《电商流量数据化运营》第一版常见问题

“《电商流量数据化运营》读者Q&A详述了图书资源获取渠道与偏重业务实践的内容定位。重点解答了电商数据化运营中的核心算法与业务疑难,包括多维度行为权重加权汇总的底层逻辑、A/B测试中贝叶斯评估方法的Beta分布原理,以及使用Shapley值分析特征对转化目标正负向影响时的数组选择依据。”
《电商流量数据化运营》读者常见问题解答(Q&A)
最近更新时间:2021-11-14
一、资源获取与购买指南
1. 本书的附件在哪里下载?
下载地址为:《电商流量数据化运营》附件
2. 书在哪里可以买到?
通用的买书渠道(如在线渠道)均可购买:
线下书店可能也有销售,具体需视渠道而定,但网上购买最为方便。
另外,本书也提供电子书版本,大家可以前往京东读书、亚马逊 Kindle、微信读书查看。
3. 书是黑白印刷的,有原始彩图吗?
书的彩图已经统一放在随书附件中。大家下载后,会看到压缩包里有一个专门的文件夹存放原始彩图,如下所示:
二、内容定位与学习准备
1. 本书与《Python 数据分析与数据化运营》有什么区别和联系?
两本书的区别与联系主要体现在以下三个方面:
- 逻辑上:《Python 数据分析与数据化运营》是**“总”,包含了更广泛的运营话题;而《电商流量数据化运营》是“分”**,是其中关于流量运营的分支。后续还会陆续推出会员运营、内容运营、商品运营、活动运营、网站运营等主题的专著。当然,前者也会继续改版以适应新时代的发展需求,内容结构将更加完整。
- 内容上:《Python 数据分析与数据化运营》更偏**“分析”,包含了大量的维度、指标、分析方法、数据模型与实战经验;而《电商流量数据化运营》更聚焦于业务实践,更偏“业务”**,内容围绕“如何做流量运营”的全过程展开,探讨数据如何发挥价值。
- 工具上:《Python 数据分析与数据化运营》完全使用 Python;而《电商流量数据化运营》则以 Excel 为主,辅以 Python 实现。
2. 书里面的案例多吗?
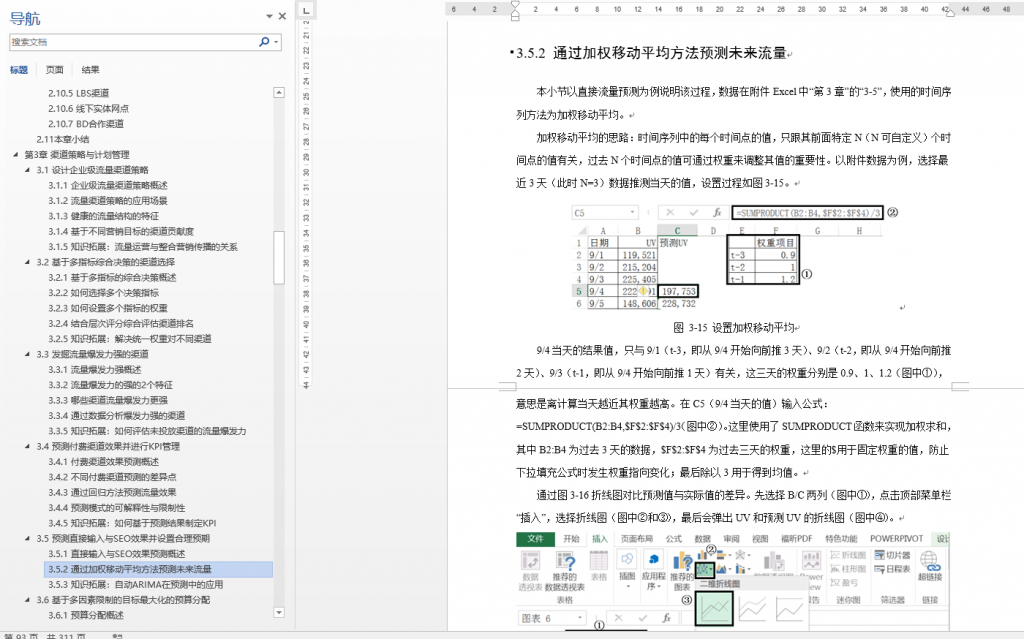
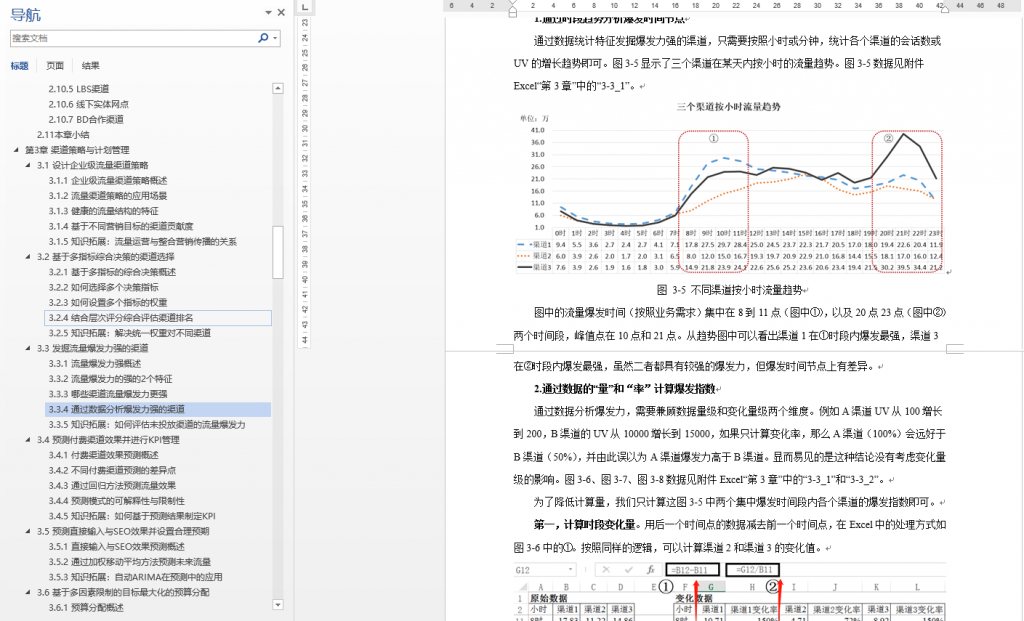
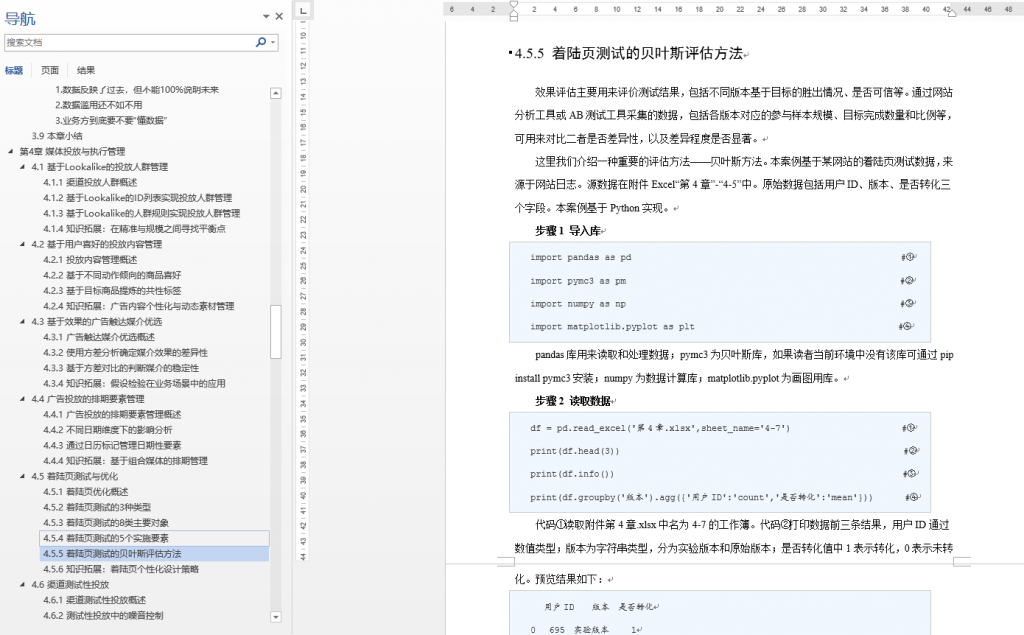
本书从第 3 章到第 7 章,基本每个小节(二级标题)下都有 1~2 个案例。例如:
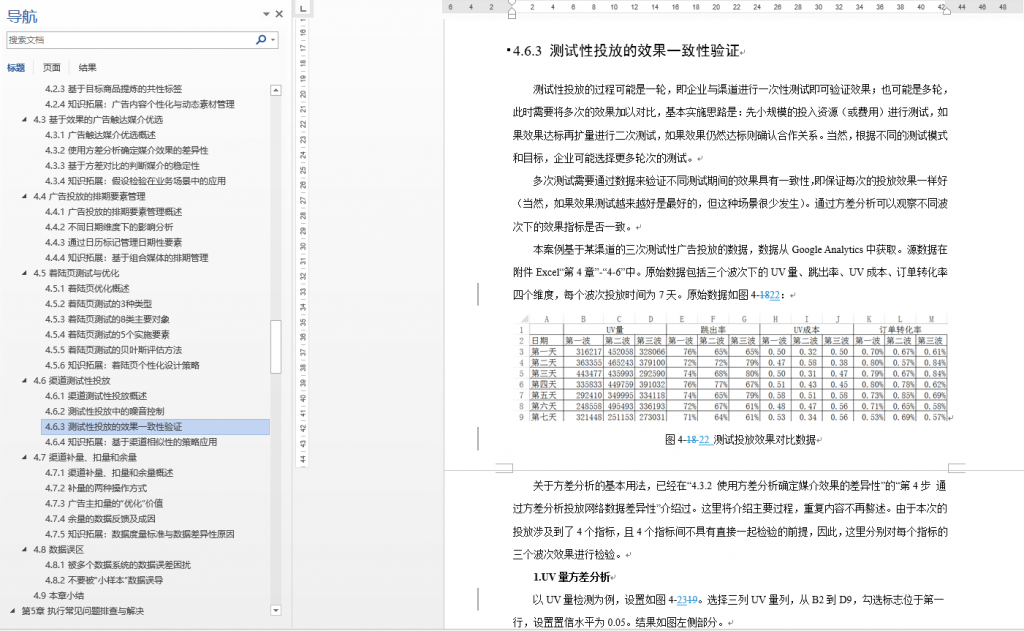
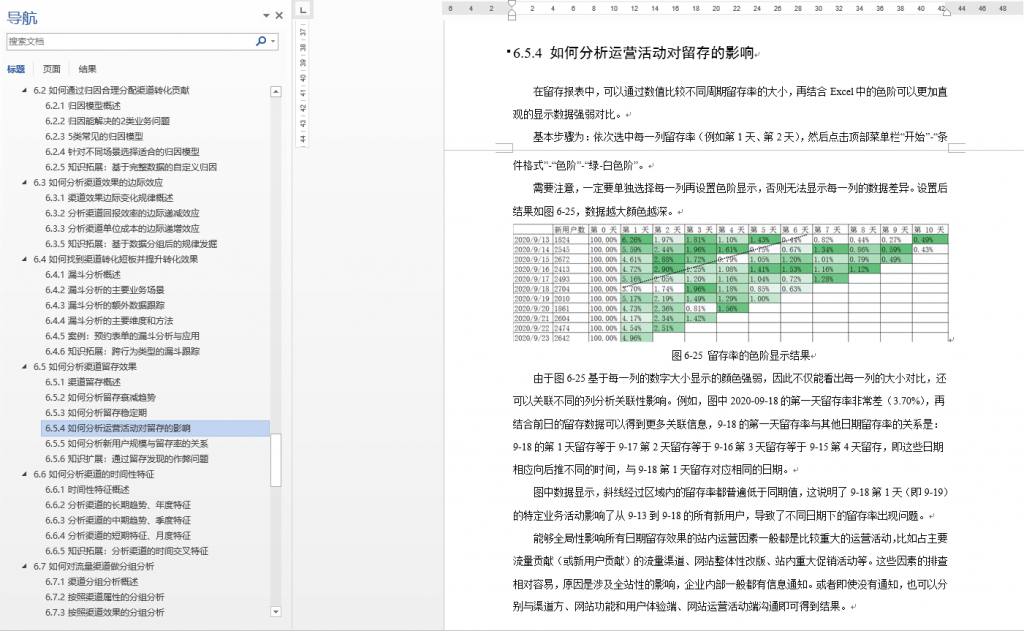
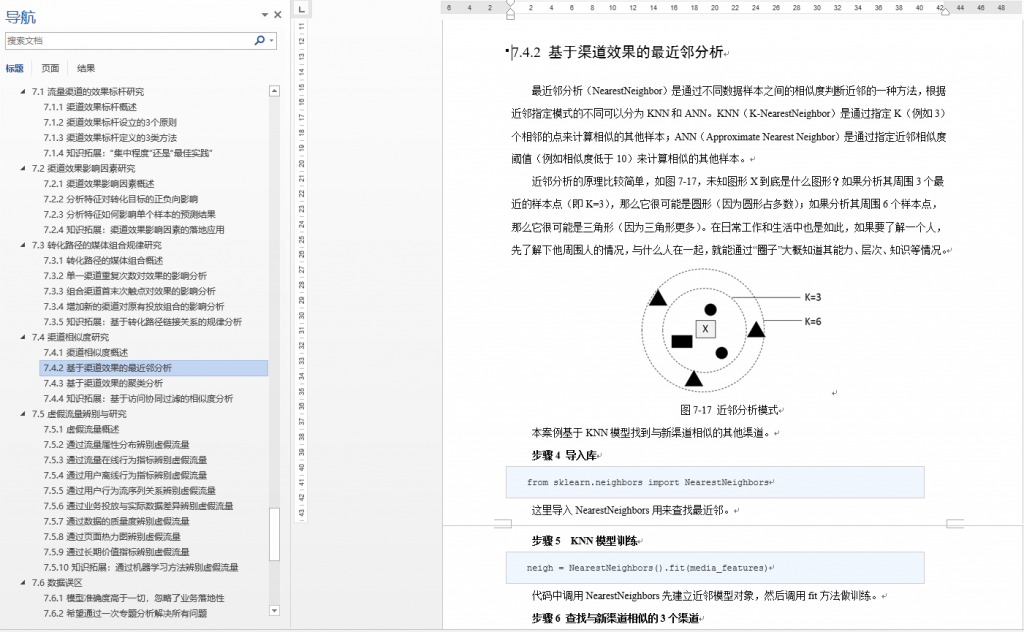
3. 书里的案例使用的是什么工具或语言?
本书的案例实现工具主要有两个:
- Excel:案例实施占比约为 70%~80%(工具版本为 Office 2013)。
- Python:案例实施占比约为 20%~30%(版本为 3.8,同样适用于 3.9 及最新的 3.10)。
三、核心业务与算法答疑
1. 为什么需要将不同行为和场景的权重加权汇总?(4.2 节)
在 4.2 节**“基于用户喜好的投放内容管理”中,第四步“为商品增加权重”出现了两层权重:商品互动事件类型的权重和商品互动产生的场景的权重**。之所以需要如此复杂的权重关系,原因如下:
第一,用户表达喜好的行为存在差异。 不同的人对于喜好的表现行为不同。例如,有的人会多看,所以“浏览”是评价喜欢与否的重要标志;有的人表现为“搜索”,有的人则是“购买”。在用户行为上存在千差万别的“喜欢表现”,如果只使用 1 个字段(或单一商品互动事件),概括的行为就不够完整和全面,必然会有所偏颇。因此,需要综合考虑多个行为事件。
第二,场景与页面事件是多对多的关系。 既然针对不同行为设置不同权重即可,为什么还需要区分场景?因为场景和页面事件并不是一对一的关系。以“商品浏览”事件为例,它指的是商品的曝光(类似于站外广告的 Impression),而商品可以在多个场景下曝光(如产品 A 在首页、搜索页、个人中心页都有推荐展示)。
第三,不同的场景对核心 KPI 的影响是不同的。 这就好比站外广告渠道,对于同一个人,我们会认为从高质量渠道进入时,其“此次”的价值度更高。举个日常生活的例子:同一个人,由知名教授介绍给 A 认识,和由普通人介绍给 A 认识,A 会更倾向于认为知名教授介绍时认可度更高。两者的底层逻辑是相同的。
因此,才有了类型和场景分别产生权重再汇总计算的逻辑。
2. 着陆页测试的贝叶斯评估方法原理解析(4.5.5 节)
关于贝叶斯原理的进一步解释与说明:
- A/B 测试:简单来说,就是为同一个目标制定两个方案,让一部分用户使用 A 方案,另一部分用户使用 B 方案,记录用户的使用情况以评估哪个方案更符合设计预期。A 方案的转化率可以看作一个二项分布。传统的频率学派认为概率
p是固定不变的(总转化数除以实验总数)。然而,贝叶斯学派不认为p是固定不变的,而是引入一个 Beta 分布作为二项分布的共轭先验,通过调整 Beta 分布参数,动态调整p的值。 - Beta 分布:Beta 分布是二项分布的共轭先验,描述了二项分布中
p取值的可能性。Beta(m, n)代表着m+n次试验中,m次 A、n次 B 的概率分布。
通俗地讲,Beta 概率是对“正面概率应该为 p”这件事情的概率分布。
实验案例对比:
假设有一枚硬币,实验 A 抛 100 次有 16 次正面,实验 B 抛 50 次有 8 次正面。
- 频率学派认为:两次实验的正面概率都是
p = 0.16。 - 贝叶斯学派认为:
Beta(16, 84)和Beta(8, 42)是完全不同的概率分布。
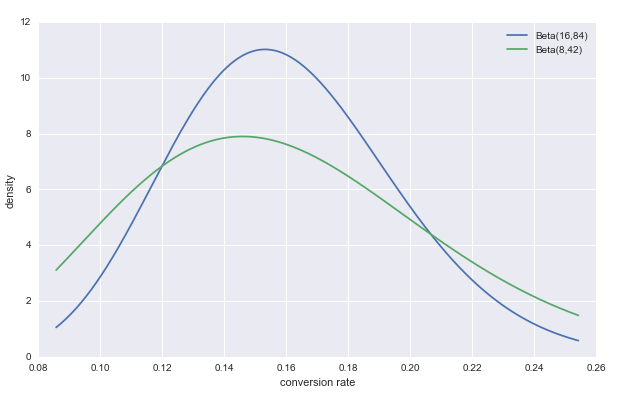
上图为两个实验的数据分布图。在
Beta(α, β)中,参数α的现实意义是正面次数,β的现实意义是反面次数。
规律的进一步解释:
虽然上述两个实验只是规模不同,但其分布密度图存在显著差异:
- 猜测值的差异:频率学派猜测正面概率
p = 0.16;而贝叶斯学派认为,以上两种情况的猜测p都小于 0.16,因为实验次数越少,真实的正面和反面差距就可能越大。 - 决策信心的差异:实验次数越少,概率密度图越平缓(绿线),因为较少的实验次数不能增强决策信心;而 100 次实验(蓝线)明显有更大的信心猜测
p更接近 0.16。 - 大数定律的体现:实验次数越大,概率密度图的均值越接近 0.16,符合大数定律。
基于上述逻辑,贝叶斯方法被引入到 A/B 测试中,用于对比两个版本实验结果的差异。
推荐阅读材料:
3. 分析特征对转化目标的正负向影响时,Shapley 值输出为何选择第二个数组?(7.2.2 节)
首先需要明确的是,无论使用什么模型和算法,对于一个具有二分类结果(例如是否转化,预测结果是 0 或 1)的特征 x,预测得到的 y 一定包含两种可能的结果(要么为 0,要么为 1)。
因此,在模型输出时,预测结果有两种表示方法:
- 概率输出:即
clf.predict_proba(x)得到的结果。它的值同时包含了结果为 0 和结果为 1 的概率,例如[0.12, 0.82]。 - 标签输出:即
clf.predict(x)得到的结果。它的值只包含 1 个最终结果(0 或 1),例如[1]。
这两种表示方法如何对应?
默认情况下,预测模型判断结果是否转化有一个基准阈值 0.5。当预测概率值 > 0.5 时,预测的 Label 就是 1;否则就是 0。在上述例子中,由于第二个值的概率为 0.82,所以结果的 Label 为 1。
如果有自定义需求,也可以调整这个阈值。例如,定义“预测为 1 的概率达到 0.9 时才认为能转化”,那么此时该结果的预测标签就是 0(不转化)。这就好比考试达到 90 分才算合格,而不是 60 分。
回到 Shapley 值的选择逻辑:
shap_value 返回的结果包含 2 个数组,这两个数组与概率预测模型相对应,分别解释了当预测为 0 以及预测为 1 的情况下,各个特征对这两个结果的影响。
在书中,我们重点研究的是**“特征是如何影响转化的”(即预测结果为 1),所以我们提取第二个数组**。
在这两组 Shapley 检验结果中,结果值是以 0 为界限对称分布的。例如,当一个特征对 x=0 时的影响结果值是 0.07821677,那么对 x=1 时的影响结果值就是 -0.07821677。在 Shapley 结果中,0 表示“没有影响”,所以当 x=0 和 x=1 的 Shapley 值相加时,结果必然为 0。
下图打印出了两组 Shapley 结果值:
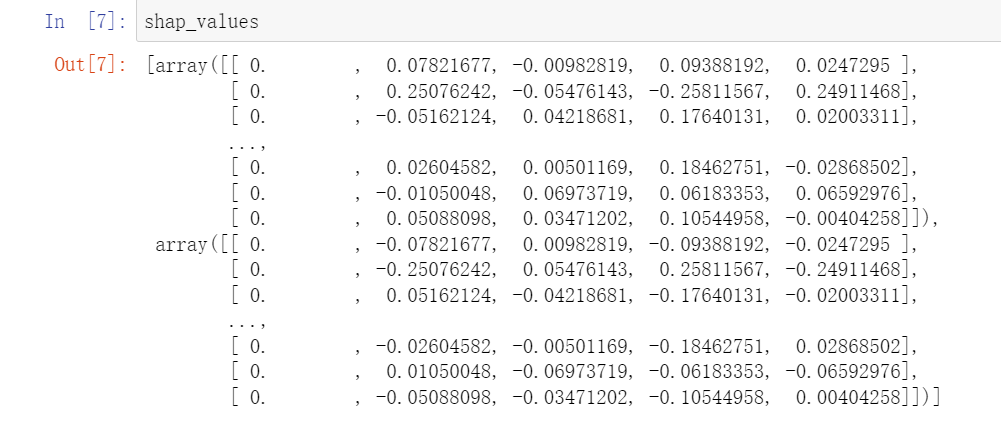
在研究 Shapley 的总体特征时,检验的是所有特征 Shapley 值的绝对值的均值。因此:
- 对于总体特征的重要性检验而言:使用第一个数组还是第二个数组,结果都是一样的。
- 对于特定预测结果的影响检验而言:要检验 Shapley 对特定结果(例如为 0 或为 1)的影响,就需要区分使用不同的数组。
进阶举例说明:
假设分类模型中有 3 个结果(例如预测用户的等级为高、中、低)。此时,我们要重点检验不同特征如何促进用户成为高价值客户,就必须选择结果数组中对应“高价值 Label”的结果值。这个值的选取与模型设置直接相关:
- 如果设置的 Label
0/1/2分别表示低、中、高转化,那么就应该取 Shapley 检验结果返回的第 3 个数组。 - 如果设置的 Label
0/1/2分别表示高、中、低转化,那么就应该取返回结果的第 1 个数组。