非常广泛,主要包括:
- 数据集分类:如用户或会员分类。
- 图像分割与特征抽取:例如在视频中跟踪人物以及区分动作,识别汽车、建筑物等。
- 语音分割与特征抽取:例如从一堆杂乱的声音中提取某个人的声音,从音乐中提取背景音乐,从大自然中提取地震的声音等。
总结:GMM 与 K-means 的对比
GMM 与 K-means 聚类在底层逻辑上有相似之处,但也存在显著差异:
- 相似点:两者都使用迭代算法计算,并最终收敛到局部最优。
- 适用场景差异:当各类尺寸不同、聚类间有相关关系的时候,高斯混合模型(GMM)往往比 K-means 聚类更合适。
- 密度检测:GMM 是基于概率密度函数进行学习的,所以除了在聚类应用外,还经常应用于密度检测(Density Estimation)。
- 软硬分类:K-means 的结果是每个观测点一定被分类到某个数据集类别中(硬分类);而 GMM 给出的是被分类到不同数据集类别中的概率(又被称为软分类 Soft Assignment)。