《Python数据分析与数据化运营》第二版 常见问题

“本文汇总《Python 数据分析与数据化运营》第二版常见问题及解决方案。内容涵盖第二版核心内容升级说明、Python及pyecharts等第三方库的版本兼容与环境配置指南、数据分析核心概念解析,以及具体代码报错的修复方法,为读者提供完整的学习与实践避坑指南。”
《Python 数据分析与数据化运营》第二版常见问题解答
说明:本文仅总结第二版相关的问题。有关第一版的问题,请前往“《Python 数据分析与数据化运营》第一版常见问题”查看。
由于第二版的出版时间为 2019 年,笔者已将最新版本的代码更新到博客中,地址为:《Python 数据分析与数据化运营》第二版新老版本代码对比。安装和使用最新版本的读者可参照该链接的代码。
最近更新时间:2021-06-15
一、 资源获取与版本更新
1. 第二版配套源代码下载地址
代码下载:《Python 数据分析与数据化运营》第二版 附件
2. 第二版与第一版相比有哪些变化?
本书在第一版上市后,得到了来自各行各业众多好友和读者的支持与反馈,在此致以诚挚的感谢!第二版在第一版的基础上做了大量优化甚至重写,同时新增了许多内容。
优化与重写的内容
- Python 3 全面升级:全部代码基于 Python 3 做优化或重写,书中的 Python 版本为 3.7。
- 引入 Jupyter:基于 Jupyter 做调试、分析和应用,更适合数据分析师的应用场景(包括探索性分析、数据预处理、结果可视化展示、交互式演示等)。
- 网页解析重构:网页数据解析中基于 Class 做功能封装和处理,更方便以网页对象为主体的数据工作。
- 图像处理更新:介绍了 PIL/Pillow 的替换和方法应用,应用于图像处理工作。
- 数据挖掘案例重写:第四章数据挖掘的案例部分,每一部分的案例都经过重写并增加了许多知识点,以实际案例为需求,应用数据挖掘算法做建模和分析。
- 3D 可视化:Matplotlib 调用 3D 图形展示多个维度的信息,并可通过拖拽展示不同角度下数据的分布情况。
- RFM 代码重构:第五章第一个案例 RFM 代码的重构,以及针对不同分组的精细化运营策略的制定。
- 复合数据工作流:第五章第二个案例,基于嵌套 Pipeline 和 FeatureUnion 复合数据工作流的营销响应预测,基于两层管道的 Pipeline 做数据工作流管理。
- 集成算法应用:第六章第二个案例,基于集成算法 GBDT 和 RandomForest 的投票组合模型进行异常检测。将基础算法改为 GBDT 和 RF,这两个算法分别代表模型的**“准确度”和“稳定度”**,这种兼顾“准”和“稳”的模型搭配更符合实际需求。
- 树形图可视化优化:第七章基于自动节点树的数据异常原因下探分析,优化了代码和样式,可视化效果更好并能获得更多信息(包括维度分解过程、主因子、其他因子和潜在因子等)。
新增的内容
- 环境搭建:基于 Anaconda 的 Python 环境安装和配置,更方便初学者快速搭建应用环境。
- Jupyter 进阶:Jupyter 基础工具的用法,包括安装、启动、基础操作、魔术命令、新内核安装和使用、执行 Shell 命令、扩展和插件使用、系统基础配置等。
- 特征工程扩展:
- 基于 Pandas 的
get_dummies做标志转换(即 OneHotEncode 转换)。 - 特征选择降维中,新增
feature_selection配合SelectPercentile、VarianceThreshold、RFE、SelectFromModel做特征选择。 - 特征转换降维中,新增 PCA、LDA、FA、ICA 数据转换和降维的具体方法。
- 特征组合降维中,新增基于 GBDT、
PolynomialFeatures、gplearn的 genetic 方法做组合特征。
- 基于 Pandas 的
- 算法与可视化扩展:
- 第四章分类算法中,新增使用 XGBoost 做分类应用,以及配合 Graphviz 输出矢量图形。
pyecharts数据可视化的应用和操作,尤其是关联关系图的应用。
- 跨语言与自动化:
- Python 通过
rpy2调用 R 程序实现关联算法的挖掘(包括直接执行程序文件、代码段、变量使用等)。 - Python 通过
rpy2调用auto.arima实现自动 ARIMA 的应用,降低时间序列算法的应用门槛。 - 自动化学习:增加了对于自动化数据挖掘与机器学习的理论、流程、知识和应用库介绍,并基于 TPOT 做自动化回归和分类学习案例演示。
- Python 通过
二、 环境配置与依赖问题
3. 为什么完全按照书上敲代码会报错?
“代码在其他人的电脑上能正常运行,而在你的电脑上不行”,这种情况极大概率是版本不一致导致的。
本书的 Python 默认版本是 3.7,采用 Anaconda 安装。如果读者是自行安装的 Python,或者使用 Anaconda 安装的是 3.6 版本,就很容易出现兼容性报错。
案例说明: 有读者自行下载了 Anaconda 3.6 版本,在执行第四章程序时报错。经排查发现,该读者环境下的 Pandas 版本是
0.20.*,而笔者书中的环境是 Python 3.7 配合 Pandas0.25.*。 虽然同一个库的不同版本功能大致相同,但细节差异致命:例如在 Pandas0.20.*中,默认不支持将字符串"null"识别为缺失值;而在0.25.*中却可以。这导致如果数据中出现"null"字符串,旧版本会将其视为普通文本,而新版本会正确解析为空值(NULL)。
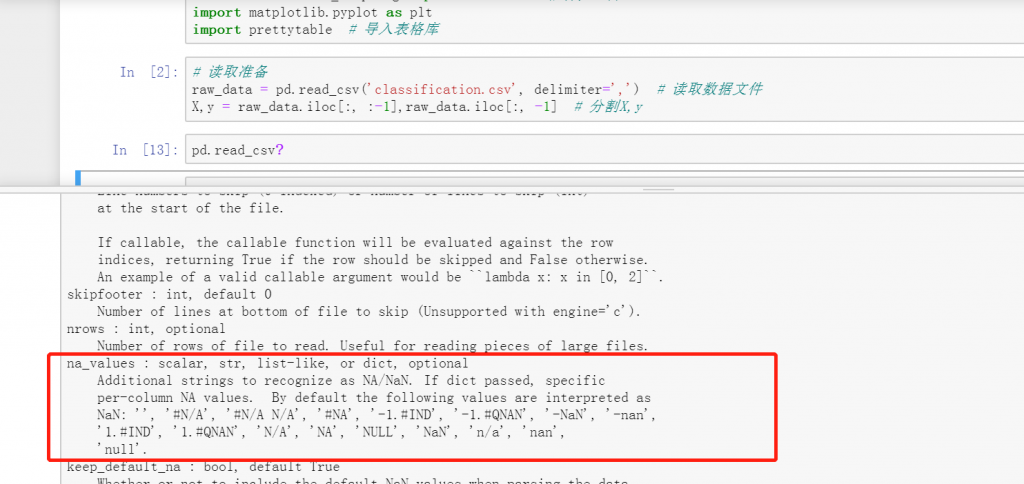
4. 第五章:导入 pyecharts 报错
在 pyecharts 库中,分为 v0.5.X 和 v1.* 两个大版本,这两个版本之间互不兼容。v1 是一个全新的版本,对应的语法也发生了较大的改变。
如果读者的环境是最新版(v1 及之后),按照书中的 from pyecharts import Bar3D 就会报错无法导入。在 v1 版本之后,需要使用以下方法导入:
python
因此,读者需要留意自己的 pyecharts 版本,并选择对应的语法。

5. 第四章:导入 pyecharts 报错
本书第二版的 pyecharts 仍然是基于 v0.5 版本实现的,而目前最新的版本已经升级到 v1.*。由于 v1.* 与 v0.5 版本不兼容,如果读者电脑上安装的是 v1.* 版本,执行图形展示代码时就会报错。
在 P238 创建关系图中,v1.* 版本的正确代码如下:
python
请读者注意区分版本使用。有关完整的数据展示代码,也可参照下文的第 6 个问题。
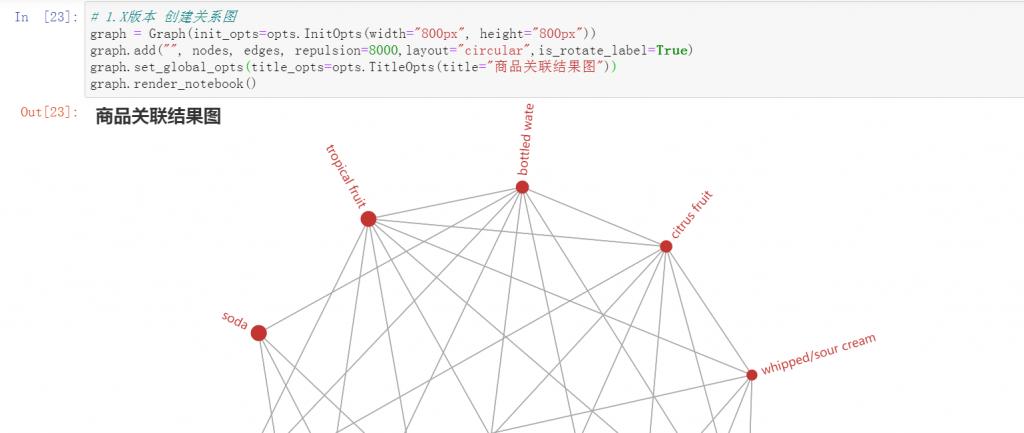
6. 第四章:pyecharts 无报错但无图形展示
在第二版第四章的关联分析环节,调用 pyecharts 展示关联结果时如果无法加载图形,通常是因为使用了 v1.* 版本的库。请替换为如下适配 v1.* 版本的代码:
python
7. 导入 apriori 时提示找不到库
在该章 P229 中,导入库的代码如下:
python
这里的 apriori 模块,并不是一个需要通过 pip 安装的第三方库,而是存放在当前“第四章附件目录”下的一个名为 apriori.py 的本地源码文件。
因此,在执行导入时,Python 默认导入的是这个本地文件的功能。这要求当前的工作目录下,必须存在该文件(在官方下载的附件压缩包里默认包含此文件)。如果提示找不到模块,读者只需通过 cd 命令将终端路径切换到该文件所在的目录(第四章目录)下即可。
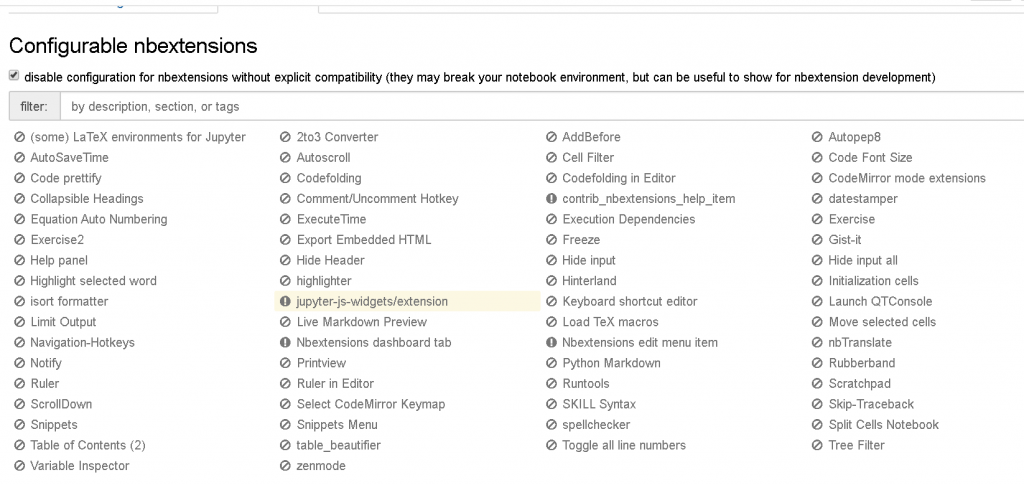
8. Jupyter 插件显示为灰色、无法勾选
按照书上的方式操作后,如果发现 Jupyter 的插件都处于灰色不可选状态,解决方法非常简单:
直接取消勾选页面标题下方“disable configuration for ...”这段文字前面的复选框即可。
9. 百度地图 API 调用无效
笔者的百度 API 注册较早,目前的百度地图 API 已经升级了 URL 地址格式。
目前最新的 API 地址格式为:
code
而笔者书中使用的旧版 API 地址为:
code
因此,后期新注册的读者,请务必使用百度最新的 API 格式;之前已经注册过旧版 API 的读者,可继续沿用笔者书中的格式。
补充说明:API 调用无效的另一个常见原因是,部分读者没有自己注册账户,而是直接使用了笔者源代码中的权限信息。目前笔者的 API 调用资源已经接近限制峰值,会导致直接使用原代码无法正常返回信息。请务必自行注册并替换密钥。
三、 核心概念与理论解析
10. 纯文本读取的 3 种方法指的是什么?
在第 2 章 P55 中提到:“对于纯文本……Python 默认的 3 种方法更为合适”。
这里指的是使用 open 方法获得读取对象后,调用 read、readline 或 readlines 读取的方法。

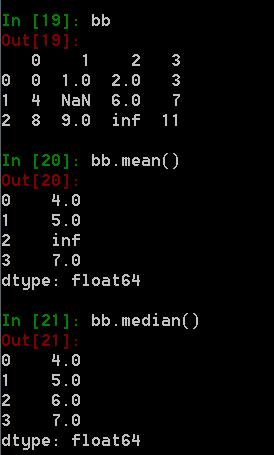
11. “中位数做兜底策略”是什么技术?
在 P96 中提到的**“兜底策略”**,指的是在任意情况下都能保障数据有效性的一种处理方式,它不是一种具体的技术。
如书中所讲,如果使用均值填充,当数据中存在 inf(无穷大)时,是无法计算均值的;而中位数则不受极端值影响,依然可以计算。这样可以保证填充数值的有效性。例如:

12. 变化维度表中的“维度行”是什么意思?
在第三章 P91 介绍变化维度表(Slowly Changing Dimensions)时提到了“维度行”。
它的意思是:将每个发生变化的维度都记录下来,并形成一条新的记录。这样每次在匹配数据时,只需要匹配当时历史状态下使用的维度即可。例如:
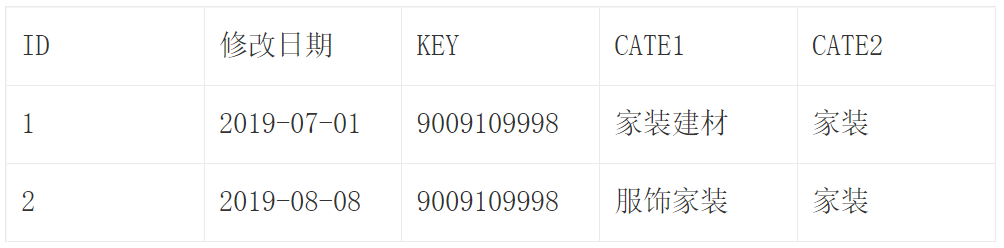
上面的表是一个变化维度表,里面的 KEY 是关联产品信息的键值,用来标记产品 ID。在这个表中,基于 ID 可以匹配出产品类别。在不同时期,该 ID 所属的一级分类(CATE1)发生了变化(例如 2019 年 7 月 1 日的值和 2019 年 8 月 8 日的属性值不同),这时可同时记录两个属性信息。后续就可以基于修改日期来判断,在不同周期下应该匹配哪个分类模式。
13. get_dummies 和 OneHotEncoder 的使用场景与区别
Pandas 的 get_dummies 和 Scikit-Learn 中的 OneHotEncoder 都能实现哑变量编码转换(书中称为标志转换),二者的核心区别在于:
- Pandas 的
get_dummies是“一次性”的:适用于单次的数据分析或探索性场景。 - Scikit-Learn 的
OneHotEncoder是“可复用”的:在每次fit之后,处理规则会被持久化保存。在预测性应用(如分类或回归)中,当新数据到来时,需要保证预测数据的转换规则与训练时完全一致,因此必须使用持久化的处理对象。这个原理跟模型训练和预测是相同的。
14. 关联规则输出结果中,item1/item2 及符号的含义
在教材 P231 中,通过 Python 计算关联规则会得到结果表格。其中:
item1表示后项(Consequent,即结果)。item2表示前项(Antecedent,即条件)。
符号含义:
,(逗号):表示前项或后项集合中包含的多个不同项目。例如pip fruit, other vegetables表示该项目集中包含了 2 个项目。/(斜杠):仅仅是项目名称字符串本身自带的字符,没有特殊含义。例如whipped/sour cream整体代表一个单一项目。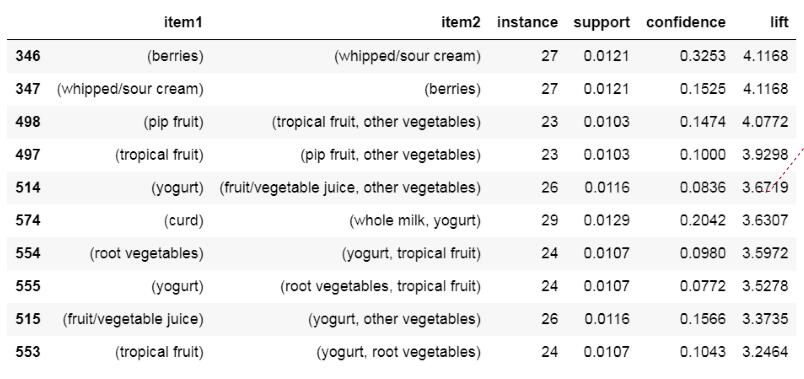
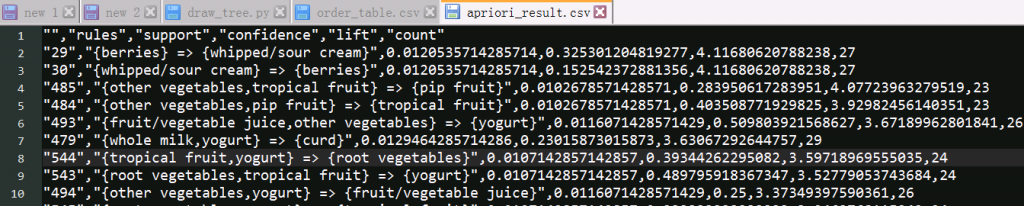
读者可参考 P340 通过 R 语言得到的关联规则,会更容易理解前项和后项的逻辑:前项是规则的前提条件,后项是规则推导出的结果。前项和后项都可以包含多个项目,从而组成项目集。
四、 代码细节与报错修复
15. 能否使用 SQL Server 代替书中的 MySQL?
可以的。Python 几乎支持所有主流数据库。
如果使用 SQL Server,可以安装并使用第三方库 pymssql,其用法几乎与 pymysql 相同;也可以使用 pyodbc,通过 ODBC 的方式连接 SQL Server。尤其是在面对海量数据(百万到千万级)写入时,设置 fast_executemany = True 可以极大提升写入速度。
16. 第七章:聚类雷达图输出 ValueError 报错
在新版本的 Matplotlib 中,输出雷达图时如果完全按照原书代码执行,会提示如下错误:
code
这是因为新版 Matplotlib 要求雷达图的标签数组必须首尾闭合。此时,只需要在 labels 数组中额外增加对初始值的闭合拼接即可。修正后的完整代码如下:
python
17. 运行 3.10.1 代码时出现 max() arg is an empty sequence
这是由于之前的博客模板存在问题导致的。后续笔者已经修改并恢复了模板。目前(2020-10-12 之后)该代码已经能正常运行并返回正确数据。
18. P201 设置的 n_folds=5 没有被使用?
是的,在 P201 页代码中定义的 n_folds=5 在后续逻辑中没有被使用,可以直接删除。
19. P93-P94 的库导入顺序是否可以调整?
可以调整。书中的导入顺序(Pandas, sklearn, pandas)是笔者在写作时未注意到的冗余问题,读者可自行精简和规范导入顺序。
20. P95 打印的各个 df 对象分别是什么?
在 P95-P96 的各个打印对象中,从上到下依次对应的是:
nan_result_pd1、nan_result_pd2、nan_result_pd3、nan_result_pd4、nan_result_pd5、nan_result_pd6。请读者在阅读时注意区分。