聚类算法Mean Shift

“Mean Shift 是一种基于核密度估计的无参迭代算法,通过沿概率密度梯度方向寻找数据最密集区域。该算法收敛快、鲁棒性强,广泛应用于目标跟踪、图像分割与聚类等领域。在 Python 实战中,自动计算 bandwidth 参数易成为大数据集下的性能瓶颈,建议结合先验经验手动指定以保障实时计算效率。”
深入解析 Mean Shift 算法:原理、应用与 Python 实战
算法概述与核心原理
Mean Shift 算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,然后以此为新的起始点,继续移动,直到满足一定的结束条件。Mean Shift 算法是一种无参密度估计算法或称核密度估计算法。Mean Shift 是一个向量,它的方向指向当前点上概率密度梯度的方向。
所谓的核密度评估算法,指的是根据数据概率密度不断移动其均值质心(也就是算法的名称 Mean Shift 的含义),直到满足一定条件。
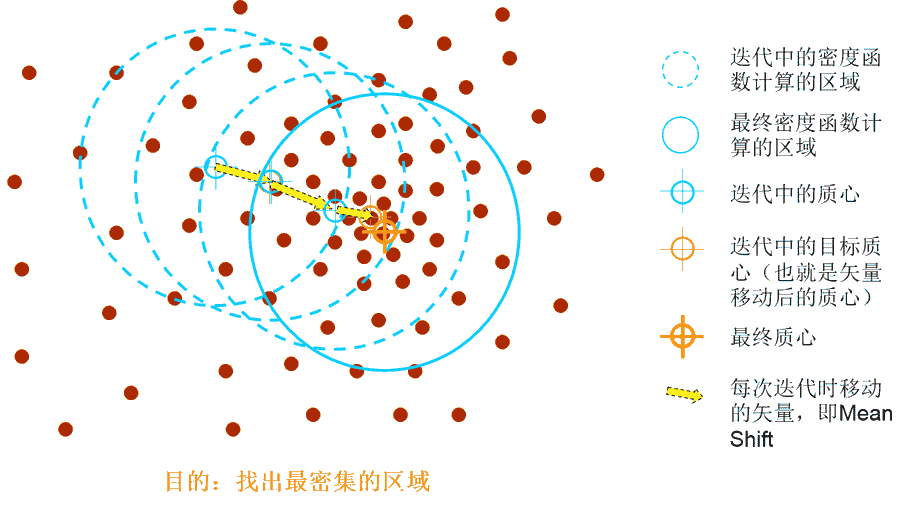
上图诠释了 Mean Shift 算法的基本工作原理。那么,如何找到数据概率密度最大的区域?
数据最密集的地方,对应于概率密度最大的地方。我们可以对概率密度求梯度,梯度的方向就是概率密度增加最大的方向,从而也就是数据最密集的方向。
在目标跟踪中的应用与优缺点
Mean Shift 算法最常用于目标跟踪。它通过计算候选目标与目标模板之间相似度的概率密度分布,然后利用概率密度梯度下降的方向来获取匹配搜索的最佳路径,加速运动目标的定位和降低搜索的时间,因此在目标实时跟踪领域有着很高的应用价值。
算法优点
- 由于采用了统计特征,因此对噪声有很强的鲁棒性;
- 由于是一个单参数算法,容易作为一个模块和别的算法集成;
- 采用核函数直方图建模,对边缘阻挡、目标的旋转、变形以及背景运动都不敏感;
- 算法构造了一个可以用 Mean Shift 算法进行寻优的相似度函数。由于 Mean Shift 本质上是最陡下降法,因此其寻优过程收敛速度快,使得该算法具有很好的实时性。
算法缺点
- 缺乏必要的模板更新;
- 跟踪过程中由于窗口宽度大小保持不变,当目标尺度有所变化时,跟踪就会失败;
- 当目标速度较快时,跟踪效果不好;
- 直方图特征在目标颜色特征描述方面略显匮乏,缺少空间信息。
Mean Shift 的主要应用领域
Mean Shift 算法在很多领域都有成功应用,例如图像平滑、图像分割、物体跟踪等,这些属于人工智能里面模式识别或计算机视觉的部分;另外也包括常规的聚类应用。
- 图像平滑:图像最大质量下的像素压缩;
- 图像分割:跟图像平滑类似的应用,但最终是将可以平滑的图像进行分离,以达到前后景或固定物理分割的目的;
- 目标跟踪:例如针对监控视频中某个人物的动态跟踪;
- 常规聚类:如用户聚类等。
基于 Python 的实战演示
下面基于 Python 的机器学习库 scikit-learn(SKlearn)中的 MeanShift 演示算法应用。
代码实现
python
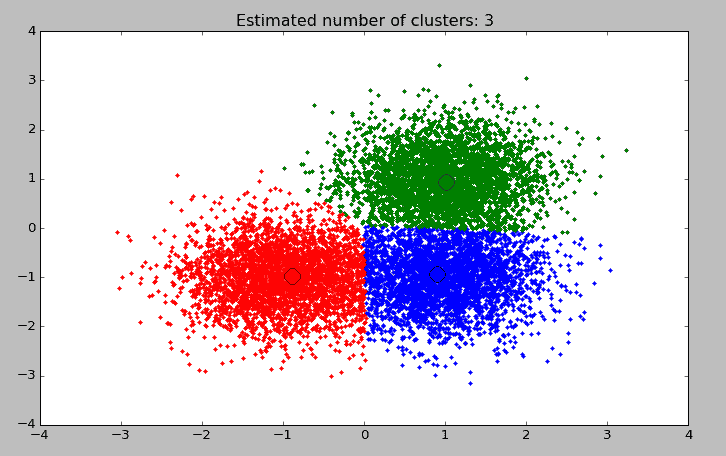
执行结果
code
核心参数配置
MeanShift 可配置的参数中,重点是 bandwidth 值的设置:
python
总结
在上述实现算法中,我们强调了 Mean Shift 具有很好的实时计算性。但由于 Python 中的该算法在默认情况下会使用
sklearn.cluster.estimate_bandwidth函数进行自动计算bandwidth值,而该函数的可扩展性将会成为 Mean Shift 在大量数据集下应用实时性的瓶颈。
当然,解决方法是不使用其默认的 bandwidth 计算函数,而是自己指定一个数值。这就要求操作人员对原始数据集、算法和应用场景有比较好的先验经验,一定程度上提高了应用要求。