使用sklearn中的决策树tree 库做分类分析

“本文详细演示了基于 sklearn 构建决策树分类模型的完整实战流程。内容涵盖数据集划分、模型训练、混淆矩阵与核心评估指标(AUC、F1等)的计算,并结合 matplotlib 与 pydotplus 实现了 ROC 曲线、特征重要性及决策树规则图的可视化输出,最终完成新数据的分类预测。”
sklearn 分类模型实战:基于决策树的训练、评估与可视化
sklearn 中没有一个专门的分类算法库,分类算法分散在不同的方法库中,例如 ensemble、svm、tree 等,在使用时需要分别导入不同的库来使用其中的分类算法。
本示例模拟的是针对一批带有标签的数据集做分类模型训练,然后使用该模型对新数据集做分类预测。主要使用 sklearn 做分类、用 matplotlib 做图形展示。
一、 核心工具与环境准备
本节会用到两个新的图形和表格展示库:prettytable 和 pydotplus,以及配合 pydotplus 的 GraphViz 程序。
- prettytable:用来做表格格式化输出展示。它的好处是可以非常容易地对行、列进行控制,并且输出带有分割线的可视化 Table。
- pydotplus:在决策树规则输出时用到的库,其输出的 dot 数据可以供 GraphViz 绘图使用。要能完整使用该库,需要先安装 GraphViz 程序,然后再安装
pydotplus。
1. 安装 prettytable
第一次使用该库需要先通过系统终端命令行窗口(或 PyCharm 中底部的 Terminal 窗口)在线安装:
bash
安装成功后,在 Python 命令行窗口输入 import prettytable,无报错信息则说明该库已经正确安装。
2. 安装 GraphViz 与 pydotplus
- 第一步:安装 GraphViz 程序。这是一个额外的应用程序,而不是一个 Python 附属包或程序。读者可登陆 GraphViz 官网 下载。第一次登陆该网站时需要阅读须知,阅读完之后可直接点击底部的 Agree,然后到达下载程序窗口,按照不同的操作环境选择下载或安装方式。笔者的电脑是 Windows,选择的是
graphviz-2.38.msi。下载完成之后的安装过程没有任何难点。 - 第二步:安装 pydotplus。这是一个从 dot 数据读取数据格式并保存为可视化图形的库。在系统中打开终端命令行窗口输入以下命令,几秒钟之内就能完成自动下载安装过程:
bash
二、 完整实战代码
完整代码如下(代码以空行分为 9 个逻辑部分,后文将逐一解析):
python
三、 代码分步解析与知识点拓展
1. 第一部分:导入库
本示例中使用了 sklearn 的 tree 库做分类预测、metrics 库做分类指标评估、model_selection 库做数据分区;使用 numpy 辅助于数据读取和处理;使用 prettytable 库做展示表格的格式化输出;使用 pydotplus 来生成决策树规则树形图;使用 matplotlib 的 pyplot 库做图形展示。
2. 第二部分:数据准备
使用 numpy 的 loadtxt 方法读取数据文件,指定分隔符以及跳过第一行标题名;然后使用矩阵索引将数据分割为 X 和 y;最后使用 sklearn.model_selection 的 train_test_split 方法将数据分割为训练集和测试集,训练集数量占总样本量的 70%。
💡 拓展知识点:将数据集划分为训练集、测试集和验证集
在很多场景中需要将数据集分为训练集、测试集和验证集三部分。sklearn 没有提供直接将数据集分为 3 种(含 3 种)以上的方法,我们可以使用 numpy 的
split方法划分数据集。split参数如下:split(ary, indices_or_sections, axis=0)
- ary:要划分的原始数据集。
- indices_or_sections:要划分的数据集数量或自定义索引分区。如果直接使用整数型数值设置分区数量,则按照设置的值做等比例划分;如果设置一个一维的数组,那么将按照设置的数组的索引值做区分划分边界。
- axis:要划分数据集的坐标轴,默认是 0。
数据集分割示例:将创建的新数据集通过平均等分和指定分割索引值的方式分为 3 份。
python上述代码执行后,返回如下结果:
code
3. 第三部分:训练分类模型
使用 sklearn.tree 中的 DecisionTreeClassifier 方法建立分类模型并训练,然后基于测试集做数据验证。DecisionTreeClassifier 为 CART(分类回归树),除了可用于分类,还可以用于回归分析。
💡 拓展知识点:tree 算法对象中的决策树规则
在决策树算法对象的
tree_属性中,存储了所有有关决策树规则的信息(示例中的决策树规则存储在model_tree.tree_中)。最主要的几个属性包括:
- children_left:子级左侧分类节点
- children_right:子级右侧分类节点
- feature:子节点上用来做分裂的特征
- threshold:子节点上对应特征的分裂阀值
- values:子节点中包含正例和负例的样本数量
上述属性配合节点 ID、节点层级迭代便能得到如下的规则信息:
code其中规则开始的
1代表节点 ID,rfm_score是变量名称,rfm_score <= 7.8375是分裂阀值,gini = 0.1135是在当前规则下的基尼指数,nsamples是当前节点下的总样本量,value为正例和负例的样本数量。
4. 第四部分:输出模型概况
由于分类算法评估内容较多,因此从这里开始将分模块输出内容以便于区分。本部分内容中,通过 X 的形状获得数据的样本量和特征数量,打印输出结果如下:
code
5. 第五部分:输出混淆矩阵
使用 sklearn.metrics 中的 confusion_matrix 方法,通过将测试集的训练结果与真实结果的比较得到混淆矩阵。
接下来通过 prettytable 展示混淆矩阵并输出表格,该库会自动对表格进行样式排版,并通过多种方法指定列表、样式等输出样式:先建立 PrettyTable 方法表格对象,然后使用 add_row 方法追加两行数据,打印输出结果如下:
code
6. 第六部分:输出分类模型核心评估指标
先通过决策树模型对象的 predict_proba 方法获得决策树对每个样本点的预测概率,该数据在下面的 ROC 中用到;输出的概率信息可作为基于阀值调整分类结果输出的关键,例如可自定义阀值来做进一步精细化分类类别控制。
接着通过 sklearn.metrics 的相关方法分别得到以下核心指标:
- AUC (auc_s):ROC 曲线下的面积。ROC 曲线一般位于 y=x 上方,因此 AUC 的取值范围一般在 0.5 和 1 之间。AUC 越大,分类效果越好。
- 准确率 (accuracy_s):分类模型的预测结果中将正例预测为正例、将负例预测为负例的比例。公式为:
A = (TP + TN)/(TP + FN + FP + TN),取值范围 [0,1],值越大说明分类结果越准确。 - 精确度 (precision_s):分类模型的预测结果中将正例预测为正例的比例。公式为:
P = TP/(TP+FP),取值范围 [0,1],值越大说明分类结果越准确。 - 召回率 (recall_s):分类模型的预测结果被正确预测为正例占总的正例的比例。公式为:
R = TP/(TP+FN),取值范围 [0,1],值越大说明分类结果越准确。 - F1 得分 (f1_s):准确度和召回率的调和均值。公式为:
F1 = 2 * (P * R) / (P + R),取值范围 [0,1],值越大说明分类结果越准确。
上述指标计算完成后,仍然通过 prettytable 创建表格对象,使用 field_names 定义表格的列名,通过 add_row 方法追加数据,打印输出结果如下:
code
分析结论:从上述指标可以看出整个模型效果一般。一方面,在建立模型时,我们没有对决策树剪枝,这会导致决策树的过拟合问题;另一方面,原始数据中存在明显的样本类别不均衡问题,也没有做任何预处理工作。由于这里仅做算法流程演示,关于调优的部分不展开讲解。
7. 第七部分:模型效果可视化
目标是输出变量的重要性以及 ROC 曲线。建立分类模型维度列表和颜色列表用于图形展示,然后通过 figure 方法创建画布:
- 子网格 1:ROC 曲线。使用
subplot(1, 2, 1)定义 1 行 2 列的第一个子网格。使用plot方法分别画出模型训练得到的 ROC 曲线和随机状态下的准确率线。在使用legend方法设置图例时,使用loc=0来让图表选择最佳位置放置图例。 - 子网格 2:指标重要性。该子网格的位置是 1 行 2 列的第二个区域,其设置与子网格 1 基本相同,差异点在于这里使用了
bar方法创建条形图。
上述代码返回如下图形结果:
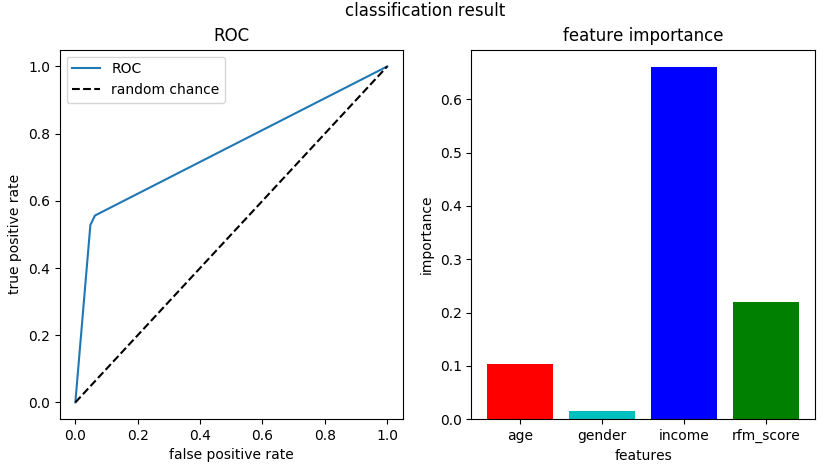
分析结论:从上述结果可以看出,ROC 曲线的面积大于 0.5,模型的算法结果比随机抽取的准确率要高,但综合前面我们得到的准确率指标,结果也不是特别理想。在特征重要性中,income 变量具有非常高的特征权重,是这几个变量中最重要的变量,其次是 rfm_score 和 age。
8. 第八部分:保存决策树规则图为 PDF 文件
先通过 tree 库下的 export_graphviz 方法,将决策树规则生成 dot 对象,各参数作用如下:
out_file=None:用来控制不生成 dot 文件,否则对象dot_data会为空。max_depth:控制导出分类规则的最大深度,防止规则过多导致信息碎片化。feature_names:指定决策树规则的每个变量的名称,方便在决策树规则中识别特征名称。filled:控制填充,让图形效果更加美化。rounded:控制字体样式。
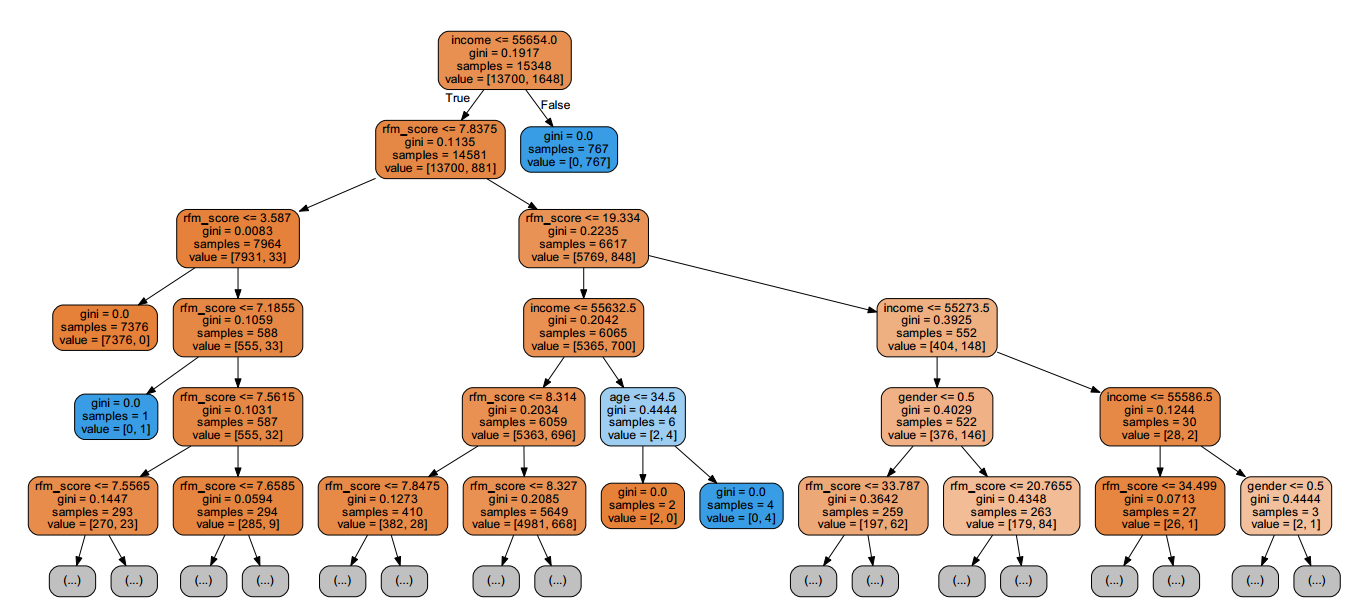
上述代码执行后,会在 Python 工作目录产生一个新的名为 tree.pdf 的文件,打开 PDF 文件,部分内容如下:
💡 提示 在 sklearn 的
tree库中,有一个特殊的方法tree.export_graphviz可用来将树形规则结构转化为 DOT 格式的数据对象,该方法只有tree库中有。在dot_data变量的代码中,可去掉out_file=None参数,默认会生成一个名为tree.dot的数据文件,该文件就是上述树形图输出的源数据。
规则解读:上述决策树规则显示了当 income <= 55654 时,总样本量为 15348,其中负例样本和正例样本分别为 13700、1648。当 income <= 55654 且 rfm_score <= 7.8375 时,总样本量有 13581,其中负例样本和正例样本分别为 13700、881。以此类推可以读出其他的规则。
9. 第九部分:模型应用
通过将新的数据集放入模型做分类预测,得到每个数据集的预测类别指标,结果如下:
code