《Python数据分析与数据化运营》第二版 勘误

“本文为《Python 数据分析与数据化运营》第二版的官方勘误表,汇总了书中23处细节错误及修正方案。内容涵盖文字拼写、代码逻辑、参数设置、库版本更新及数据展示等问题的详细说明与正确代码示例,并提供了最新版本代码的同步更新链接,旨在帮助读者准确理解并实践书中的数据分析与运营模型。”
《Python 数据分析与数据化运营》第二版勘误表
本书默认已经修正了第一版遇到的所有问题,因此以下勘误仅限于第二版。有关第一版的勘误,请见 《Python 数据分析与数据化运营》第一版勘误。
版本与代码更新说明
由于第二版的出版时间为 2019 年,我已经将最新版本的代码更新到博客中,地址为:《Python 数据分析与数据化运营》第二版新老版本代码对比。安装和使用最新版本的读者可参照该链接的代码。
最近更新时间:2021-10-14
最近一次新书重印更新为 2020-11(第 2 版第 4 次)重印,读者可查看“前言”的前 1 页找到相关信息,如下:

详细勘误列表
1. 第 108 页:文字拼写错误
第二段文字中,“英语、数据、语文成绩……”中的“数据”应更正为“数学”。


解释:如图圆圈处文字
2. 第 149 页:聚类离散化数值修正
最下面的 amount2 的值应该是 4 个,对应的数据也应该是 4 个值。使用聚类法实现离散化,k=4,那么应该代表 4 类数据,对应的唯一值应该是 0, 1, 2, 3。

3. 第 93 页:缺失值处理方法名修正
在描述缺失值的方法中,页面顶部描述文字中,“通过 df.null 方法找到所有数据……”中的 df.null 应该更正为 df.isnull()。
4. 第 396 页:交叉验证代码变量名修正
在“模型训练-交叉验证”章节的代码中,这是对集成模型的交叉检验测试,而非单个模型。
- 原代码:
python
- 应改为:
python

5. 第 179 页:库名称拼写遗漏
最底部最后一行的文字表述中,“不能直接 fit 到 klearn 的 K-Means 模”中的 klearn 缺少一个字符 s,应更正为 sklearn。

6. 第 198 页:错别字修正
左侧靠中间位置的文本描述中,(1)部分,“此时的回归模型及其不稳定且方差较大”中的“及其”应更正为“极其”。

7. 第 347 页:Pipeline 代码段遗漏补充
在“步骤 5 模型训练 - 建立 pipeline 中用到的模型对象”模块中,原文只有已经构建好的每个 model,而遗漏了 pipelines 的构建代码。

正确的完整代码应为:
python
8. 第 102-104 页:原始数据维度与输出描述修正
在第 102 页“第 2 部分生成原始数据”中,中间部分 print(df) 之后的文字描述有误。
- 原描述:“数据为 3 行 3 列的数据框,分别包含 id、sex 和 level 列,其中的 id 为模拟的用户 ID,sex 为用户性别(英文),level 为用户等级(分别用 high、middle 和 low 代表三个等级)”
- 应改为:“数据为 3 行 4 列的数据框,分别包含 id、sex、level 和 score 列,其中的 id 为模拟的用户 ID,sex 为用户性别(英文),level 为用户等级(分别用 high、middle 和 low 代表三个等级),score 列为用户得分等级(其中 1/2/3 分别是等级字符串,而非数字)”

补充说明:由于新增了一列,第 102-103 页对应的结果中应该包括
score列特征。在print(raw_convert_data)后,会输出score信息。同理,在第 104 页中间部分的输出,也会包含score_1,score_2,score_3的信息,请读者知悉。
9. 第 180 页:重复导入库代码
“第 1 部分导入库”中 import matplotlib.pyplot as plt 被重复导入。代码可直接忽略重复部分,或删除其中任意一条。

10. 第 187 页:df.head() 输出记录条数说明
在本书第二版的撰写中,由于新增了很多内容,正常情况下 print(df.head()) 应该输出 5 条记录。但书中的示例中只有 3 条,原因是笔者手动删除了 2 条以减少页面代码量。在代码正式执行下不会出现该问题,请读者知悉。
11. 第 103 页:编码对象描述修正
中部文字描述有误。
- 原文:“在该过程中,先建立一个 LabelEncoder 对象 model_LabelEncoder,然后使用 model_LabelENcoder 做 fit_transform 转换,转换后的值直接替换上一步创建的副本 transform_data_copy,然后使用 toarray 方法输出为矩阵”。
- 应改为:“在该过程中,先建立一个 OneHotEncoder 对象
model_enc,然后使用model_enc做fit_transform转换,然后使用toarray方法输出为矩阵”。

12. 第 126 页:代码排版样式错误
上部分 from sklearn.svm import SVC # SVM中的分类算法SVC 这段代码本身属于代码格式,脱离了代码段,应与正文区分开并与上面的代码样式合并。

13. 第 63 页:SQL 正则表达式概念严谨性修正
在 SQL 相关功能中提到的正则表达式部分,LIKE 不属于通用意义上的正则表达式,只是在 MySQL 中用于实现类似正则表达式功能的关键字。

14. 第 77 页:参数拼写错误
subplot 段落中的 nrws 应更正为 nrows。

15. 第 78 页:OpenCV 大小写规范
2.3.4 内容中,“Python 读取视频最简单的库也是 Opencv”中的 Opencv 应注意大小写,更正为 OpenCV。

16. 第 126-127 页:数据读取分隔符与展示结果修正
3.4.6 内容中 data2.txt 的数据读取方式错误。在“第 2 部分 导入数据文件”中,pd.read_table 的 sep 参数值应该是 \t。
正确代码:
python
同时,读取之后数据的展示中,label 为 0 和 1 的数据结果应该如下:

code
受源数据影响,第 127 页的数据处理后结果展示也相应变化:
第 127 页顶部的数据展示:
code
第 127 页中部的数据展示:
code

17. 第 235 页:R 语言数据读取参数补充
在目前的 R 版本中,读取数据时需要在 read.transactions 中增加 header=TRUE 设置才能正确读取。完整的 Python 内嵌 R 脚本代码应为:
python

18. 第 92-94 页:Imputer 缺失值函数弃用与更新
在以前的版本中,Imputer 是 sklearn.preprocessing 的一部分,可以直接导入。在最新版本中,Imputer 方法已被弃用并拆分为多个细分方法,集成在 sklearn.impute 中。
目前包含以下 4 个细分方法:
impute.SimpleImputerimpute.IterativeImputerimpute.MissingIndicatorimpute.KNNImputer
最新版本的使用规则示例:
python
19. 第 137 页:岭回归 alpha 参数说明修正
岭回归的文字说明中,如果图中划线和画圈的两部分跟代码注释中的内容相同,alpha 的值应为 1.0。
![]()
20. 第 212 页:缺失值统计代码与打印结果修正
在“第 3 部分数据基本审查”中,原始 print 语法中的统计逻辑有误。
- 原代码:
python
其中的 raw_data.isnull().any().count() 应该改为 raw_data.isnull().any().sum()。原因是 count 得到的是总列数,而在 raw_data.isnull().any() 返回 True 或 False 后,必须通过 sum 才能得到真正为 NA 值(True)的数量。
- 正确的打印结果应为:
code
![]()
21. 第 103 页:数据打印结果列遗漏
在第 102 页中,通过 raw_convert_data = df.iloc[:, 1:] 设置了变量。第 103 页顶部的打印结果错误,应该包含 sex、level、score 三列。
当前版本的错误之处:

正确的打印结果(红框内):
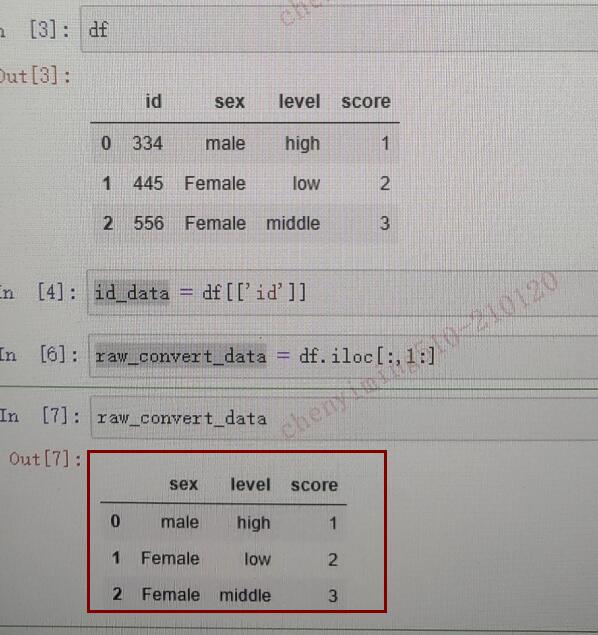
22. 第 374 页:U 检验与 Z 检验概念合并
在关于 U 检验和 Z 检验的描述中,本书将其拆分为两类。但在国内普遍将 U 检验与 Z 检验视为相同概念。因此,相关描述应合并为:
**U 检验(也称 Z 检验)**是在大样本(n>30)的情况下,检验随机变量的数学期望是否等于某一已知值的一种假设检验方法。U 检验适用于样本量 n 较大且符合正态分布的情况,也适用于比较两个平均数的差异是否显著的场景。

23. 第 470 页:聚类特征数值型索引修正
在获取数值型特征时,代码中的索引提取有误,导致获取到的是标准差数据而非均值。
- 原代码片段:
python
- 应改为:
python
完整的修正后代码:
python
补充说明:由于此处索引的修正,对应后面的图形也会产生差异,请读者知悉。