适合大数据的聚类算法Mini Batch K-Means

“Mini Batch K-Means是专为大数据量场景优化的聚类算法。它通过分批处理抽样机制,有效解决了传统K-Means算法在海量样本下耗时过长的性能瓶颈。该算法在大幅缩减计算时间的同时,仍能保持极高的聚类准确度,实现了效率与精度的完美平衡。借助Python的sklearn库即可快速实现,是处理大规模数据聚类任务的高效方案。”
深入理解 Mini Batch K-Means:大数据量下的高效聚类算法
[K-Means 算法] 是常用的聚类算法,但其算法本身存在一定的问题,例如在大数据量下的计算时间过长就是一个重要问题。为此,Mini Batch K-Means,这个基于 K-Means 的变种聚类算法应运而生。
大数据量是什么量级?通常当样本量大于 1 万做聚类时,就需要考虑选用 Mini Batch K-Means 算法。但是,在选择算法时,除了算法效率(运行时间)外,算法运行的准确度也是选择算法的重要因素。那么,Mini Batch K-Means 算法的准确度如何?
准确度与效率的完美平衡
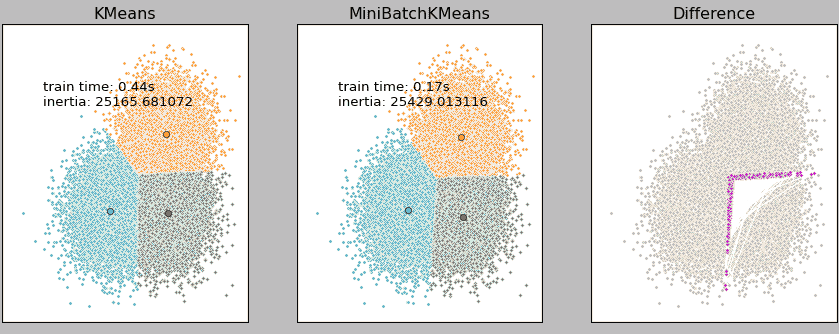
上图是我们对 3 万的样本点分别使用 K-Means 和 Mini Batch K-Means 进行聚类的结果。由结果可知,在 3 万样本点的基础上,二者的运行时间相差 2 倍多,但聚类结果差异却很小(右侧粉红色的错误点)。
因此,Mini Batch K-Means 是一种能尽量保持聚类准确性,同时大幅度降低计算时间的聚类模型。
K-Means 的性能瓶颈:计算时间与样本量的关系
K-Means 的计算时间到底跟样本量之间是怎样的关系?(用脚想也知道是样本量越大,计算时间越长),我们用一个实例来实验下。
在下面的例子中,利用 Python 生成一个具有三个分类类别的样本类,其中的样本点(二维空间)的数量从 100 开始增长到 1,000,000(步长为 1000),我们用图例来看看计算时间与样本量的关系。(为了得到下面这幅图,我等了 2 个小时)结果如下:
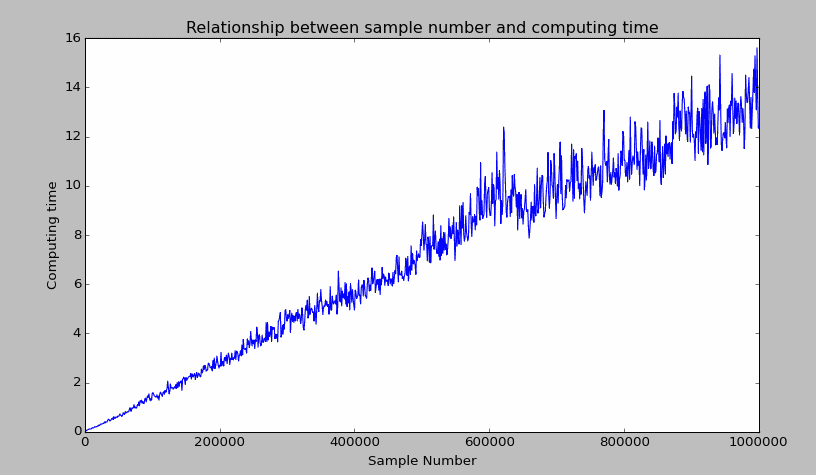
从图中可以发现,在样本点为二维空间前提下:
- 当数据量在 2 之下时,计算时间都可以接受(2 秒以内);
- 但是计算时间跟数据量基本成线性关系,计算 1,000,000 个样本聚类耗时近 16 秒。
由此可以试想,如果你的观测点有更多维度(更多维度意味着需要更多的计算量),那么耗时将比上述场景大很多。
核心原理:什么是 Mini Batch?
回到本文的主体算法 Mini Batch K-Means 上来,应用 Mini Batch K-Means 能尽量在保持数据准确性的前提下降低运算时间,它是怎么做到的?
Mini Batch K-Means 使用了一种叫做 Mini Batch(分批处理) 的方法对数据点之间的距离进行计算。
- 核心优势:计算过程中不必使用所有的数据样本,而是从不同类别的样本中抽取一部分样本来代表各自类型进行计算。由于计算样本量少,所以会相应地减少运行时间。
- 必然代价:抽样也必然会带来准确度的下降。
实际上,这种思路不仅应用于 K-Means 聚类,还广泛应用于梯度下降、深度网络等机器学习和深度学习算法。
Python 代码实现
Mini Batch K-Means 的使用方法非常简单,跟 K-Means 一样,在 Python 的机器学习库 SKlearn 中,通过 fit 方法训练数据,然后通过 labels_ 属性获得每个样本点的聚类结果值。
演示代码如下:
python
运行结果如下:
code
应用场景与参数配置
由于 Mini Batch K-Means 跟 K-Means 是极其相似的两种聚类算法,因此应用场景基本一致,具体请参考 [K均值(K-Means)]。
其中,Mini Batch K-Means 可配置的参数如下:
python
补充说明(尾巴)
- 默认聚类数量:默认情况下,无论是 K-Means 还是 Mini Batch K-Means 都是需要指定聚类数量,即算法里面的
n_clusters参数值,但实际应用时发现不指定也是可以的。这并不意味着 Python 会“自动”帮你选择最佳类别数,而是已经预置了一个默认的类别 8。如果你不去设置,它会默认分为 8 个类别。 - Mini Batch 的定义与大小:既然是通过 Mini Batch 进行抽样,那到底 Mini Batch 是什么?Mini Batch 是原始数据集中的子集,这个子集是在每次训练迭代时抽取的样本。这个值默认是 100 个,可以通过
batch_size参数进行设置。