3.12.1 网页数据解析

“以抓取亚马逊商品数据为例,演示使用Python进行网页数据解析的完整流程。涵盖网页结构与URL规则分析,以及利用requests、BeautifulSoup和正则表达式实现分页请求、标签解析与数据本地存储的代码实操。同时指出实际作业需应对反爬虫机制,且爬虫数据多作为企业运营的辅助参考。”
说明:本文是《Python 数据分析与数据化运营》中的“3.12.1 网页数据解析”。
-----------------------------下面是正文内容--------------------------
本节通过一个稍微复杂一点的示例,来演示如何抓取并解析网页数据。之所以说复杂,是因为本节中会出现几个本书中未曾提及的知识和方法,从代码数量来看也会比之前的示例稍微长一点。
本示例中,将使用 requests、bs4、re、time 库进行网页数据读取、解析和相关处理。
示例的目标是抓取亚马逊中国网站苹果手机和配件的价格,用于做竞争对手的标杆商品价格监控。注意:本示例仅做学习之用。
在抓取和解析网页数据之前,首先要做的是做网页内容分析,包括:
- 要抓取的内容格式:文本、图像还是其他文件。
- 是否存在重定向:重定向往往根据
User-Agent来判断,例如手机端、电脑端卡看到的页面信息不同。 - 是否需要验证:很多网页的爬虫都需要用户登录、验证码等。
- 目标数据是否具有统一标签规则:要爬取的数据是否具有统一的 HTML 标签,便于后期处理。
- URL规则:大多数情况下网页爬取都不是只有一个页面,而是多个页面,因此需要了解不同页面的 URL 规则,尤其是带有条件查询的,需要了解具体参数。
- 业务常识性分析:根据实际要爬取的数据,分析可能会产生哪些字段,会有哪些冲突和包含关系以及关联性影响等。
点击亚马逊中国网站左侧进入二级导航“手机通讯”中的 Apple Phone:Apple - 手机 / 手机通讯 - 电子 -亚马逊
要抓取的内容格式分析
笔者的浏览器是 Chrome,在当前页面中点击快捷键 F12,打开开发者工具(或者点击右上角扩展按钮
Elements 切换到查看页面元素视图。
鼠标点击开发者工具栏左侧的,然后点击页面中的商品价格、标题等,多测试几个商品,发现价格是文本格式(不是调用的外部图像)。
同样的方法点击商品描述,分析下商品标题的特点。商品标题用来存储某个价格对应的商品,该标题中的关键字可用于识别出具体商品型号并与企业自身商品做比较。
是否存在重定向分析
点击开发者工具左侧的第二个图表,通过浏览器模拟当前是一个移动设备环境,然后按 F5 刷新该页面。原来适配到电脑上的页面现在改为适配移动端,然后按照刚才的方法查看要抓取的数据是否格式仍然相同;除了显示的样式不同可能导致的页面展示和规则不同外,不同平台的商品价格可能存在不同(例如移动端比 PC 端便宜 10 元),如果需要区分平台,那么可以分开抓取。本节仅以电脑上的可视网页做示例进行抓取。
是否需要验证分析
由于页面中浏览商品时没有任何需要登录、注册等验证信息,因此无需验证可直接访问。
目标数据是否具有统一标签规则
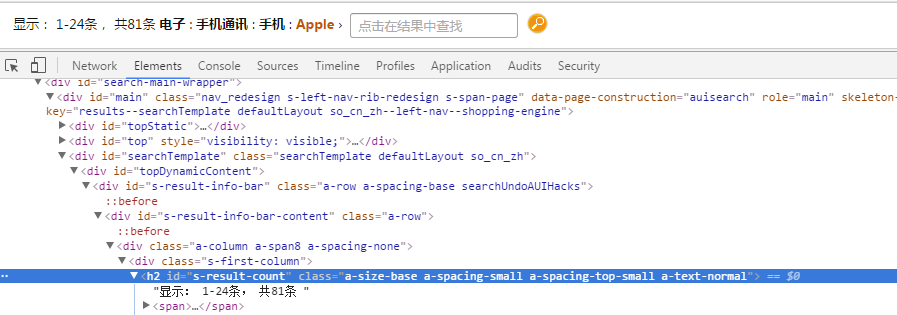
通过查看源代码发现,不同的商品通过 li 标签进行列表展示,每个 li 下对应一个商品。在 li 子层级的标签中,类为 "a-size-base a-color-price s-price a-text-bold" 的 span 标签包含了价格信息,h2 标签总则包含了商品标题。因此我们只需要找到这两个特征的标签即可解析出目标数据。
相关知识点:HTML 标签
超文本标记语言(HTML)的标签是 HTML 语言的基本单位,也是设计网页的基本元素。我们查看源代码(在任意页面右键,弹出的菜单中点击查看页面源代码,或使用快捷键 Ctrl+U),都能发现 HTML 标签构成了所有代码的“骨架”。不同的 HTML 标签的作用不同,我们在爬虫网页内容时“看到”(指的是前台展示的信息)的内容通常都是在 body 标签里面的。上述示例中几个 HTML 标签的基本含义:
-
li:HTML 中的列表,用来展示多个并列的项目信息。 -
h2:HTML 中的二级标题,一般表示强调,一般呈现的是字体加粗增大的效果。 -
span:定义一个文字段落。
上面这些不同的标签以及效果(HTML 里面被称为样式),可以通过多种方法在多个地方定义和引用,不同的定义之间会有覆盖效果。因此,标签本身的默认效果可能被更高优先级的样式覆盖而无法显示出来。
URL 规则分析
在 URL 规则部分,URL 中 https://www.amazon.cn/s/page=1&ie=UTF8&rh=n%3A665002051%2Cp_89%3AApple%2Cn%3A664978051 不同的页码变化的是 page=*,其中 * 是指示不同的页码,因此我们只需要获得总页面数量,然后依次循环读取数据即可。通过观察页面分析,页面中并没有直接显示页面总数量的信息,不过我们可以通过页面左上角的总返回结果数计算得出。
默认我们打开的是第一页,因此有关返回结果的三个数据分布表示第一页商品的起止数以及总商品数,我们用 (总商品数 / 第一页商品数) + 1 便可以得出总页面数。例如 (81 / 24) + 1 = 4。关于页面这三个数字可以通过“要抓取的内容格式分析”的方法找到页面数量的信息,位于 id 值为 s-result-count 的 h2 标签内。
业务常识性分析
本节示例中的商品没有苹果手机的统一型号编码,只有标题的描述信息可用,因此后期还需要跟实际苹果手机进行匹配,该工作建立一个匹配表,后期定期维护和增量更新即可。
到此为止我们基本确定了抓取思路:先从打开页面计算得到总页面数量,然后循环读出不同的页面信息;接着在每个页面找到每个商品的标题和价格,并把数据保存到本地文件。
清楚了上述基本情况后,我们开始编写代码,完整代码如下:
python
上述代码以空行分为 6 个部分。
- 第一个部分导入库,具体用途在注释中已经注明。
- 第二个部分开始我们每个功能都定义为一个函数模块,用于在不同场景下引用。
get_total_page_number模块用来计算页面数量。 - 第三个部分定义了一个用于解析单个 URL 的函数模块,在定义 URL 的部分,由于原始 URL 中有
%,这会导致我们新增占位符时做外部数字引用报错,因此将其分开定义再组合。在解析不同的标签(包括后面的模块)时,我们用到了正则表达式模块,可以非常容易的解析出目标字符。 - 第四个部分是将每次解析的标题和价格写入文件。文件以追加模式打开,这样每次的数据都会追加到文件尾,而不会覆盖之前的数据,类似于数据库的追加模式操作。在写文件内容时,末尾需要有换行符,否则所有数据都会合并到一行。
- 第五个部分是通过一个循环来调用执行多个页面进行解析。第六个部分函数用来执行所有的操作。
上述代码执行后返回结果如下:
调试窗口输出信息:
code
程序执行目录下产生一个跟运行时间相同的数据文件,如下是文件部分数据:
提示 上述的抓取执行过程中,“遭遇”到了亚马逊的反爬虫应对措施。
经过测试,连续执行 2 次代码,第二次会返回 HTML 代码,但没有目标数据;连续第 3 次,HTTP 请求直接无法返回数据。
大多数情况下,通过网络爬虫获取数据都是辅助方式,原因是现在基本上所有的网站都有防爬虫的意识和方式,这导致数据爬取会受到外部很多因素的影响而导致数据质量低下。基于爬虫的主要工作内容包括舆情监测、市场口碑、用户情绪、市场营销等方面,属于外部属性较强的“附加”工作。这些工作其实都不是公司的核心运营内容,这就会导致这些工作看似有趣并且有价值,但真正对企业来讲价值很难实际体现。
相关知识点:函数
函数是用来形成一段功能的代码段,函数可以用来给其他应用做调用。使用函数的好处很多:
- 利于维护:代码中有变更的功能时,只需要对特定代码段进行修改,而无需全部修订。
- 复用:当某个功能会被很多应用调用时,通过函数可实现一次撰写多次使用的目的。
- 清晰化功能设计:当设计功能时,不同的函数模块类似于功能主题,同时基于函数又可以派生库、类、包,通常函数是模块划分的基本单位。
- 递归:使用函数可以实现一种特殊的功能叫做“递归”,函数内部的功能调用函数自身,实现“自循环”,这种经常被用到有固定规律的场景下,例如求阶乘。
定义函数使用 def [函数名] 即可,函数可用来执行单独的任务,也可以通过 return 返回执行结果,用来与其他功能做交互使用。同时,不同的函数间可以通过赋值进行参数传递和调度之用。
上述过程中,主要需要考虑的关键点是:如何根据不同网页的实际特点,尤其是对于反爬虫的应对来正确读取到网页源代码,读取后源代码之后的解析往往不是主要问题。
代码实操小结:本小节示例中,主要用了几个知识点:
- 通过
requests库发送带有自定义head信息的网络请求 - 通过
requests返回对象的text方法获取源代码文本信息 - 使用
bs4的BeautifulSoup库配合find方法进行目标标签查找和解析,并通过其text方法获得标签文本信息 - 通过
re的正则表达式功能,实现对于特定数字规律的查找 - 通过定义
function函数来实现特定功能或返回特定结果 - 通过
for循环读取数据列表 - 通过
if条件判断实现对符合条件的记录做处理 - 对文本文件的读写操作
- 使用
time的localtime、time、strftime方法做日期获取以及格式化操作