聚类算法Affinity Propagation(AP)

“Affinity Propagation (AP) 聚类算法基于节点间消息传递(吸引度与归属度)计算实际数据点作为聚类中心。相比K-Means,AP算法无需预设聚类数量、对初始值和异常值不敏感,且误差平方和更低。但其时间复杂度较高,海量数据下耗时极长,因此更适合应用于少量数据的聚类分析场景。”
深入理解 Affinity Propagation (AP) 聚类算法
算法简介与核心思想
Affinity Propagation 聚类算法简称 AP,是一个在 2007 年发表在《Science》上的聚类算法。
AP 算法的基本思想是将全部样本看作网络的节点,然后通过网络中各条边的消息传递计算出各样本的聚类中心。聚类过程中,共有两种消息在各节点间传递,分别是吸引度 (Responsibility) 和归属度 (Availability)。AP 算法通过迭代过程不断更新每一个点的吸引度和归属度值,直到产生 $m$ 个高质量的 Exemplar(类似于质心),同时将其余的数据点分配到相应的聚类中。
核心概念与专业术语
在 AP 算法中有一些特殊名词:
- Exemplar:指的是聚类中心,相当于 K-Means 中的质心。
- Similarity:数据点 $i$ 和点 $j$ 的相似度记为 $s(i, j)$,是指点 $j$ 作为点 $i$ 的聚类中心的相似度。一般使用欧氏距离来计算,点与点的相似度值通常全部取为负值;因此,相似度值越大说明点与点的距离越近,便于后面的比较计算。
- Preference:数据点 $i$ 的参考度称为 $p(i)$ 或 $s(i,i)$,是指点 $i$ 作为聚类中心的参考度。一般取 $s$ 相似度值的中值。
- Responsibility:$r(i,k)$ 用来描述点 $k$ 适合作为数据点 $i$ 的聚类中心的程度(吸引度)。
- Availability:$a(i,k)$ 用来描述点 $i$ 选择点 $k$ 作为其聚类中心的适合程度(归属度)。
- Damping factor (阻尼系数):主要是起收敛作用的。
核心参数提示:在实际计算应用中,最重要的两个参数(也是需要手动指定)是 Preference 和 Damping factor。前者决定了聚类数量的多少,值越大聚类数量越多;后者控制算法的收敛效果。
AP 算法与 K-Means 的对比
AP 算法的独特优势
与经典的 K-Means 聚类算法相比,AP 聚类具有很多独特之处:
- 无需指定聚类“数量”参数:AP 聚类不需要指定 $K$(如经典的 K-Means)或者是其他描述聚类个数(如 SOM 中的网络结构和规模)的参数。这使得先验经验成为应用的非必需条件,大大增加了适用范围。
- 明确的质心(聚类中心点):样本中的所有数据点都可能成为 AP 算法中的质心(叫做 Examplar),而不是由多个数据点求平均而得到的虚拟聚类中心(如 K-Means)。
- 对距离矩阵的对称性没要求:AP 通过输入相似度矩阵来启动算法,因此允许数据呈非对称,数据适用范围非常大。
- 初始值不敏感:多次执行 AP 聚类算法,得到的结果是完全一样的,即不需要进行随机选取初值步骤(对比 K-Means 的随机初始值)。
- 误差平方和更低:若以误差平方和来衡量算法间的优劣,AP 聚类比其他方法的误差平方和都要低(无论 K-Center Clustering 重复多少次,都达不到 AP 那么低的误差平方和)。
AP 算法的局限性
AP 算法相对 K-Means 鲁棒性强且准确度较高,但没有任何一个算法是完美的,AP 聚类算法也不例外:
- 算法复杂度较高(耗时较长):AP 算法的时间复杂度为 $O(N^2 \log N)$,而 K-Means 只是 $O(N \cdot K)$。因此当 $N$ 比较大时($N > 3000$),AP 聚类算法往往需要算很久。尤其在海量数据下运行时,耗费的时间极长。
- 参数调节的变体:AP 聚类应用中需要手动指定 Preference 和 Damping factor,这其实是原有的聚类“数量”控制的变体。
Python 实战:基于 scikit-learn 的应用
以下使用 Python 的机器学习库 scikit-learn 应用 AP (Affinity Propagation) 算法进行案例演示。案例中,我们会先对 AP 算法和 K-Means 聚类算法的运行时间做下对比,分别选取 100、500、1000 样本量下进行两种算法的聚类时间对比;然后,使用 AP 算法做聚类分析。
AP 与 K-Means 运行时间对比
python
运算结果如下:
code
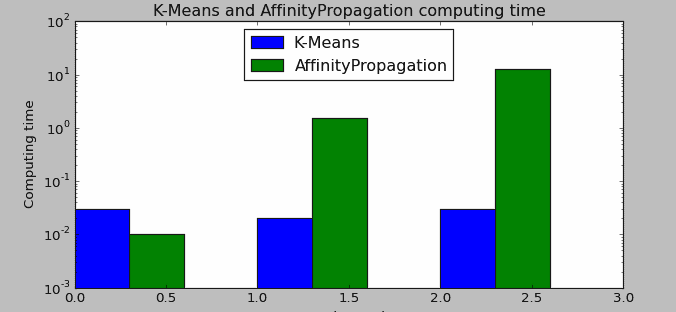
结果分析:图中为了更好的展示数据对比,已经对时间进行 log 处理,但可以从输出结果直接读取真实数据运算时间。由结果可以看到:当样本量为 100 时,AP 的速度要略快于 K-Means;当数据增加到 500 甚至 1000 时,AP 算法的运算时间要大大超过 K-Means 算法;甚至当试图运算更大的数据量(如 100,000)时,会直接因内存错误而被迫中止。
AP 聚类算法代码示例
python
运行结果:
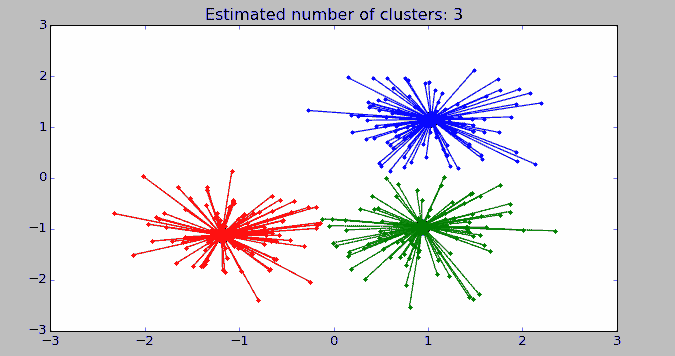
code
参数配置与应用场景
在 scikit-learn 中,AffinityPropagation 可配置的参数如下(重点是 damping 和 preference):
python
AP 算法的应用场景: 图像处理、文本分析、生物信息学、人脸识别、基因发现、搜索最优航线、码书设计以及实物图像识别等领域。
总结
综合来看,由于 AP 算法不适用均值做质心计算规则,因此对于离群点和异常值不敏感 ;同时其初始值不敏感 的特性也能保持模型的较好鲁棒性。
这两个突出特征使得它可以作为 K-Means 算法的一个有效补充。但在大数据量下的耗时过长,导致它的适用范围只能是少量数据;虽然通过调整 damping(收敛规则)可以在一定程度上提升运行速度(将 damping 值调小),但由于算法本身的局限性,这也只是杯水车薪。