使用Python从Excel获取运营数据

“Python处理Excel文件常依赖xlrd、openpyxl及Pandas等第三方库。以xlrd模块为例,通过调用相关API可高效实现工作簿读取、行列切片及单元格数据提取,但需注意中文Unicode编码与日期数值化转换现象。在企业实际场景中,Excel受限于承载量,不适用于海量数据计算,更适合作为基础数据处理或汇总结果展示的载体。”
Python 处理 Excel 文件指南:以 xlrd 模块为例
Excel 格式与 Python 处理库概览
现有的 Excel 分为两种格式:xls(Excel 97-2003)和 xlsx(Excel 2007 及以上)。
Python 处理 Excel 文件主要依赖以下第三方模块库:
xlrd、xlwt、pyexcel-xls、xlutils和pyExceleratorwin32com和openpyxl模块- 此外,Pandas 中也带有可以读取 Excel 文件的模块(
read_excel)。
使用 xlrd 模块读取 Excel 数据
基于扩展知识的目的,我们使用 xlrd 模块读取 Excel 数据。
1. 安装与准备
首先安装该库,在系统终端命令行输入以下命令:
bash
然后我们以“附件-chapter2”文件夹中的 demo.xlsx 数据文件为例,介绍该库的具体应用。数据概览如图所示:
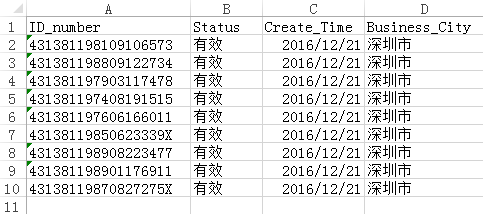
2. 代码实战
python
上述代码中,我们先读取一个 Excel 文件,再查看所有 sheet(工作簿)并输出 sheet1 相关属性信息;然后查看 sheet1 中特定数据行、列和元素的信息;最后我们用循环的方式,依次读取每个数据行并打印输出。
3. 执行结果与原理解析
以下是代码执行后打印输出的结果:
code
💡 提示与异常说明
在上述打印输出的内容中,我们发现第二列、第三列、第四列与原始数据似乎不同:
- 第二列和第四列“异常”:原因是将中文编码统一转换为了 Unicode 编码,便于在不同程序间调用。
- 第三列“异常”:是由于将日期格式转换为了数值格式而已。
进阶思考与企业应用总结
上述操作只是将数据从 Excel 中读取出来,基于读取的数据转换为数组便可以进行矩阵计算。由于矩阵计算大多是基于数值型数据实现的,因此上述数据将无法适用于大多数科学计算场景,这点需要注意。
📌 总结
在企业实际场景中,由于 Excel 本身的限制和适用性,其无法存储和计算过大(例如千万级的数据记录)的数据量,并且 Excel 本身也不是为了海量数据的应用而产生的。
因此,Excel 可以作为日常基本数据处理、补充数据来源或者汇总级别的数据进行读取;同时也可以作为数据结果展示的载体,在这种应用下,对于大量数值表格的应用效果非常好。