DBSCAN

“DBSCAN是一种基于密度的空间聚类算法,通过邻域半径和点数阈值识别核心点、边界点与噪声。其优势在于无需预设聚类数、能有效识别任意形状的簇且抗噪能力强,模型鲁棒性高。但该算法对高维数据及密度差异敏感,且在处理大规模数据集时内存与计算耗时巨大,性能远不及K-Means。文章同时提供了基于scikit-learn的Python代码实现与性能对比。”
深入理解 DBSCAN 聚类算法:原理、实现与性能分析
什么是 DBSCAN?
DBSCAN 的全称是 Density-Based Spatial Clustering of Applications with Noise,中文意为“基于密度的带有噪声的空间聚类”。
作为一个极具代表性的基于密度的聚类算法,它与传统的划分和层次聚类方法不同。DBSCAN 将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在带有噪声的空间数据库中发现任意形状的聚类。
该算法的核心在于“基于密度的聚类”概念:要求聚类空间中的一定区域内(由 Eps 定义出的半径),所包含的对象(点或其他空间对象)数目不小于某一给定阈值(由 MinPts 定义的聚类点数)。
算法优缺点分析
DBSCAN 算法的目的是基于密度寻找被低密度区域分离的高密度区域,以此来实现不同样本点的聚类。
核心优势
与传统的 K-Means 等聚类算法相比,DBSCAN 具有以下显著优点:
- 适用性更广:对原始数据集的分布没有明显要求,尤其是对非凸状、圆环形等异形簇分布的识别效果极佳。
- 无需先验知识:与 K-Means 相比,无需事先指定聚类数量,对结果的先验要求不高。
- 抗噪能力强:由于算法能够区分核心对象、边界点和噪声点,因此聚类时能够有效处理并过滤噪声点。
明显局限
由于 DBSCAN 直接对整个数据库进行操作,且在聚类时使用了一个全局性的表征密度的参数,因此也存在以下弱点:
- 高维灾难:对于高维问题,基于 Eps 和 MinPts 的密度定义会面临巨大挑战。
- 密度敏感:当数据集中各个簇的密度变化太大时,聚类结果较差。
- 资源消耗大:当数据量增大时,要求较大的内存支持,I/O 消耗也非常大。
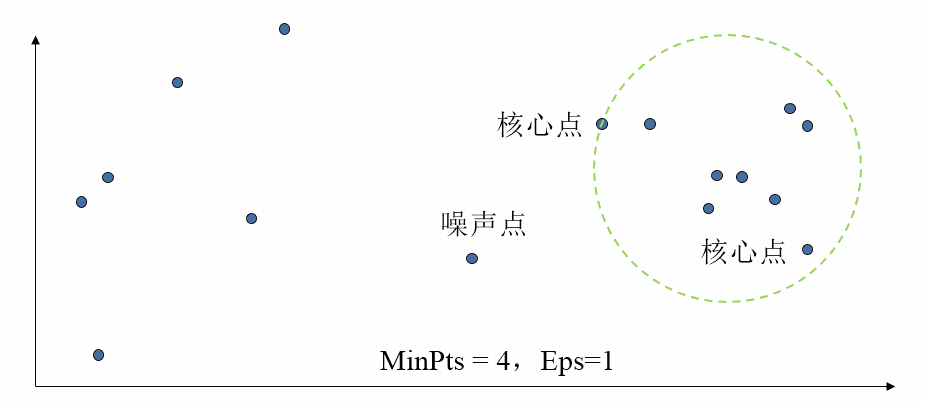
核心概念:三类样本点
基于密度的定义,DBSCAN 将空间中的所有样本点划分为以下三类:
- 核心点(稠密区域内部的点):在半径 Eps 内含有超过 MinPts 数目的点。
- 边界点(稠密区域边缘上的点):在半径 Eps 内点的数量小于 MinPts(即不是核心点),但是其邻域内包含至少一个核心点。
- 噪声或背景点(稀疏区域中的点):任何既不是核心点也不是边界点的点。
用图形表示如下:
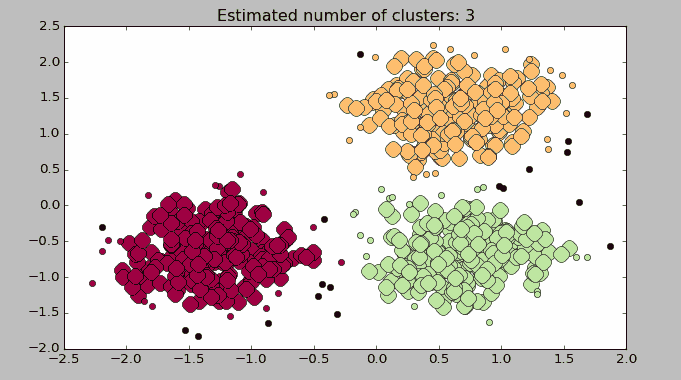
Python 实战:基于 scikit-learn 的聚类演示
以下使用 Python 机器学习库 scikit-learn 中的 DBSCAN 进行演示,目标是对随机生成的数据集进行聚类。
核心参数配置
DBSCAN 可配置的参数如下,其中最核心的是邻域半径(eps)和核心点阈值(min_samples):
python
代码实现
python
运行结果
code
典型应用场景
- 数据集聚类(如:会员画像聚类)
- 图像切割与分割
总结与性能对比
核心结论:DBSCAN 的最大优势在于它对于原始数据集的分布几乎没有要求,并且对噪声不敏感。因此,它的模型适应性和鲁棒性相对较强。
然而,它对于大数据集的处理速度表现一般。以下是分别针对 100、1000、10000、100000、1000000 样本量(类别数为 3,二维特征)进行聚类时,K-Means、MiniBatchKMeans 和 DBSCAN 三类算法的聚类耗时对比。
由于三者计算用时差异较大,因此取对数进行图形对比:
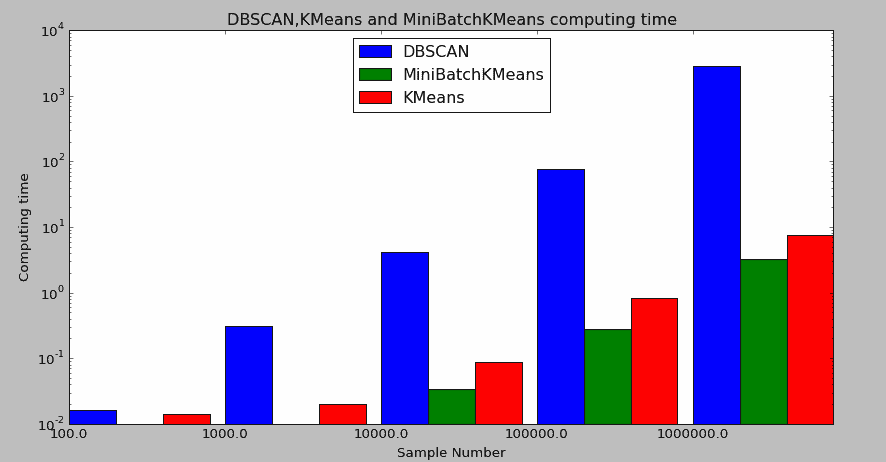
具体耗时数据如下:
code
从结果可以看出,MiniBatchKMeans 作为 K-Means 的优化版本,用时最少毫无悬念。但重点对比 K-Means 和 DBSCAN 会发现:DBSCAN 在对 100 万级数据进行聚类时,用时竟然高达 40 多分钟,这进一步印证了其在大规模数据集下 I/O 与计算消耗巨大的局限性。