因子分析(Factor Analysis)

“因子分析是一种通过提取变量间隐藏共性因子来实现数据降维的统计技术。其核心优势在于利用旋转技术赋予因子极强的可解释性。与主成分分析(PCA)的线性组合不同,因子分析更侧重于发现数据内在规律。在实际应用中,它常与回归、聚类及分类模型组合使用。当数据处理需要明确的业务解释时,因子分析是优于PCA的降维首选。”
数据降维之因子分析(Factor Analysis)全面解析
在之前的文章中,我们介绍了数据降维的几种方法,包括 PCA、LDA、ICA 等,另外还有一种常用的降维方法就是因子分析。
什么是因子分析?
因子分析(Factor Analysis) 是指研究从变量群中提取共性因子的统计技术,这里的共性因子指的是不同变量之间内在的隐藏因子。
例如,一个学生的英语、数学、语文成绩都很好,那么潜在的共性因子可能是智力水平高。因此,因子分析的过程其实是寻找共性因子和个性因子并得到最优解释的过程。
因子分析的核心问题与基本步骤
因子分析有两个核心问题:一是如何构造因子变量,二是如何对因子变量进行命名解释。因子分析有下面 4 个基本步骤:
- 确定原有若干变量是否适合于因子分析。因子分析的基本逻辑是从原始变量中构造出少数几个具有代表意义的因子变量,这就要求原有变量之间要具有比较强的相关性,否则,因子分析将无法提取变量间的“共性特征”(变量间没有共性还如何提取共性?)。实际应用时,可以使用相关性矩阵进行验证,如果相关系数小于 0.3,那么变量间的共性较小,不适合使用因子分析。
- 构造因子变量。因子分析中有多种确定因子变量的方法,如基于主成分模型的主成分分析法和基于因子分析模型的主轴因子法、极大似然法、最小二乘法等。其中基于主成分模型的主成分分析法是使用最多的因子分析方法之一。
- 利用旋转使得因子变量更具有可解释性。在实际分析工作中,主要是因子分析得到因子和原变量的关系,从而对新的因子能够进行命名和解释,否则在其不具有可解释性的前提下对比 PCA 就没有明显的可解释价值。
- 计算因子变量的得分。计算因子得分是因子分析的最后一步,因子变量确定以后,对每一样本数据,希望得到它们在不同因子上的具体数据值,这些数值就是因子得分,它和原变量的得分相对应。
核心探讨:因子变量的“可解释性”
在上述因子分析中,已经阐明了因子变量的可解释性是因子分析的核心问题之一(实际上从应用角度来讲,也是比 PCA 更为有效的应用条件之一),那么什么是可解释性?我们看下面因子旋转成分矩阵。
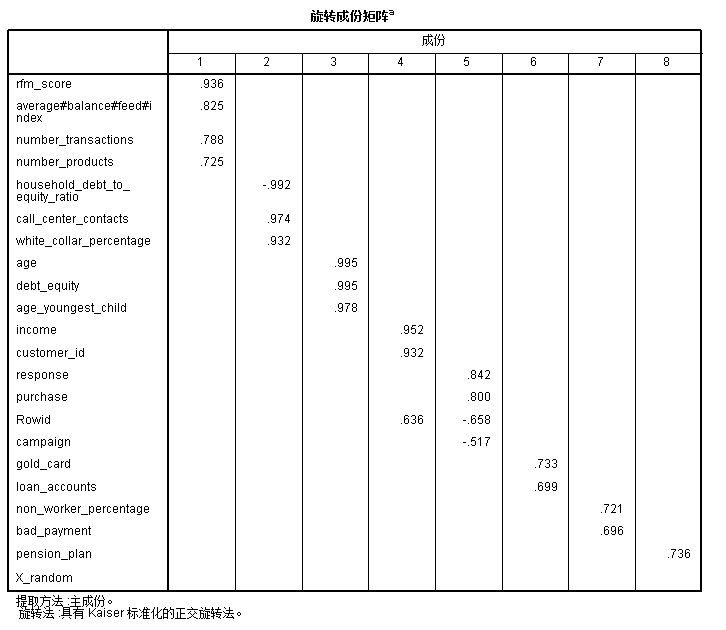
从图中可以看到从 22 个原始变量中提取了 8 个共性因子,其中每个因子对应的原始变量以及权重关系值(也就是贡献值)也都可以通过表读取出来。
例如,因子 1 是由 rfm_score、sverage#balance#feed#index、number_transactions、number_products 这四个变量共同负荷组成,这四个变量都是代表跟订单和商品转化的数量相关,因此可以得到有关“转化数量”的共性因子(当然你也可以命名为别的方式,关键是把这四个变量对于订单和转化的共同点提取出来即可)。
如果这些变量很难用一个“名字”来概括怎么办?——可以直接把几个原始变量的名字拼接到一起作为暂定的名字,等后期结合其他数据方法(例如聚类)再做进一步命名。上述的因子分析结果就是一个可以解释和命名的因子结果。
因子分析与主成分分析(PCA)的异同
因子分析经常与主成分分析(PCA)进行对比,以下是二者之间的异同点。
主要相同点
PCA 和因子分析都是数据降维的重要方法,都对原始数据进行标准化处理,都消除了原始指标的相关性对综合评价所造成的信息重复的影响;二者构造综合评价时所涉及的权数具有客观性,在原始信息损失不大的前提下,减少了后期数据挖掘和分析的工作量。
之所以大多数情况下,很难感性地区分因子分析和主成分分析,原因是二者的降维结果都是对原有维度进行一定的处理,在处理的结果上都偏离了原有基于维度的认识;但只要清楚二者的逻辑一个是基于变量的线性组合,一个是基于因子的组合便能很好地进行区分。另外,也可以从以下几个角度进行区别:工作原理、假设条件、求解方法以及降维后的特征。
主要区别
- 原理不同:主成分分析的基本原理是利用降维(线性变换)的思想,在损失很少信息的前提下把多个指标转化为几个不相关的主成分,每个主成分都是原始变量的线性组合;而因子分析基本原理是从原始变量相关矩阵内部的依赖关系出发,把因子表达成能表示成少数公共因子和仅对某一个变量有作用的特殊因子的线性组合。(因子分析是主成分的推广,相对于主成分分析,更倾向于描述原始变量之间的相关关系)
- 假设条件不同:主成分分析不需要有假设,而因子分析需要假设各个共同因子之间不相关,特殊因子(specific factor)之间也不相关,共同因子和特殊因子之间也不相关。
- 求解方法不同:主成分分析的求解方法从协方差阵出发,而因子分析的求解方法包括主成分法、主轴因子法、极大似然法、最小二乘法、a 因子提取法等。
- 降维后的“维度”数量不同:即因子数量和主成分的数量。主成分分析的数量最多等于维度数;而因子分析中的因子个数需要分析者指定(SPSS 和 SAS 根据一定的条件自动设定,只要是特征值大于 1 的因子主可进入分析),指定的因子数量不同而结果也不同。
综合来看,因子分析在实现中可以使用旋转技术,因此可以得到更好的因子解释,这一点比主成分占优势;另外,因子分析不需要舍弃原有变量,而是找到原有变量间的共性因子作为下一步应用的前提,其实就是由表及里去发现内在规律。但是,主成分分析由于不需要假设条件,并且可以最大限度地保持原有变量的大多数特征,因此适用范围更广泛,尤其是宏观的未知数据的稳定度更高。
因子分析的常见组合应用模型
因子分析跟主成分分析一样,由于侧重点都是进行数据降维,因此很少单独使用,大多数情况下都会有一些模型组合使用。例如:
- 因子分析(主成分分析)+ 多元回归分析:判断并解决共线性问题之后进行回归预测。
- 因子分析(主成分分析)+ 聚类分析:通过降维后的数据进行聚类并分析数据特点,但因子分析会更适合,原因是基于因子的聚类结果更容易解释,而基于主成分的聚类结果很难解释。
- 因子分析(主成分分析)+ 分类:数据降维(或数据压缩)后进行分类预测,这也是常用的组合方法。
Python 实战:使用 scikit-learn 进行因子分析
下面使用 Python 的机器学习库 scikit-learn 中的 FactorAnalysis 进行降维。
python
以下是程序运行结果:
code
结果中,我们先是利用一个类似于 table 的模块输出了整个数据集的特征:4177 个样本量、9 个维度以及各个维度的名称;然后指定了 3 个因子作为降维后的新“变量”。实际测试时可以通过修改上述参数中的 n_components 值来指定不同的因子个数,不同因子个数下输出的因子的结果是不同的。
FactorAnalysis 可配置的参数如下:
python
总结
主成分分析和因子分析是数据降维过程中使用频率相对较高的两类降维方法。具体使用时,如果后续数据挖掘或处理过程需要解释或者通过原始变量的意义去应用,那么选择因子分析更合适;否则主成分分析的使用场景更广泛。但我们发现,其实主成分分析可以看作是因子分析的一个特例,而且主成分分析也可以作为因子分析的一种方法。